版权申明:转载请注明出处。
文章来源:大数据随笔
1.数据分块
HDFS作为Hadoop中的一个分布式文件系统,而且是专门为它的 MapReduce设计,所以HDFS除了必须满足自己作为分布式文件系统的高可靠性外,还必须为MapReduce提供高效的读写性能,那么HDFS是 如何做到这些的呢?首先,HDFS将每一个文件的数据进行分块存储,同时每一个数据块又保存有多个副本,这些数据块副本分布在不同的机器节点上,这种数据 分块存储+副本的策略是HDFS保证可靠性和性能的关键,这是因为:一.文件分块存储之后按照数据块来读,提高了文件随机读的效率和并发读的效率;二.保 存数据块若干副本到不同的机器节点实现可靠性的同时也提高了同一数据块的并发读效率;三.数据分块是非常切合MapReduce中任务切分的思想。在这 里,副本的存放策略又是HDFS实现高可靠性和搞性能的关键。
2.机架感知
HDFS采用一种称为机架感知的策略来改进数据的可靠性、可用性和网络带宽的利用率。通过一个机架感知的过程,NameNode可以确定每一个 DataNode所属的机架id(这也是NameNode采用NetworkTopology数据结构来存储数据节点的原因)。一个简单但没有优化的策略就是将副本存放在不同的机架上,这样可以防止当整个机架失效时数据的丢失,并且允许读数据的时候充分利用多个机架的带 宽。这种策略设置可以将副本均匀分布在集群中,有利于当组件失效的情况下的均匀负载,但是,因为这种策略的一个写操作需要传输到多个机架,这增加了写的代 价。
在大多数情况下,副本系数是3,HDFS的存放策略是将一个副本存放在本地机架节点上,一个副本存放在同一个机架的另一个节点上,后一个副本放在不同机 架的节点上。这种策略减少了机架间的数据传输,提高了写操作的效率。机架的错误远远比节点的错误少,所以这种策略不会影响到数据的可靠性和可用性。与此同 时,因为数据块只存放在两个不同的机架上,所以此策略减少了读取数据时需要的网络传输总带宽。在这种策略下,副本并不是均匀的分布在不同的机架上:三分之 一的副本在一个节点上,三分之二的副本在一个机架上,其它副本均匀分布在剩下的机架中,这种策略在不损害数据可靠性和读取性能的情况下改进了写的性能。下 面就来看看HDFS是如何来具体实现这一策略的。
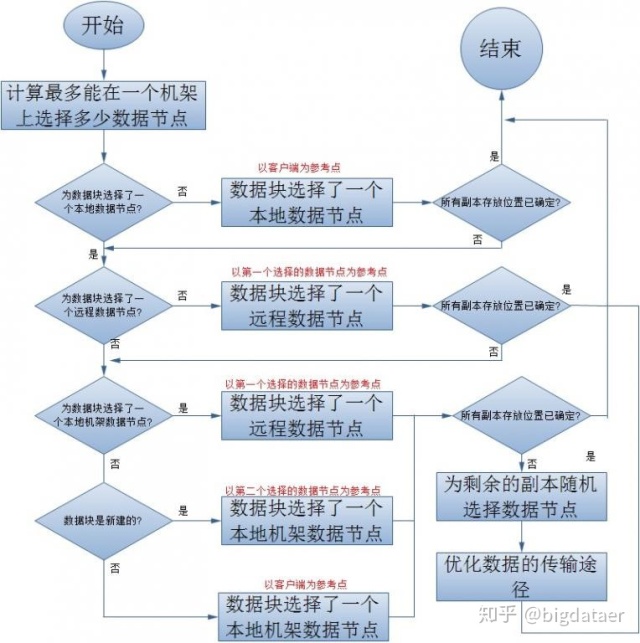
3.配置
若不配置机架感知,namenode打印的日志如下:
2016-07-17 17:27:26,423 INFO org.apache.hadoop.net.NetworkTopology: Adding a new node: /default-rack/ 192.168.147.92:50010
每个IP对应的的机架ID是/default-rack。启用机架感知需要配置文件core-site.xml,配置项如下:
<property>
<name>topology.script.file.name</name>
<value>/etc/hadoop/topology.sh</value>
</property>
value是一个shell脚本,主要的功能是输入DataNode的IP返回对应的机架ID。namenode启动时会判断是否启用了机架感知,若启用则会根据配置查找配置脚本,并在收到DataNode的心跳时传入其IP获取机架的ID存入内存中的一个map中。一个简单的配置脚本如下:
#!/bin/bash
HADOOP_CONF=etc/hadoop/config
while [ $# -gt 0 ] ; do
nodeArg=$1
exec<${HADOOP_CONF}/topology.data
result=""
while read line ; do
ar=( $line )
if [ "${ar[0]}" = "$nodeArg" ]||[ "${ar[1]}" = "$nodeArg" ]; then
result="${ar[2]}"
fi
done
shift
if [ -z "$result" ] ; then
echo -n "/default-rack"
else
echo -n "$result"
fi
done
其中topology.data的格式如下:
topology.data,格式为:节点(ip或主机名) /交换机xx/机架xx
192.168.147.91 tbe192168147091 /dc1/rack1
192.168.147.92 tbe192168147092 /dc1/rack1
192.168.147.93 tbe192168147093 /dc1/rack2
192.168.147.94 tbe192168147094 /dc1/rack3
192.168.147.95 tbe192168147095 /dc1/rack3
192.168.147.96 tbe192168147096 /dc1/rack3
可以使用./hadoop dfsadmin -printTopology查看机架配置信息。
4.动态添加节点
如何在集群中不重启namenode来动态的添加一个DataNode节点?在启用了机架感知的集群中可以这样操作:
假设Hadoop集群在192.168.147.68上部署了NameNode和DataNode,启用了机架感知,执行bin/hadoop dfsadmin -printTopology看到的结果:
Rack: /dc1/rack1
192.168.147.68:50010 (dbj68)
现在想增加一个物理位置在rack2的数据节点192.168.147.69到集群中,不重启NameNode。
首先,修改NameNode节点的topology.data的配置,加入:192.168.147.69 dbj69 /dc1/rack2,保存。
192.168.147.68 dbj68 /dc1/rack1
192.168.147.69 dbj69 /dc1/rack2
然后,sbin/hadoop-daemons.sh start datanode启动数据节点dbj69,任意节点执行bin/hadoop dfsadmin -printTopology 看到的结果:
Rack: /dc1/rack1
192.168.147.68:50010 (dbj68)
Rack: /dc1/rack2
192.168.147.69:50010 (dbj69)
说明hadoop已经感知到了新加入的节点dbj69,如果不将dbj69的配置加入到topology.data中,执行sbin/hadoop-daemons.sh start datanode启动数据节点dbj69,datanode日志中会有异常发生,导致dbj69启动不成功。
