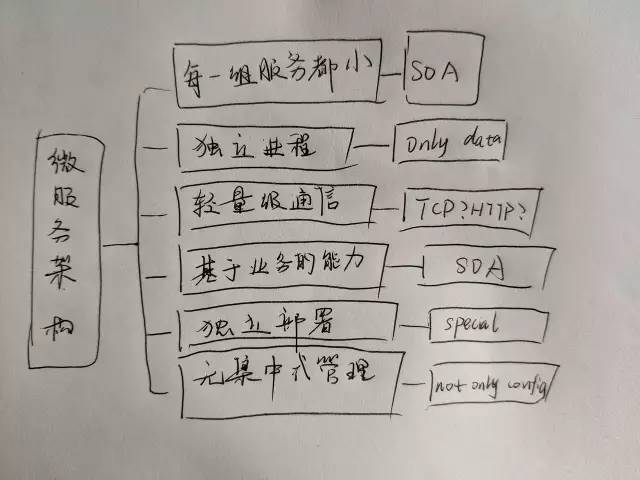
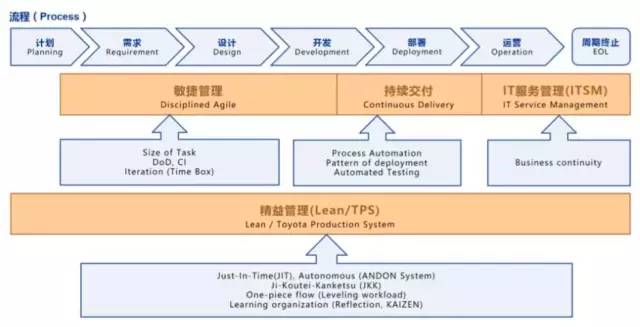
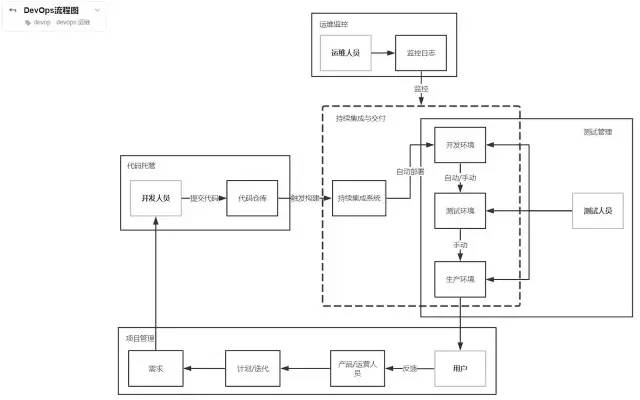
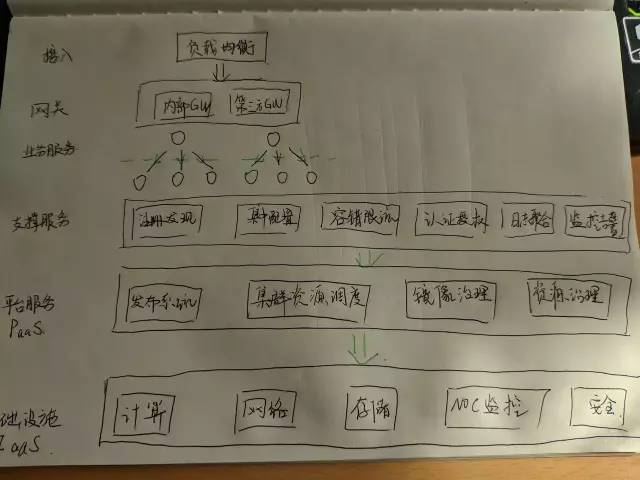
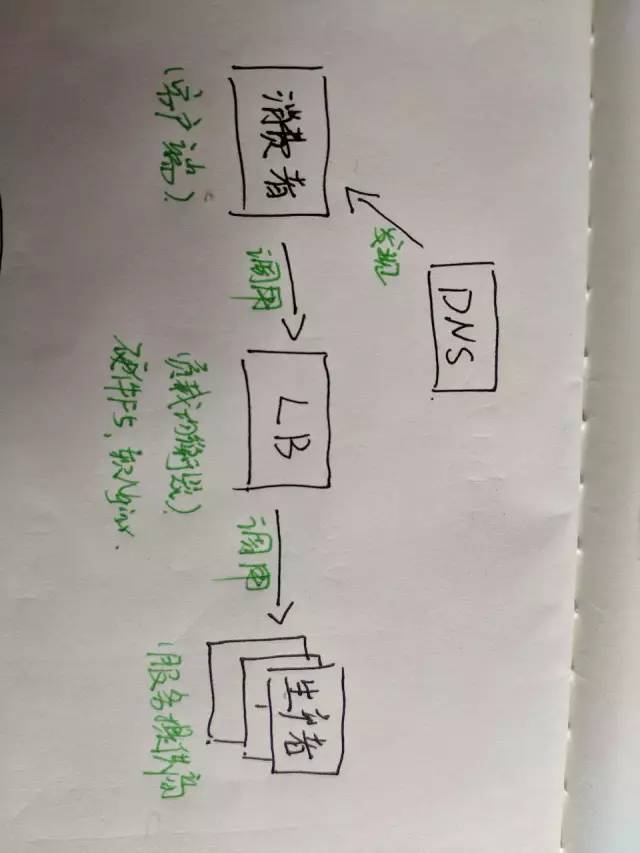
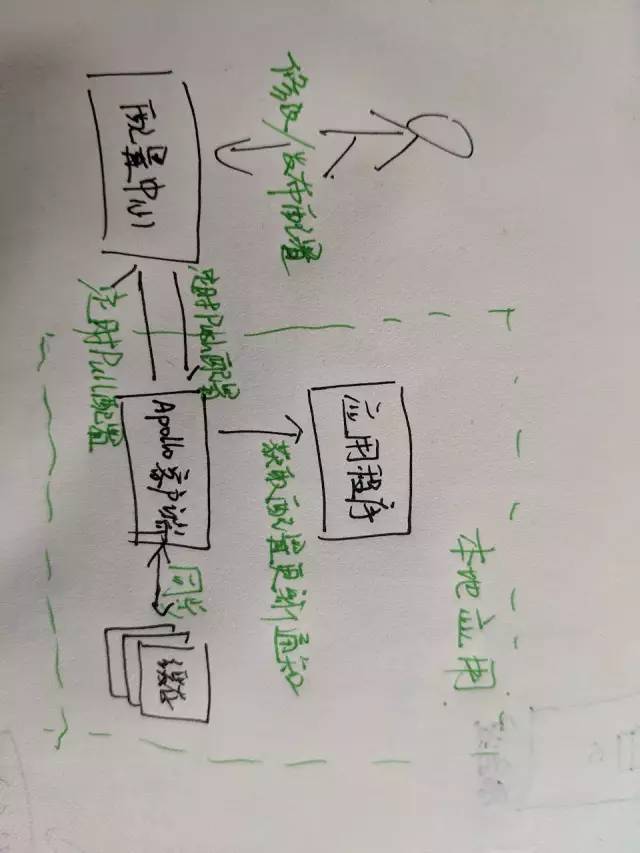
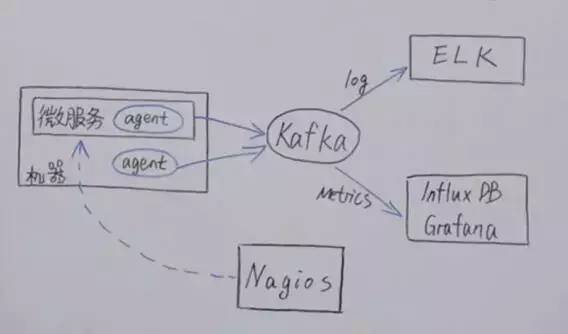
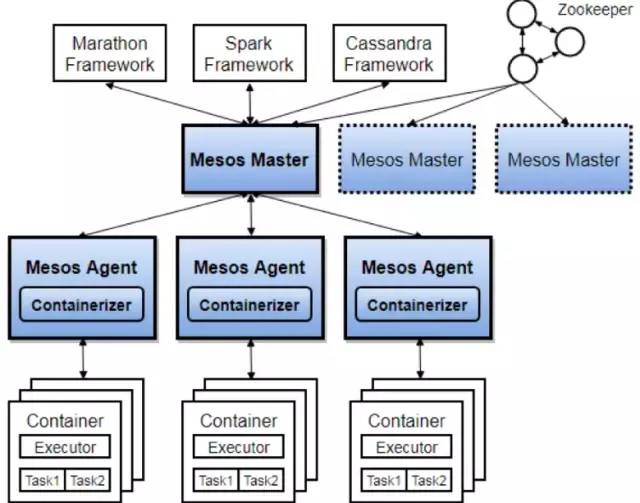
就目前而言,对于微服务业界并没有一个统一的、标准的定义(While there is no precise definition of this architectural style ) 。但通在其常而言,微服务架构是一种架构模式或者说是一种架构风格,它提倡将单一应用程序划分成一组小的服务,每个服务运行独立的自己的进程中,服务之间互相协调、互相配合,为用户提供终价值。服务之间采用轻量级的通信机制互相沟通(通常是基于 HTTP 的 RESTful API ) 。每个服务都围绕着具体业务进行构建,并且能够被独立地部署到生产环境、类生产环境等。另外,应尽量避免统一的、集中式的服务管理机制,对具体的一个服务而言,应根据业务上下文,选择合适的语言、工具对其进行构建,可以有一个非常轻量级的集中式管理来协调这些服务。可以使用不同的语言来编写服务,也可以使用不同的数据存储。
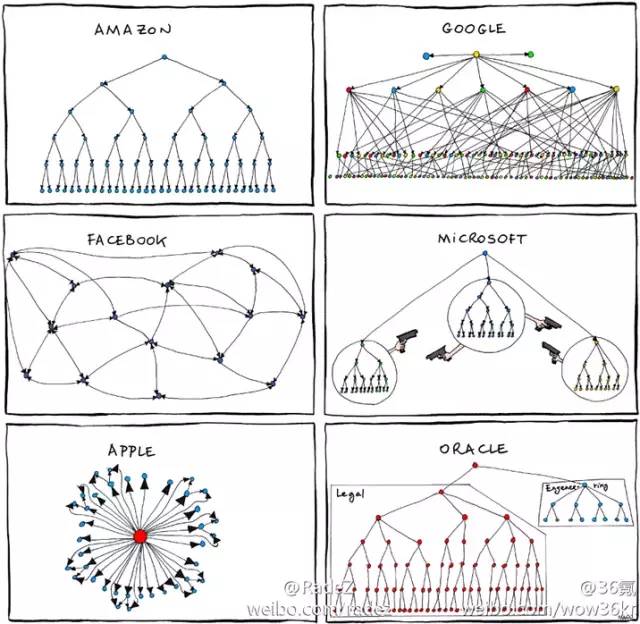
Organizations which design systems are constrained to produce designs which are copies of the communication structures of these organizations. - Melvin Conway(1967)
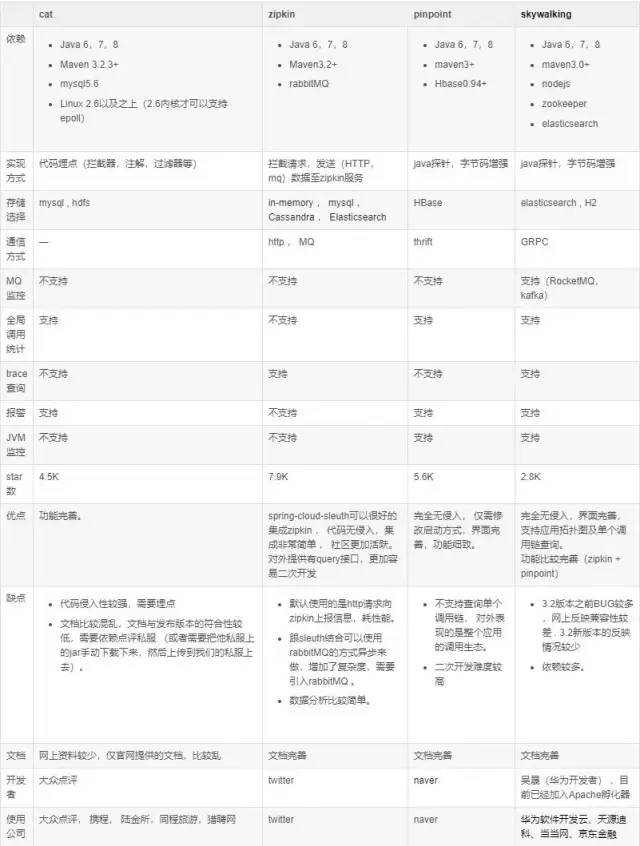
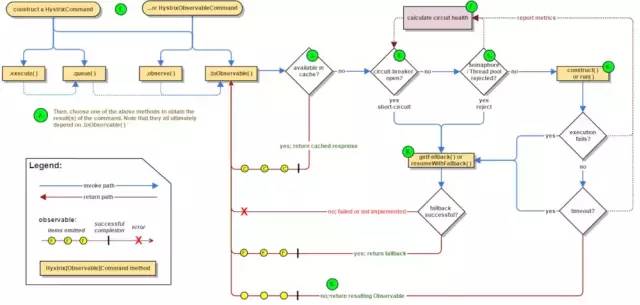
很多公司都有调用链监控,就譬如阿里有鹰眼监控,点评的Cat,大部分调用链监控(没错,我指的Zipkin)架构是这样的👇 当请求进入Web容器的时候,会经过创建Tracer,连接spans(模拟潜在的分布式工作的延迟,该模块还包含在系统网络间传递跟踪上下文信息的工具包,如通过http headers)。Spans有一个上下文,其中包含tracer标识符,将其放在表示分布式操作的树的正确位置。当我们把图中的各种span放到后端的时候,我们的服务调用链会动态的生成调用链。 下面是一些市场上用的比较多的调用链监控: 1、Pinpointgithub地址:GitHub - naver/pinpoint: Pinpoint is an open source APM (Application Performance Management) tool for large-scale distributed systems written in Java.对java领域的性能分析有兴趣的朋友都应该看看这个开源项目,这个是一个韩国团队开源出来的,通过JavaAgent的机制来做字节码代码植入,实现加入traceid和抓取性能数据的目的。NewRelic、Oneapm之类的工具在java平台上的性能分析也是类似的机制。 2、SkyWalkinggithub地址:wu-sheng/sky-walking这是国内一位叫吴晟的兄弟开源的,也是一个对JAVA分布式应用程序集群的业务运行情况进行追踪、告警和分析的系统,在github上也有400多颗星了。功能相对pinpoint还是稍弱一些,插件还没那么丰富,不过也很难得了。 3、Zipkin官网:OpenZipkin · A distributed tracing systemgithub地址:GitHub - openzipkin/zipkin: Zipkin is a distributed tracing system这个是twitter开源出来的,也是参考Dapper的体系来做的。 Zipkin的java应用端是通过一个叫Brave的组件来实现对应用内部的性能分析数据采集。Brave的github地址:github.com/openzipkin/…这个组件通过实现一系列的java拦截器,来做到对http/servlet请求、数据库访问的调用过程跟踪。然后通过在spring之类的配置文件里加入这些拦截器,完成对java应用的性能数据采集。 4、CATgithub地址:GitHub - dianping/cat: Central Application Tracking这个是大众点评开源出来的,实现的功能也还是蛮丰富的,国内也有一些公司在用了。不过他实现跟踪的手段,是要在代码里硬编码写一些“埋点”,也就是侵入式的。这样做有利有弊,好处是可以在自己需要的地方加埋点,比较有针对性;坏处是必须改动现有系统,很多开发团队不愿意。 5、Xhprof/Xhgui这两个工具的组合,是针对PHP应用提供APM能力的工具,也是非侵入式的。Xhprof github地址:GitHub - preinheimer/xhprof: XHGUI is a GUI for the XHProf PHP extension, using a database backend, and pretty graphs to make it easy to use and interpret.Xhgui github地址:GitHub - perftools/xhgui: A graphical interface for XHProf data built on MongoDB我对PHP不熟,不过网上介绍这两个工具的资料还是蛮多的。 熔断、隔离、限流、降级 面对巨大的突发流量下,大型公司一般会采用一系列的熔断(系统自动将服务关闭防止让出现的问题大化)、隔离(将服务和服务隔离,防止一个服务挂了其他服务不能访问)、限流(单位时间内之允许一定数量用户访问)、降级(当整个微服务架构整体的负载超出了预设的上限阈值或即将到来的流量预计将会超过预设的阈值时,为了保证重要或基本的服务能正常运行,我们可以将一些 不重要或 不紧急 的服务或任务进行服务的 延迟使用 或 暂停使用)措施。 下面介绍一下hystrix的运行流程(没找到架构图不好意思): 每一个微服务调用时,都会使用hystrix的command方式(上图的左上角那个),然后使用command同步的,或者是响应式的,或者是异步的,判断电路是否熔断(顺着图从左往右看), 如果断路则走降级fallback; 如果这个线闭合着,但是线程资源没了,队列满了,则走限流措施(看图的第5步); 如果走完了,执行成功了,则走run()方法,获取response,但是这个过程如果出错了,则继续走降级fallback. 同时,看图上面有一个后缀是health的,这是一个计算整个链路是否健康的组件,每一步操作都被它记录着。