
本期论文:Resilient Distributed Datasets: A Fault-Tolerant Abstraction for In-Memory Cluster Computing
背景
在 Spark 广泛使用以前,业界主要使用 MapReduce 来对海量数据进行分布式处理。但随着需求的不断扩展,MapReduce 也存在着这样那样的局限:
- 抽象层次低,需要写很多底层的代码,不够高效
- MapReduce 编程模型的表达能力有限,所有的事情必须要转化成 Map 和 Reduce 两个操作,而仅靠 MapReduce 难以满足所有需求
- 时延高,只适用批数据处理,对于交互式数据处理和实时数据处理的支持不够
- 任务的执行需要多次读写分布式文件系统,无法利用分布式内存资源,难以满足复用中间结果的计算需要,对于迭代式数据处理性能比较差,包括:
- 迭代式机器学习算法及图算法
- 交互式数据挖掘
RDD 作为一个分布式内存资源抽象致力于解决 MapReduce 的上述问题:
- 通过对分布式集群的内存资源进行抽象,允许程序高效复用已有的中间结果
- 可以表达更多的编程模型,兼容更多的算法
RDD:分布式内存资源抽象
RDD(Resilient Distributed Dataset,弹性分布式数据集)本质上是一种只读、分区的记录集合,是一个高效、通用、容错的抽象。
- 通用:可以表达广泛的编程模型、算法和并行应用
- 容错:提供基于粗粒度转换的 API,可使用 lineage 高效恢复数据,不需要数据备份
- 高效:在实现 RDD 的 Spark 计算框架上,处理迭代式应用比 Hadoop 快20多倍,还能交互式查询上百G的数据
RDD 只能通过 Transformation 操作由数据源或其他 RDD 来生成。除了 Transformation 以外,RDD 通过 Action 操作对 RDD 进行计算并把结果返回给客户端,或是将 RDD 里的数据写到外部存储。

Transformation 与 Action 的区别还在于,对 RDD 进行 Transformation 操作并不会触发计算,只有在用户进行 Action 操作时,Spark 才会调度 RDD 计算任务,依次为各个 RDD 计算数据。
通过由用户构建 RDD 时产生的 DAG 图,每个 RDD 都能得出自己是如何由持久化存储中的源数据计算得到的,被称为 RDD 的血统(Lineage)。此外,用户可以使用 persist 方法选择需要复用的 RDD,Spark 会将其存储在内存中,如果内存空间不足,将会写到硬盘上。用户还可以为其选择存储策略,也可以基于每个记录的 key 将 RDD 在多个机器上分区存储。
RDD 不适用于异步更新或增量更新的应用。
一个简单的小例子:

- rdd1:从 HDFS 创建的 RDD
- Spark 默认一个 block 对应一个分区,也可通过 textFile 第二个参数 minPatitions 指定更多的分区,但分区的数量不能比 block 数量少,即文件终分区数 >= 文件 block 数
- rdd2:从 rdd1 衍生除一个经过条件过滤后的 RDD
- filter 是 RDD Transformation 操作,即每个分区需要计算的函数
- rdd1 是 rdd2 的父节点,即 rdd2 依赖 rdd1
另一个小例子:

RDD 的优点
- RDD 提供了一种粗粒度(coarse-grained)转换的API,对每一个数据项应用相同的操作。使用日志记录数据集是如何产生的而不是去记录数据本身,使得容错变得高效。一旦某个 partition 丢失,通过日志可以找出该 partition 是如何通过其他的 RDD 经过什么操作得到的,通过重新计算即可进行恢复,不需要数据的复制,也不需要任何回滚操作。
- 可以使用 MapReduce 中的备份任务机制来缓解落后者(Straggler)。
RDD 具体实现
一个RDD由以下几个部分组成:
- 一组分区(partition):数据集的基本组成单位(按 key 划分)
- 一个计算每个分区的函数:对于给定的数据集所需要进行的计算
- 一组依赖:描述了 RDD 之间的 lineage
- 元数据:描述该 RDD 所包含数据的模式、分区方式、存储位置偏好等信息
RDD 间的依赖关系可以被分为两种:
- 窄依赖关系:一个父 RDD 的 partition 至多被子 RDD 的某个 partition 使用一次;窄依赖的函数包括 map、filter、union、join(父 RDD 是 hash-partitioned)等
- 宽依赖关系:一个父 RDD 的 partition 被子 RDD 的 partition 使用多次;宽依赖的函数包括 groupByKey、join(父 RDD 不是 hash-partitiond)等
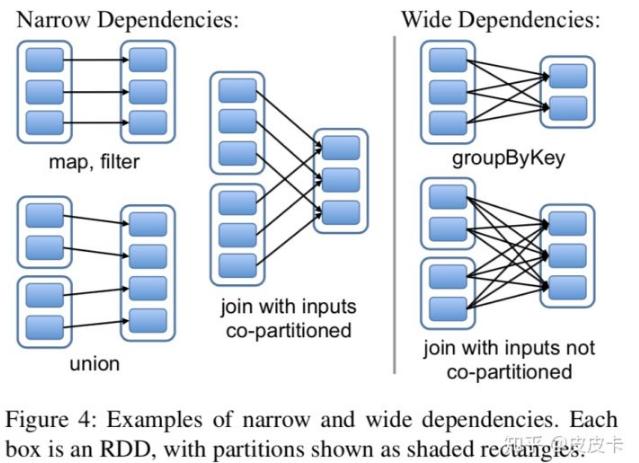
这样区分的原因有两个。首先,窄依赖使得位于该依赖链上的 RDD 计算操作可以被安排到同一个集群节点上流水线进行;而宽依赖使得 RDD 计算操作需要等待所有父 RDD 都可用,还需要进行 shuffle 操作。对于宽依赖之间的 Shuffle,Spark 采取与 MapReduce 相同的策略,会把中间结果持久化(checkpoint)到节点的本地存储中,以简化失效恢复,避免因为较长的 lineage 导致恢复需要耗费大量时间。其次,在节点失效需要恢复 RDD 时,窄依赖恢复效率更高,因为只需要将父 RDD 中的对应分区重新计算即可,还能将恢复任务调度到不同的节点上并行进行;而宽依赖使得单个故障节点可能会导致 RDD 的所有祖先丢失分区,从而需要完全重新执行。
RDD 作业调度
Spark 根据 DAG 图划分 Stage。划分 Stage 的方法是在 DAG中进行反向解析,遇到宽依赖断开,遇到窄依赖就将当前 RDD 加入到 Stage 中;将窄依赖尽量划分到同一个 Stage 中,以实现流水线计算,而宽依赖之间的 RDD 需要进行 Shuffle 操作。
下图中,RDD A 是 B 的宽依赖,所以 A 和 B 划分在不同的 Stage;RDD C,D,F 从 map 到 union 都是窄依赖,保留在一个 Stage,这两步操作可以形成一个流水线操作,通过 map操作生成的 partition 可以不用等待整个 RDD 计算结束,而是继续进行 union 操作,以提高计算效率。

Job Stage 划分完毕后,Spark 便会为每个 Partition 生成计算任务(Task)并调度到集群节点上运行。Spark 会基于 Partition 的位置分配任务。例如,如果 RDD 是从 HDFS 中读出数据,那么 Partition 的计算就会分配到持有对应 HDFS Block 的节点上;如果父 partition 在内存中,子 Partition 的计算也会分配到持有对应父 Partition 的节点上。
当 Task 所在的节点失效时,如果该 Task 所属 Stage 的父 Stage 数据仍可用,Spark 只要将该 Task 调度到其他节点上重新运行即可。如果父 Stage 的数据不可用,那么 Spark 就会重新提交一个计算父 Stage 数据的 Task,以完成恢复。
RDD 的存储
Spark 提供三种存储 RDD 的方式:
- 以序列化对象存储在内存:性能强,Java VM 可以直接访问 RDD
- 以序列化数据存储在内存:性能次之,当内存不足时,可以更有效的保存数据
- 存储在硬盘。性能差,对于数据量特别大时较为适用
在内存有限的情况下,使用 LRU 策略管理 RDD,当计算得到一个新的 Partition 但内存不足时,就会将近一直没有使用的 RDD 的一个 Partition 存储到硬盘,然后释放其内存供新的 Partition 使用,如果新旧 Partition 相同则舍弃新的 Partition,以避免相同的 RDD 频繁的入和出。此外,还可以为 RDD 设置 persistence priority 来进一步管理 RDD。
性能评估
- Spark 执行迭代式机器学习算法和图算法比 Hadoop 快20多倍
- Spark 分析报表比 Hadoop 快40多倍
- 节点失效时,通过 lineage 重新计算丢失的RDD Partitions,Spark 能够实现快速恢复
- Spark 能够在5-7s时延内,交互式地查询 1TB 大小的数据集
参考文献
[1] Zaharia M, Chowdhury M, Das T, et al. Resilient distributed datasets: A fault-tolerant abstraction for in-memory cluster computing[C]. Usenix Conference on Networked Systems Design & Implementation. 2012: 15-28.
