假设有一个需求是这样的:在200亿个随机整数中找出某个数是否存在其中?要求效率高,而且要节省内存。
我们知道,在Java中,int占4字节,1字节=8 byte,1 byte = 8 bit(位)
如果用int存储,那就是200亿个int,因而占用的空间约为
(20000000000*4/1024/1024/1024)≈74.5G。
内存消耗很大,一般的家用电脑是满足不了需求的,所以将数据存储在内存中存储是不合适的。
如果按位存储就不一样了,200亿个数就是200亿位,占用空间约为
(2000000000/8/1024/1024/1024)≈2.33G,节省了30倍的空间。
实际上这就是Bitmap的思想。Bitmap的基本思想是用一个bit位来标记某个元素对应的Value,而Key即是该元素本身。采用bit存储数据,可以大大节省存储空间。
Bitmap是什么?如何在bitmap中表示一个数呢?
我们知道计算机底层存储的都是二进制数据,二进制数只有0和1。bitmap每一位的值也只能是0或1,0表示不存在,1表示存在。
这样我们可以很容易表示{1,2,4,6}这几个数:

计算机内存分配的小单位是字节,也就是8位,那如果要表示{12,13,15}怎么办呢?
当然是在另一个8位上表示:
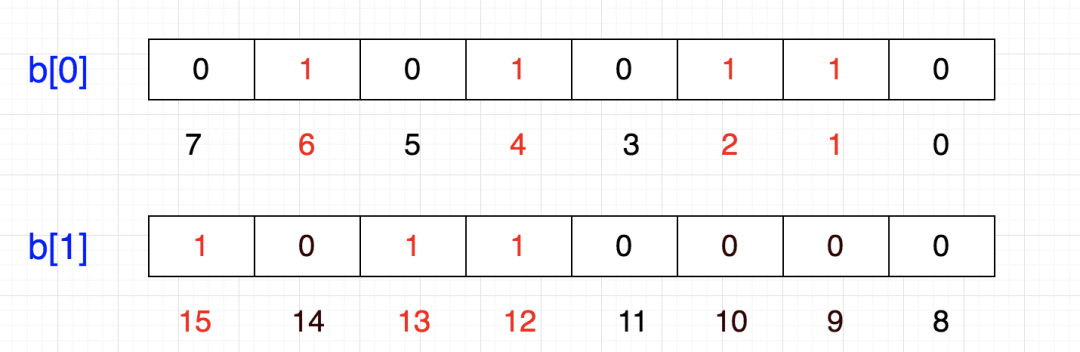
这样的话,好像变成一个二维数组了
1个int占32位,那么我们只需要申请一个int数组长度为 int tmp[1+N/32] 即可存储,其中N表示要存储的这些数中的大值,于是:
tmp[0]:可以表示0~31
tmp[1]:可以表示32~63
tmp[2]:可以表示64~95
。。。
于是,对于任意整数M,M/32可以得到下标,M%32就可以得到它在此下标的哪个位置。
那么,怎么把一个数放进Bitmap呢?比如想把5这个数字放进去
插入一个数
首先,5/32=0,5%32=5,也是说它应该在b[0]的第5个位置。我们可以把1向左移动5位,然后和b[0]按位或即可。
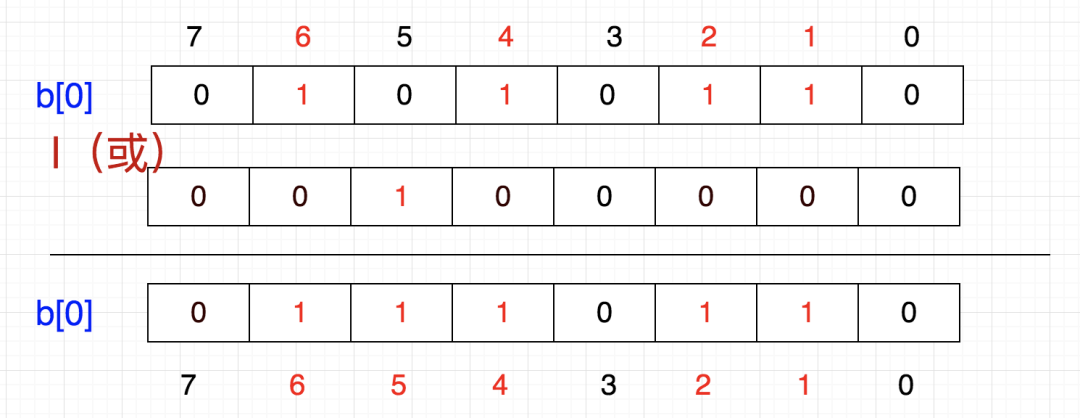
二进制就是:

这就相当于 86 | 32 = 118,即 86 | (1<<5) = 118,也就是 b[0] = b
[0] | (1<<5)。也就是说,要想插入一个数,将1左移相应的位数,然后与原数进行按位或操作即可。
删除一个数
还是上面的例子,假设删除数字6,该怎么做呢?
只需将该数所在的位置为0即可。即1左移6位,就到达6这个数字所代表的位,然后按位取反,后与原数按位与,这样就把该位置为0了

公式如下:
b[0] = b[0] & (~(1<<6))
b[0] = b[0] & (~(1<<(i%8)))
查找一个数
前面已经提到,1表示存在,0表示不存在。通过把该位置为1或者0来达到添加和清除的效果,那么判断一个数存不存在就是判断该数所在的位是0还是1。比如,我们想知道6在不在,那么只需要判断 b[0] & (1<<6), 如果这个值是0,则不存在,如果是1,就表示存在。
BitMap在统计系统里边能做什么?
例子 1:针对独立用户的统计。比如想知道某个应用,每天有多少个独立用户使用了该应用?可以根据该应用的用户访问日志,每天生成一个BitMap;每个用户对应BitMap里的一个位置,如果当天访问了,该位置就置为1,否则为0。这样要知道当天这个应用的总独立用户数,只需要看看那天的BitMap里边有多少个1。
对于10M(1000万)用户的应用,每天需要的BitMap大小为10M/8=1.25MB,即只需要1.25兆字节。在采用一些压缩技术的基础上,可以进一步缩减需要的存储量,一般情况下可能只需要大约100-200KB的存储即可。
例子2:用户回访的统计。比如想知道某个应用,昨天使用过的用户中,有多少今天也使用了?可以在例子1(每天保存一个独立活跃用户的BitMap)的基础上,将昨天的BitMap和今天的BitMap进行AND操作,然后数一下生成的BitMap里有多少个1即可。
怎么将用户映射到BitMap里边的某个位置?
使用BitMap的时候,都需要将原始数据(比如用户)映射到BitMap里的位置;这种映射一般可以采用外部数据(比如在数据库里保存用户到BitMap位置的映射),或者采用固定的规则(比如计算用户名的hash code)。
采用种方法时,通常是在数据库里边给用户分配一个数值型的用户ID,而用户ID的生成规则采用自增量的方式来产生;这样比如有100个用户,则其用户ID为1,2,3,…,98,99,100;用户ID为1的用户映射到BitMap里的第1个位置,用户ID为2的用户映射到BitMap里的第2个位置…(问题:如果自增量的初始值不是0,而是比如10000,会产生什么影响?)
采用自增量的另外一个好处是,系统用户数少的时候,BitMap需要的位数也少;当用户量增长时,BitMap的位数跟着增长即可;而且如果记住每天的总用户数,BitMap里边还可以直接表明每天的新增用户是哪些(注意:此处对于我们的分析系统不一定适用)
采用第二种方法时,常使用的规则是计算用户的hash(比如Object.hashCode,或者MD5);但由于hash生成的数字分布很宽(比如java里边Object的hashCode会返回一个int,所以其分布是-231 – 231-1),但需要的BitMap的位数往往不用那么大,这样就需要再做一个hashcode到BitMap里位置的映射(一般是取余数),这就要求必须预先知道BitMap的大小,且这个大小一般要求保持不变。
比如要求将用户映射到一个1024位的BitMap:用户A的hashcode是101,101除1024取余数是101,所以用户A就对应BitMap的第101位;而用户B的hashcode是1234567,1234567除1024取余数是647,用户B就对应BitMap的第647位。
第二种方法由于采用固定的规则来计算映射,而不需要去做外部数据查询,因此映射这部分的开销会较种方法低很多。但第二种方法也有两个缺点,其一是如果预期总用户量会增长到1百万,即使目前系统只有1000个用户,也需要一个1百万位的BitMap,这样会造成很大的存储和计算资源的浪费;其二是hashcode有冲突的问题(即有可能用户C和用户D计算出来的hashcode是一样的);
而hashcode到BitMap里位置的映射也会造成更多的冲突(比如用户E和用户F的hashcode分别是12345678和12377422,但除1024取余后都是334)。这些冲突的存在,导致了数据可信度的下降,比如BitMap里的第334位为0,则可以知道用户E和F都不在;但如果第334位为1,则并不知道用户E或者用户F是不是在。
采用第二种方法的BitMap,有一个更广为人知的名字,即Bloom Filter (http://en.wikipedia.org/wiki/Bloom_filter)。Bloom Filter经常用于文本分析中来记录某个词是否已经出现;或者垃圾邮件过滤中来检查邮件地址是否在已知的垃圾邮件地址列表里。
Bloom filter(布隆过滤器)
来了解一下Bloom filter, Bloom filter是一个数据结构,它可以用来判断某个元素是否在集合内,具有运行快速,内存占用小的特点。插入和查询效率都很高。Bloom Filter 是一个基于概率的数据结构:它只能确定一个元素不在集合内,不能确定一定在集合内。
Bloom filter 的基础数据结构是比特向量,可理解为数组。
主要应用于大规模数据下不需要过滤的场景,如检查垃圾邮件地址,爬虫URL地址去重,解决缓存穿透问题等
如果想判断一个元素是否在集合里,一般想到的是将集合中所有元素保存起来,然后通过比较确定。链表、树、散列表等数据结构都是这种思路,但是随着集合中元素的增加,需要的存储空间越来越大;同时检索速度也越来越慢,检索时间复杂度分别是O(n)、O(log n)、O(1)。
布隆过滤器的原理是,当一个元素被加入集合时,通过 K 个散列(hash)函数将这个元素映射成一个位数组(Bit array)中的 K 个点,把它们置为 1 。检索时,只要看看这些点是不是都是1就知道元素是否在集合中;如果这些点有任何一个 0,则被检元素一定不在;如果都是1,则被检元素很可能在。之所以说“可能”,是因为可能有hash冲突的问题。
BloomFilter 流程:
首先需要 k 个 hash 函数,每个函数可以把 key 散列成为 1 个整数;
初始化时,需要一个长度为 n 比特的数组,每个比特位初始化为 0;
某个 key 加入集合时,用 k 个 hash 函数计算出 k 个散列值,并把数组中所有对应的比特位置为 1;
判断某个 key 是否在集合时,用 k 个 hash 函数计算出 k 个散列值,并查询数组中对应的比特位,如果所有的比特位都是1,则key很可能在集合中。如果其中任意一个比特位为0,则确定key不在集合中。

由此可见,如果我们能灵活运行二进制,确实能给系统带来不少好处。所有的程序和指令在执行前都会被转化成0和1,所以我们用二进制的0和1直接和计算机交互效率是高的,而且能大幅节省空间。所以大家一定要关心计算机基础啊,基础扎实了,我们的技术能力才能上新的台阶。
作者简介:冯涛,曾任职于阿里巴巴,每日优鲜等互联网公司,任技术总监,15年电商互联网经历。
原文链接:https://mp.weixin.qq.com/s/OQZcc7g1lNFaMk7mxyD1-g
