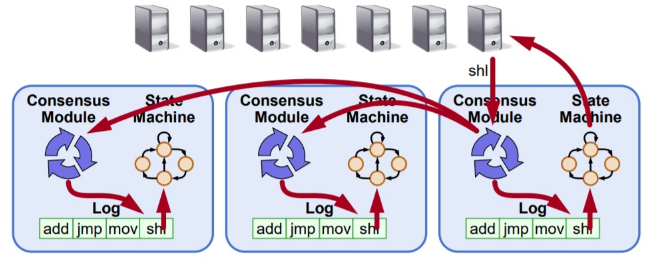
1. 背景
在 共识算法 之 Multi-Paxos(一) 中翻译了 multi-paxos 详细算法流程和细节,本篇作为(二)篇将通过图文来分析 multi-paxos 其各个模块的细节,Lead election,CommitIndex Advance,Log Replication等。主要还是参考文献 [1、2、3]。为了后文描述方便,这里将 multi-paxos 的 Proposer Algorithm 再贴一遍,详细的 RPC message 参考上篇(一)或者文献 [1]。

2. 算法分析
2.1. Leader election
在Multi-paxos中,任何一个 leader election 算法都可以给 multi-paxos 使用,这里不详细描述了。
在 multi-paxos 中 只有两种角色,proposer和acceptor,其中leader既是proposer,也是acceptor,其他的服务节点都是acceptor。如果没有 Leader,那么也就是没有 proposer,不能发起提案,和 raft 一样,Leader 才能提供服务。
相比 Basic Paxos,每个提案或者说 log entry 还增加了 index,实际上就是每个提案的的标识,是由 Leader 生成,单调递增的。除此之外,在 multi-paxos 中 Prepare 阶段的 Proposal Id 更接近于 Raft 的任期 ID(term id),但是不完全一样,因为 multi-paxos leader 可能还处于 noMoreAccepted = false 的阶段,这个时候和 paxos 是一样的。
2.2. Log replication
参考何登成老师文献 [3] 的图,可以看到 multi-paxos 的日志复制是可以允许空洞的,在 multi-paxos Proposer Algorithm 描述中,Acceptor 可以不关心其前面一条日志的提交状态,直接复制或者提交当前 leader 拷贝过来的日志,例如 Acceptor 1 的 log entry 8 和 Acceptor 2 的 log entry 7、9、10、11。这个相比 raft 性能上也会更加友好,避免慢节点可能影响 log repliaction 和 提交
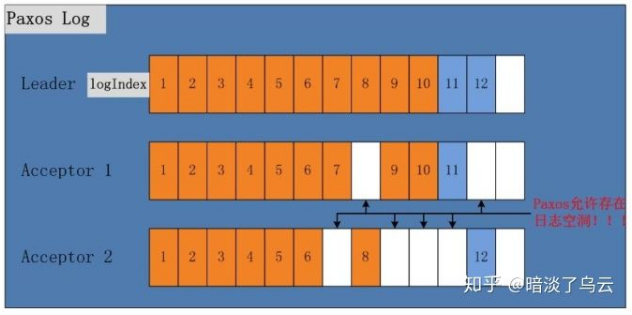
2.3. CommitIndex advance
参考文献 [3] 的图。注意图中的 committed index 就是文献中的 firstUnchosenIndex -1。推进 committed index 思路和 raft 是类似,还是 accept request 携带上 leader 的新的 committed index,然后 Acceptor 通过比较自己的 committed index,如果 Acceptor 的 committed index < leader 的 committed index,且 Proposal id 和 leader 相同,那就可以提交这条日志了。
这里有个隐含的概念,和 raft 类似,就是 leader 只提交自己生成的日志,不能代替之前的 leader 提交日志,在后面的 crash recovery 会详细描述为什么不可以,参见 2.4. 小节 (4)。

2.4. Crash recovery
其实 Crash recovery 就是从 Step 3 开始的,新当选的 Leader 上肯定会有一些日志空洞,或者未 committed 的日志,新的 Leader 一旦选举出现,就会从 committed index + 1 的 log entry ,开始一条一条的进行走一遍完整 paxos 来恢复。这里以上图中 Acceptor 2 为例,假设 Leader 挂了, Acceptor 2 选择为新的 Leader,那么其会从 index 为 7 的 log entry 开始恢复。我们这里逐条进行描述:
- (1)index 为 7 的 log entry 恢复
通过 Paxos 的 Prepare 阶段会学习到 value 88 然后在 Accept 阶段提交
- (2)index 为 8 的 log entry 恢复
通过 Paxos 的 prepare 阶段,肯定能学习自己的 value,因为这条 log entry 已经被提交,其 Proposal Id 是无穷大,那么会将 53 在复制给 Acceptor 1
- (3)index 为 9 的 log entry 恢复
这条日志在 Acceptor 上,没有,但是已经通过之前的 Leader 提交了,那么新的 Leader 肯定能够学习到这条 log entry 的 value,因为提交了意味着大多数的 节点上都有了,那么恢复的时候,避免能够学习到,所以自然会学习已经提交的 value 21 并恢复
- (4)index 为 10 的 log entry
尽管 Acceptor 2 上也有自己的 log entry,其会和 index 8 log entry 恢复一样,自己的 log entry 被丢弃。其实这里我们就需要注意到的是在 2.3 小节的 Leader 在提交 index 为 10 的 log entry 的时候就因为不是自己的任期生成的 log entry,所以就没有提交,想象一下,如果这里提交了,那么这个时候恢复就会出现问 题。
2.5. Membership change
实际上配置变更的日志也是和普通 Op 一样,也是一条 log entry,跟普通日志一样被复制到各个 acceptor 上,但是需要注意的是需要避免产生双主的局面,如下图,配置变更 3 台机器到 5 台机器,有可能会产生双主的局面。
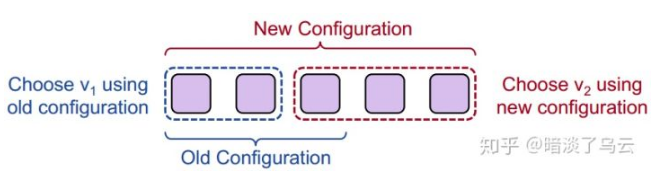
为了解决这个问题,multi-paxos 使用了一个简单的小技巧,也就是任何一个 configuration log entry 被复制 committed 之后,假设这个 configuration log entry 的 index 为 i,那么这个 configuration 只会在 index i+α 以及以后的 log entry 才开始生效,这样有效的避免了配置变更期间,是用 new configuration 还是用 old configuration 做决议的问题,有效的避免了双主,但是也有一个新的问题,那么就是:
- α 限定了 multi-paxos 的并发度
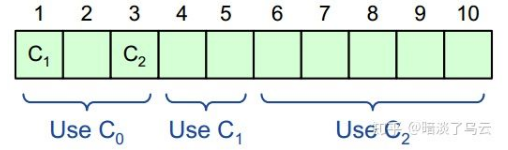
因为在 i~i+α-1 可能会有新的配置变更,所以其大的并发度只能是 α,当 α 设置为 1 时,log entry 的推荐并发读为 1,就变成了序列化的了。但是太大了,例如 800,那么新的配置会过很久才能生效,所以 α 值需要根据实际的情况来设置。为了让没有新 Op 下来的时候,配置尽快生效,可以通过发送 noop 来主动的推进,使得 new configuration 尽快生效
3. 总结
简单的分析了一下 multi-paxos 的算法的一些核心流程,但是比较粗糙,详细的内容英文可以参考[1、2],中文可以参考 [3、4]。
Notes
水平和时间有限,论文很多细节没看那么细,难免有错误和理解不到位的地方,欢迎指出和交流,除此之外,部分图片来源其他的文献,尽管指出了文献出处,但难免会存在侵权等行为,如有,麻烦联系我,将时间修改和删除。
参考文献
[1]. paxos-summay. https://ramcloud.stanford.edu/~ongaro/userstudy/paxossummary.pdf...
[2]. Implementing Replicated Logs with Paxos. https://ramcloud.stanford.edu/~ongaro/userstudy/paxos.pdf...
[3]. PaxosRaft 分布式一致性算法原理剖析及其在实战中的应用
[4]. 用paxos实现多副本日志系统--multi paxos部分. https://cloud.tencent.com/developer/article/1158799...
