现象描述
表定义如下:
CREATE TABLE t1 (a int, b int);
CREATE TABLE t2 (a int, b int);
执行如下查询:
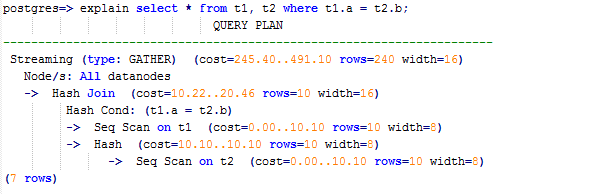
SELECT * FROM t1, t2 WHERE t1.a = t2.b;优化分析
如果将a作为t1和t2的分布列:
CREATE TABLE t1 (a int, b int) DISTRIBUTE BY HASH (a);
CREATE TABLE t2 (a int, b int) DISTRIBUTE BY HASH (a);
则执行计划将存在“Streaming”,导致DN之间存在较大通信数据量,如图1所示。

如果将a作为t1的分布列,将b作为t2的分布列:
CREATE TABLE t1 (a int, b int) DISTRIBUTE BY HASH (a);
CREATE TABLE t2 (a int, b int) DISTRIBUTE BY HASH (b);
则执行计划将不包含“Streaming”,减少DN之间存在的通信数据量,从而提升查询性能,如图2所示。