MySQL 8.0.17版本简介
2019-7-22号,Oracle发布了MySQL 8.0.17、5.7.27和5.6.45三个版本,后两个版本是维护版本,改动很小,主要进行几个bugfix。本次发布的重头是8.0.17版本。该版本进行了一系列的重大更新,我们可以从release notes中获取较全面的了解,更新内容很多,主要包括Provisioning by Cloning(基于克隆的实例部署)、Multi-valued indexes(用于JSON数组字段的多值索引)、JSON Schema(JSON字段的Schema校验)、Optimizer improvements(优化器改进)、Volcano iterator(火山迭代器)、Character Sets(utf8mb4字符集校对规则增强)、Replication and Group Replication(复制及组复制)和Router(MySQL Router增强)。本文仅关注全新的克隆功能。
克隆功能介绍
前克隆时代
在MySQL克隆功能出现之前,如果想将一个单机MySQL实例升级为高可用实例,或者一个MySQL节点由于硬件故障等原因需要重建时,需要如下操作:
- 通过xtrabackup或mydumper等物理或逻辑备份工具从正常的MySQL节点上进行一个全量备份;
- 基于这个全量备份配置正确的Binlog相关参数;
- 通过change master to和start slave等命令使新建的MySQL节点与所需的MySQL节点建立复制关系。
第1点是复杂的操作,尤其是在数据量大,线上业务压力较大的情况下。需要确保在尽快完成备份的要求下不影响或尽可能少影响线上业务;而且还必须保证备份的数据是一致的,可以基于这份数据建立复制关系。没有一定的MySQL使用经验,次使用xtrabackup或mydumper肯定会走些弯路。
其实,在这方面,MySQL的同门大哥Oracle,还有文档数据库MongoDB都比MySQL做得更好。举MongoDB为例,复制集提供了Initial Sync功能,往复制集中新加一个节点时,可以通过初始同步(Initial Sync)自动进行全量数据拷贝,并完成增量数据catchup。对于业务开发或DBA来说,省时省心。
可以说,克隆或叫全量数据同步功能的缺失是MySQL的一大短板,给MySQL高可用实例和组复制实例(MGR)的部署和运维增加了不小的难度。
克隆功能开发历程
在本次版本中发布的克隆功能补上了这一短板,MySQL官方主推的MySQL InnoDB Cluster方案又向前迈了一大步。在MySQL官方博客中详细介绍了他们的葡萄牙研发工程师Pedro Gomes的克隆功能的开发历程:
- 先通过Clone local replica (WL#9209)这个worklog解决核心的问题,将一个在线MySQL实例的数据克隆到本地目录;
- 接着通过Clone remote replica (WL#9210) 解决数据跨网络传输问题,将数据保存到一个远程目录,便以跨节点部署MySQL节点;
- Clone Remote provisioning (WL#11636)这个worklog更进一步,直接将数据拷贝到需重新初始化的MySQL实例的数据目录中。该worklog还增加了预检查功能;
- Clone Replication Coordinates (WL#9211)解决增量同步问题,增加了包括Binlog等相关信息用于建立与donor节点(数据源节点);
- Support cloning encrypted database (WL#9682)后一个worklog解决了数据加密情况下的数据拷贝问题。
克隆功能实现分析
克隆功能具体是怎么实现的,现有的文章都说是跟xtrabackup类似,那到底有多少是一样的,又有哪些不一样的。下面就来说说。
xtrabackup全备原理
首先来了解下xtrabackup是怎么实现全量备份的。我们先盗用一个图来建立个整体印象,原图出处。虽然比较老,现在的xtrabackup已经将innobackupex逻辑也包括进来了。
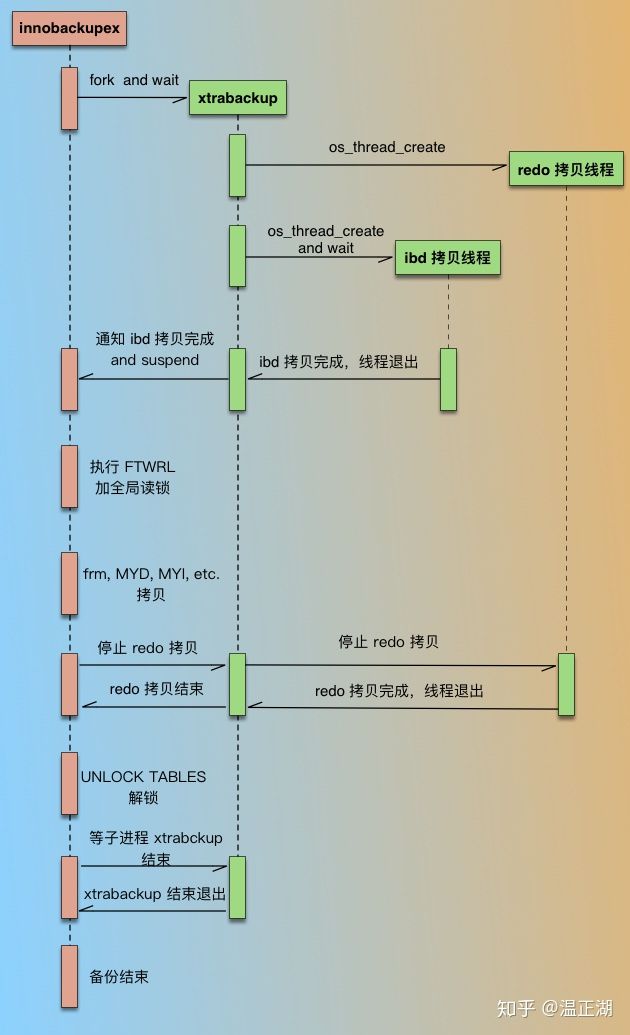
下面简单介绍下其备份流程:
- 首先从当前的checkpoint lsn开始拷贝redo,一直拷贝到当前新产生的lsn位置;图中未体现,也是容易被忽略的,详见另一篇文章描述;
- 只有拷完所有的redo日志后,才会开启redo拷贝线程和ibd拷贝线程。并行执行redo和ibd数据拷贝;
- ibd(InnoDB数据文件)拷贝线程完成所有数据拷贝;
- xtrabackup执行flush table with read lock(FTWRL),拷贝MyISAM表等非事务表数据;
- 获取Binlog文件及偏移位置,获取gtid_executed等信息。图中未提现;
- 执行FLUSH NO_WRITE_TO_BINLOG ENGINE LOGS。图中未体现;
- 等待redo拷贝进程退出;
- 执行unlock tables;
- 执行备份所需其他操作后退出; 也就是说,xtrabackup备份的数据一致性时间点点是在备份结束时,即在拷贝完数据文件后执行FTWRL时间点。(这与逻辑备份不同,像mydumper这样的逻辑备份,一致性时间点是在备份开始时)。xtrabackup通过备份整个ibd拷贝线程拷贝期间的redo日志来确保在restore(恢复)时数据的一致性。
xtrabackup的不足
xtrabackup大的问题是在redo日志拷贝上,由于InnoDB中,redo文件是循环利用的,如果redo拷贝线程的速度无法跟上业务产生redo的速度,那么还未拷贝的redo就可能被更新的redo覆盖掉,从而无法保证备份数据的一致性。一般来说这种情况是不会发生的,redo的拷贝速度能够跟上新redo产生速度。但xtrabackup有个throttle参数,用于限制redo和ibd文件的拷贝速度,确保备份操作不会占用过多的系统资源,从而影响到数据库上的正常业务。如果throttle参数设置不合理,那么就可能导致第1步或第2/3步执行时出错。使用xtrabackup时总会出现这样的案例。
这个问题该怎么解决呢,如果不改InnoDB的代码,这是解决不了的。因为无法准确估计redo产生的速度。
克隆功能原理
下面我们看看InnoDB克隆功能如何处理这个问题。前面提到MySQL官方博客列了克隆功能详细开发过程,其中为核心的部分是个worklog WL#9209。我们可以从中了解其设计方案,如下:
For a clone operation, InnoDB would create a "Clone Handle" identified by a locator returned to the clone plugin. The "Clone Handle" would be attached to a "Snapshot". The The diagram below shows multiple states of the "Snapshot" during cloning.[INIT] ---> [FILE COPY] ---> [PAGE COPY] ---> [REDO COPY] -> [Done]The idea is to use page delta for the larger part of the copy operation (file copy) and use redo for the second part to get to a consistent snapshot.We would also implement two innodb system wide features "Page Tracking" & "Redo Archiving" to be used by clone operation. The tracking would start from the current log sys lsn i.e. the lsn for the last finished mtr. Note that the changes before this lsn may not be flushed to redo or disk yet and caller should have appropriate considerations as explained below.
里面提到如下几点:
- 会创建一个快照,快照先后会有5个状态,其中FILE COPY对应xtrabackup的ibd拷贝,REDO COPY对应redo拷贝;
- 克隆功能会用到2个新特性,分别是Page Tracking和Redo Archiving;
PAGE COPY是xtrabackup没有的,而这是克隆功能的一个重大改进。下面我们就来看看worklog是如何解释这几个快照状态的:
FILE COPY: The state changes from INIT to "FILE COPY" when snapshot_copy interface is called. Before making the state change we start "Page Tracking" at lsn "CLONE START LSN". In this state we copy all database files and send to the caller.
该状态会拷贝所有的数据库文件,在开始拷贝前,会启动Page Tracking,记录CLONE START LSN这个lsn后被改动的所有InnoDB页的改动。更具体得说,CLONE START LSN的取值就是当前的checkpoint lsn,这是因为这个阶段直接拷贝物理文件,InnoDB只能确保checkpoint lsn之前的所有数据页面已经从Buffer Pool中刷回到磁盘上,在其之后的页面可能还未被回刷到磁盘。
Page Tracking会从指定的lsn,即checkpoint lsn开始跟踪每次从Buffer Pool回刷页面到磁盘的操作,并记录对应页面的space id和page id。这样就可以捕获该阶段的所有数据更改。
PAGE COPY: The state changes from "FILE COPY" to "PAGE COPY" after all files are copied and sent. Before making the state change we start "Redo Archiving" at lsn "CLONE FILE END LSN" and stop "Page Tracking". In this state, all modified pages as identified by Page IDs between "CLONE START LSN" and "CLONE FILE END LSN" are read from "buffer pool" and sent. We would sort the pages by space ID, page ID to avoid random read(donor) and random write(recipient) as much as possible.
这个阶段是克隆功能特有的。在完成数据库文件拷贝后开始,在开始前会启动Redo Archiving,同时停止Page Tracking。也就是从记录页面更改到记录redo变化。
Redo Archiving会从指定的lsn位置开始拷贝redo日志。相比xtrabackup的拷贝线程,该功能更加可靠,因为新产生的redo日志在写入redo文件前,会判断是否会覆盖还未被拷贝走的redo日志,如果是的话,会等待Redo Archiving完成拷贝。
该阶段会将Page Tracking记录的所有页面拷贝并发送到指定位置,在拷贝前,会基于spaceid和page id进行排序,尽可能确保磁盘读写的顺序性。这个阶段的数据拷贝效率应该会远高于文件拷贝阶段,因为新修改的页面基本上都还在Buffer Pool,无需从磁盘中读取。
REDO COPY: The state changes from "PAGE COPY" to "REDO COPY" after all modified pages are sent. Before making the state change we stop "Redo Archiving" at lsn "CLONE LSN". This is the LSN of the cloned database. We would also need to capture the replication coordinates at this point in future. It should be the replication coordinate of the last committed transaction up to the "CLONE LSN". We send the redo logs from archived files in this state from "CLONE FILE END LSN" to "CLONE LSN" before moving to "Done" state.
该阶段在完成页面拷贝后进行,会加锁获取Binlog文件及当前偏移位置,和/或gtid_executed信息,并停止Redo Archiving。在解锁后,将Binlog相关信息和拷贝的redo日志发送到指定位置。发送完后,克隆功能的快照拷贝步骤也就结束了。 显然,在克隆功能中,解决了xtrabackup拷贝redo时存在被覆盖问题,提高了可用性;同时,通过引入PAGE COPY这个新阶段来减少了所需归档的redo日志量,这样可以有效缩短应用redo日志所需的时间,可大大提升性能。总的流程大致如下所示:

需要注意的是,克隆功能会删除目标MySQL实例上的所有数据。若实例上的数据还有用处,需确保在使用该功能前做好备份。
MGR中的克隆功能
上述5个worklog构成了完整的克隆功能。但这还不够,为了能够方便得在MGR中使用,Pedro Gomes还开了个worklog:Clone plugin integration on distributed recovery (WL#12827),用于将克隆功能集成到MGR的分布式故障恢复模块中。
在MGR中有2个场景会用到克隆功能:一是往MGR集群中新增一个节点时;二是故障恢复的节点与其他节点的复制延迟超过所设阈值group_replication_clone_threshold时。
克隆功能的使用方法可通过该文章了解到。需要指出的是,相比非MGR场景,在MGR中使用克隆功能更加方便,用户需要设置的就是group_replication_clone_threshold参数,克隆功能的原生参数clone_valid_donor_list和命令CLONE INSTANCE FROM等MGR均会自动完成设置和操作。
MGR的克隆与MongoDB复制集的初始同步对比
两者均为了解决数据库集群的新节点/重建节点的全量备份问题,下面简要分析下其异同点。
- 实现方式不同(物理/逻辑):MongoDB复制集的初始同步类似于mydumper,是多线程的逻辑备份。而如前所述,MGR的克隆是物理文件拷贝;
- 性能方面:由于实现方式不同,会对性能产生一定的影响,理论上说,逻辑备份需要有个恢复(Insert/Write)过程,性能相比拷贝物理文件会差些,尤其是在大数据量的情况下;
- 操作复杂度:这也是与实现方式相关的,MGR的克隆是使用donor节点的物理文件覆盖本节点的文件,需要有个reload之类的过程,就MGR克隆功能来说,是通过重启mysqld来实现的,而mysqld不可能让自己重启的,所以需要mysqld_safe或外部机制进行重启。这会带来一定的不确定性;
- 状态监控:两者均提供了进度监控和显示能力,对操作者来说都比较友好;
小结
本文首先介绍了新发布的MySQL 8.0.17主要新增特性,引出了InnoDB克隆插件这一引人关注的特性,分析该特性能够带来的重大作用;接着在xtrabackup备份原理的基础上分析了克隆功能的实现方案;后介绍MGR中的克隆功能,并对比了其与MongoDB初始化同步特性的异同点。
