PolarDB-X 2.0(以下简称PolarDB-X)与DRDS(DRDS也称为PolarDB-X 1.0)都是阿里云上的分布式数据库产品。看起来她们都是Share-Nothing的架构,用水平扩展来解决单机数据库瓶颈问题。很多同学因此会有疑惑,她们俩到底有什么样的区别?
DRDS,其本质是搭建在标准MySQL(阿里云上的RDS For MySQL)上的分库分表中间件,具有很高的灵活性。 PolarDB-X是使用云原生技术的分布式数据库,具有一体化的数据库体验,其存储节点是经过了高度定制的MySQL,从而提供了大量中间件无法提供的能力(使用全局MVCC的强一致的分布式事务、私有RPC协议带来的性能提升、Follower上的一致性读能力等等)。
本文带大家从各个角度剖析下,PolarDB-X与DRDS的异同。
首先简单说下她们相似的地方:
- 她们都能基于Share-Nothing的架构,具备极强的水平扩展能力
- 她们都基于MySQL的生态体系,具有很高的MySQL兼容性
- 她们使用同样的SQL引擎,具备相似的SQL执行能力
- 她们均提供分布式事务、全局索引等常见中间件不具备的高阶能力
- 她们都在阿里巴巴内部广泛使用,历经多年双十一的考验,稳定可靠
接下来我们重点看下她们有哪些区别。
使用体验
抛开技术原理,我们先看下直观的产品体验上有哪些异同。
1、购买实例
由于DRDS是一个中间件,所以其和MySQL的接线划分的比较清晰,DRDS本身不包含MySQL(RDS)资源,MySQL由用户单独购买。你需要在两个产品的控制台上单独进行购买,并在DRDS控制台上将其组装在一起。
PolarDB-X提供的是一个整体的数据库服务,你只需要创建一个PolarDB-X实例即可,其中包含了所需要的计算资源、存储资源。
2、建库
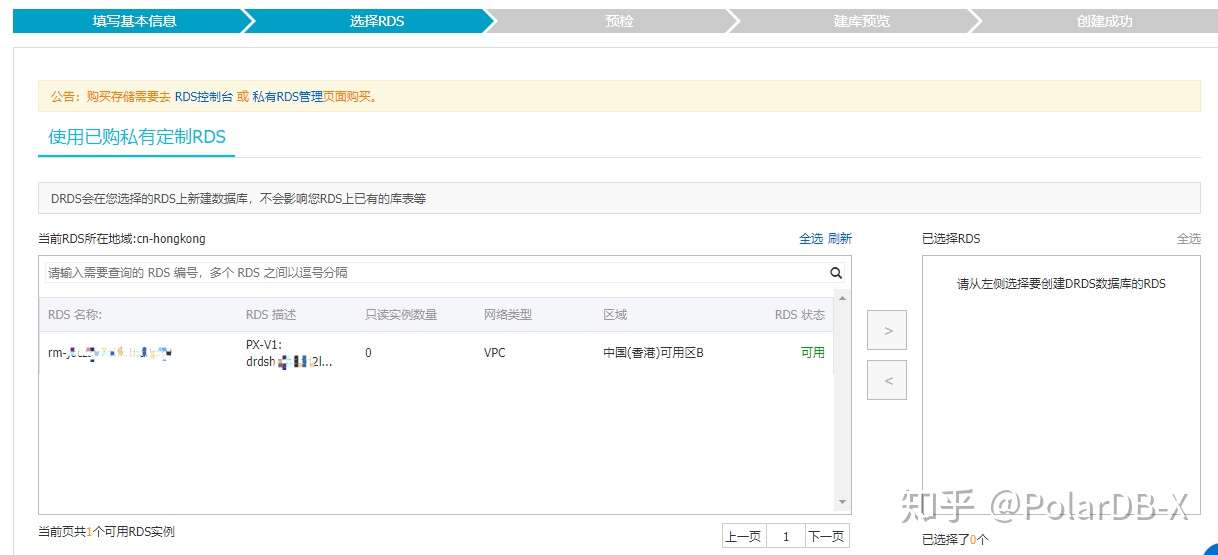
DRDS中,建库需要在控制台完成,并且在建库过程中需要选择已有或者购买新的MySQL资源:
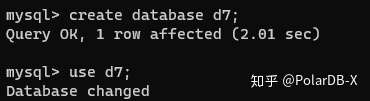
PolarDB-X中,你可以像使用单机数据库一样,使用你习惯的工具进行连接,然后使用CREATE DATABASE指令创建数据库:
3、扩容
DRDS中,你需要评估每个MySQL的容量,并选择将哪些分库挪到新的MySQL存储上。
PolarDB-X中,你只需要选择节点数,数据将自动均衡的分布在各个存储节点上。
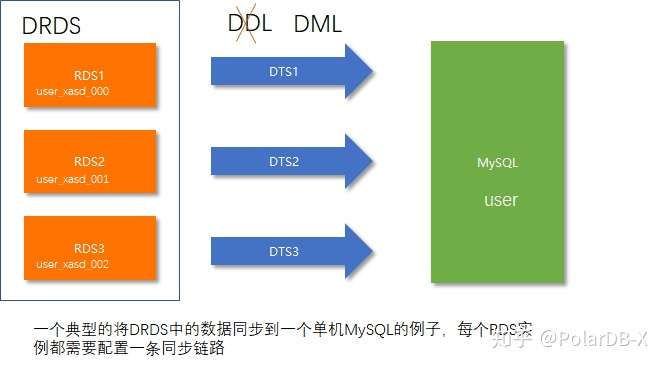
4、数据同步
如果你要将DRDS中的数据同步到下游,很多时候你需要使用DTS来订阅其中的每一个MySQL实例,并仔细处理同一个逻辑表的不同分表之间例如表名的差异等细节,并且DDL操作会让这个同步链路中断。
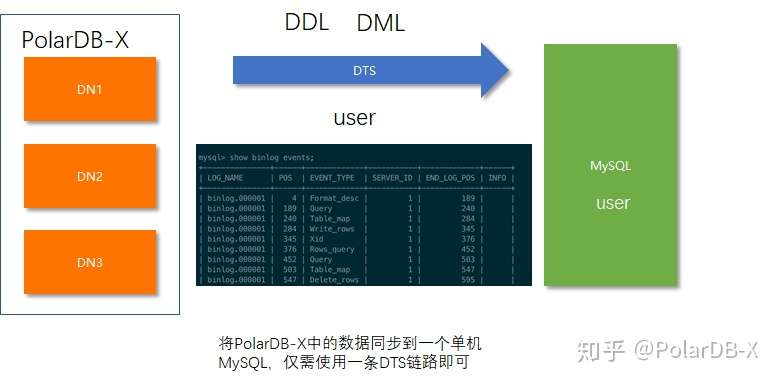
PolarDB-X提供一个统一的binlog服务,你可以使用DTS像订阅一个单机MySQL一样来订阅它。这个binlog服务完全兼容MySQL,其屏蔽了所有的分布式的细节,让下游服务认为它是一个普通的单机MySQL(例如PolarDB-X支持包括SHOW BINLOG EVENTS在内的所有BINLOG相关的指令)。
5、读写分离
DRDS中,你可以使用只读实例(备库)来进行一些高消耗的SQL,避免对在线业务产生影响。但是,你需要手动来判断这些SQL的类型,并通过HINT、不同的连接串等方式,将其放到正确的地方来执行。同时,你需要注意备库上存在延迟,你需要改造你的业务系统,使其能够容忍这种延迟。
PolarDB-X中,应用使用一个连接串即可,你无需关注这些SQL的类型和代价(用不着给它们加HINT),它的优化器会自动识别这些SQL的代价,并且使用正确的资源池来执行它们,尽大可能避免AP的SQL影响到TP的SQL。 同时,PolarDB-X的存储节点,支持Follower上的一致性读,因此你不需要担心在备库上读取数据会读到老的数据,任何时候去读,都能读到新的数据。
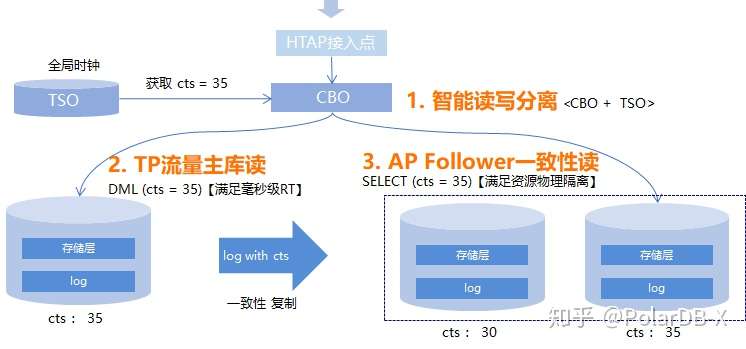
6、运维
由于DRDS允许使用你自己购买的MySQL实例进行组件,因此你拥有这些MySQL实例完整的运维权限,你可以对它们做任何你想做的事情,例如:
- 负载不均衡时,单独对其中一个节点进行规格的升级
- 将其中的某个存储节点给其他的业务使用
- 使用任意版本的RDS(5.6、5.7、8.0均可)
- 订阅任意一个RDS的binlog
但是,这种灵活性也存在一定的风险,例如,我们没有办法阻止你直接删除其中的一个分库,这会导致DRDS无法正常访问这个分库上的数据。
PolarDB-X对用户屏蔽了存储节点,你不能、也不需要直接访问其存储节点,它将一个数据库的整体视角呈现给用户,它通过自动的负载均衡、逻辑binlog、混合负载的HTAP等能力来减少你对存储节点直接访问的需求。目前PolarDB-X DN主要基于的的MySQL版本为5.7,后续8.0的支持也已经在规划中。
架构差异
以上的差异,很多由其架构决定,我们看下PolarDB-X与DRDS在架构上的差异点。
这是DRDS的架构图:
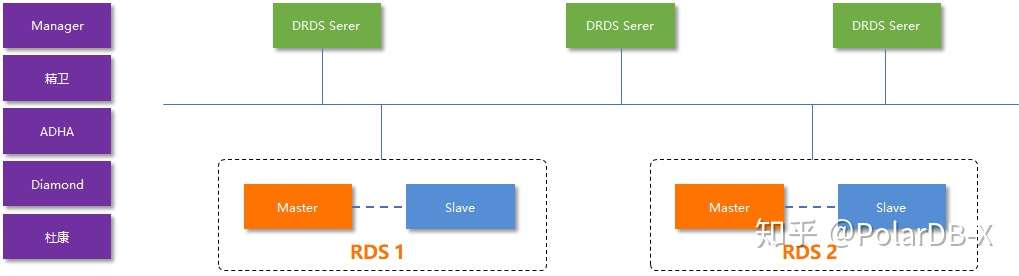
DRDS的架构中,大量功能依赖外围管控系统完成,例如:
- 扩容,使用内部一个叫精卫的组件来进行
- 元数据,一个地域内会共享一个叫Diamond的存储
- 主备探活、切换,依赖一个叫ADHA的组件
- 等等
这是PolarDB-X的架构图:
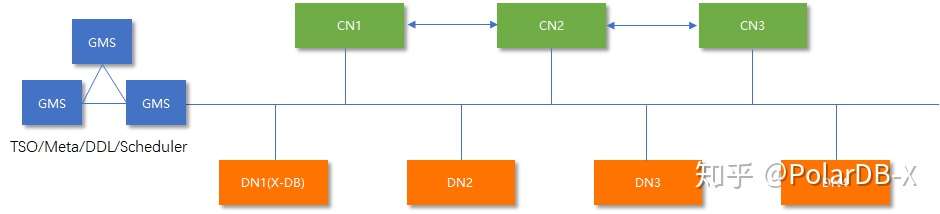
PolarDB-X中,核心功能全部内聚到内核。
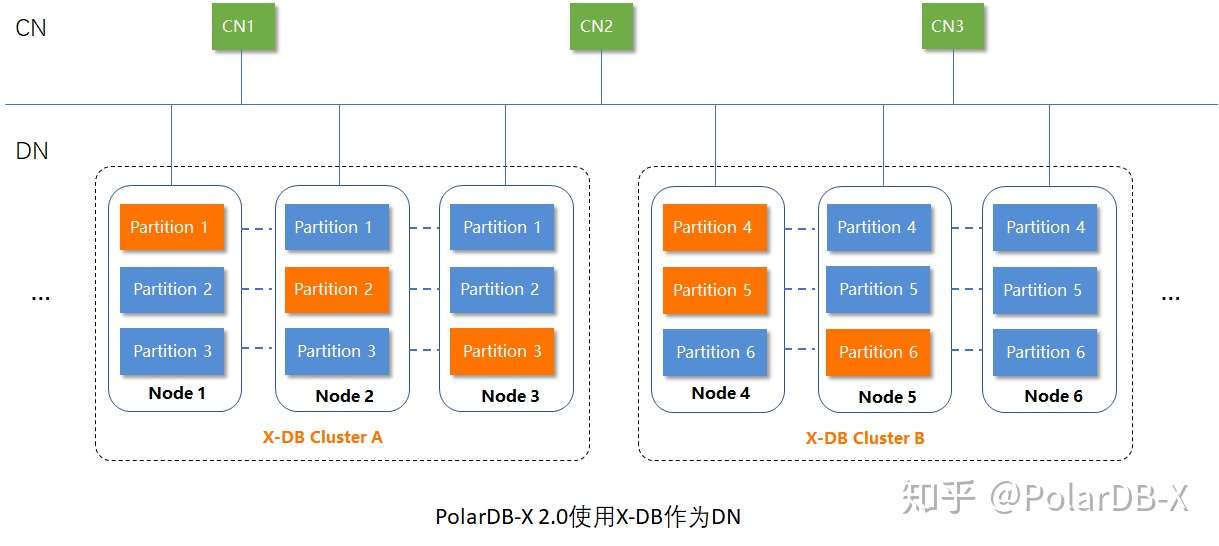
1)PolarDB-X使用X-DB作为其DN(数据节点)(什么是X-DB)。X-DB 使用 Paxos(PolarDB-X 一致性共识协议 —— X-Paxos)做到了RPO=0。
2)PolarDB-X相比DRDS,引入了一个新的组件:GMS(Global Meta Service),它具备非常重要的作用:
- 提供分布式事务所使用的全局自增的时间戳
- 根据负载情况,调度数据的分布,使节点之间达到均衡
- 提供统一的元数据,例如INFORMATION_SCHEMA
- 对CN与DN进行管理,例如切换、上下线等
3)DRDS的扩容基于binlog,依赖外围管控系统完成。PolarDB-X的扩容基于分布式事务,由内核完成。
4)架构继续往下细化,我们可以看一下其数据的分布情况:
DRDS下的RDS是传统的主备(或者三节点)架构,主备以实例级为单位,正常情况下备库不提供服务:
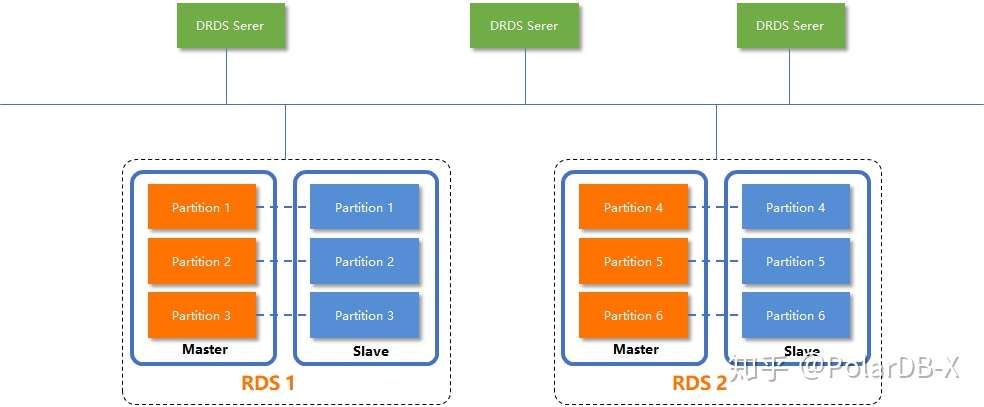
PolarDB-X下的DN,均为三节点架构,Paxos组以分片为单位,一个节点可以同时是一个分片的Leader与另一个分片的Follower,资源利用率更高:
事务模型
事务的实现机制,是一个数据库根本的特征,PolarDB-X与DRDS上的事务机制,有着非常巨大的差异。
DRDS使用的是MySQL官方提供的XA事务。XA事务可以保证写入操作的原子性。
但是,标准的XA存在一个问题是,可能会在一个分片读到已提交的数据,再另一个分片读到未提交的数据。
例如,有两张空表 t1(pk,name,addr) dbpartition by hash(pk),t2(pk,name,addr) dbpartition by hash(name)。假如应用在事务1中对两张表分别进行一个插入操作 insert into t1 values (1,'sun','hz'),insert into t2 values (1,'sun','hz'):
begin;
insert into t1 (pk,name,addr) values (1,'sun','hz');
insert into t2 (pk,name,addr) values (1,'sun','hz');
prepare p1;
prepare p2;
commit p1;
commit p2;同时,有另一个只读事务,分别对t1与t2进行count操作,它们就可能读到不一样的结果。
如下的时间线:
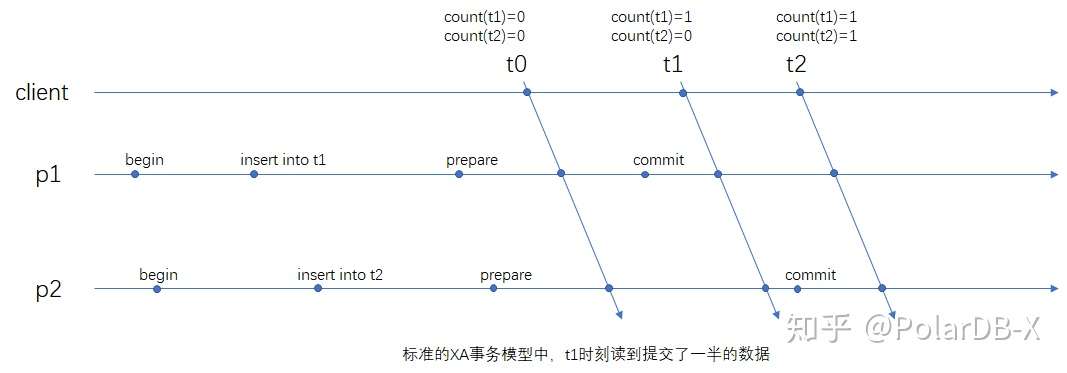
其中t1时刻,在一个事务内对t1和t2表进行查询,会得到不一样的记录数,这是一个不一致的结果。
DRDS中,为了解决这个问题,使用的是加锁的实现,在冲突多的情况下,有比较高的代价。
PolarDB-X使用自研的全局MVCC事务,在两阶段提交(2PC)的基础上,增加了事务快照时间戳(snapshot_ts)和提交时间戳(commit_ts)的支持。时间戳来自于全局 TSO 的分配,因此能做到外部一致的事务保证,并且避免了额外的加锁。在上述例子中,t1的时间由于比commit的时间晚,因此一定能读到两张表都是1的结果。
PolarDB-X的事务机制相对比较复杂,请大家参考:PolarDB-X 强一致分布式事务原理。
性能提升
PolarDB-X的性能相对DRDS有很大的提升,主要体现在几个方面。
1)精简的网络结构
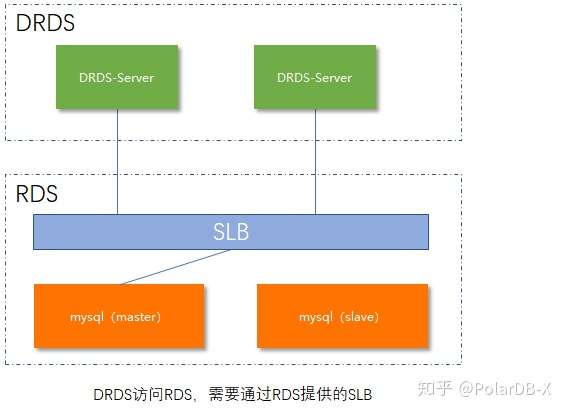
DRDS连接RDS,使用的是RDS标准的访问链路,中间需要经过SLB的中转,会增加一跳的网络延迟:
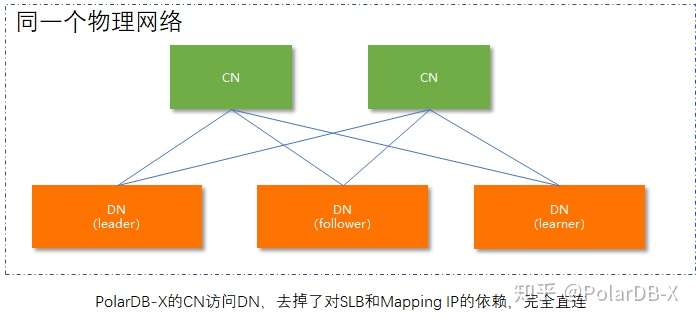
PolarDB-X的CN节点与DN节点均在一个物理网络中,中间是点对点的直连,不经过任何SLB/LVS等中转,具有低的网络延迟,下图是一个CN到DN的网络拓扑示意:
2)私有RPC协议
DRDS使用标准的MySQL协议连接RDS,发送标准的SQL语句。但这里会有不少的开销,例如:
- SQL经过DRDS优化器的优化后,还需被MySQL的优化器再次优化,如果涉及到多个MySQL分片,重复的次数会更多
- MySQL协议中有很多的冗余元素,例如结果集的头,里面存储了结果集每一行的名字、类型等信息,这些是不需要的
- MySQL协议返回的数据与DRDS内部计算使用的数据并不是一个格式,这中间需要经过再次转换
- DRDS使用连接池来连接MySQL,MySQL的连接与线程是绑定关系,同一个连接上同一时间只能执行一个SQL。这导致DRDS与RDS之间需要维持大量的连接
PolarDB-X为了解决DRDS存在的这些问题,对MySQL进入了大量定制,中间的通信才用了私有的RPC协议,与MySQL协议相比有以下几个优势:
- 传递的不再是SQL,而是执行计划,避免MySQL重复对SQL进行解析、优化的代价
- 使用异步模型,连接与线程、连接与会话不在是一一绑定的关系,使用比较少的连接即可满足需求
- 精简了通信中不需要的信息,例如结果集的头等
- 传输的数据格式与CN计算使用的格式完全一致,避免数据的二次转换
通过使用私有的RPC协议,PolarDB-X相对于DRDS,在很多场景下得到了性能提升。以下数据摘自:PolarDB-X 私有协议设计
sysbench-select
- 1.6亿行数据
- 300并发
- 计算节点和存储节点规格均为16c64g
- +39%

sysbench-oltp
- 1.6亿行数据
- 150并发
- 计算节点和存储节点规格均为16c64g
- +14.4%

3)MPP引擎对分析类查询的加速
DRDS中使用的是SMP(单机并行)技术,PolarDB-X中使用的是MPP(多机并行)技术。这使得PolarDB-X相对于DRDS,在面对复杂分析查询时,可以使用更多的资源来加速。这个性能差异体现在TPC-H上非常的显著。下面是同资源情况下,DRDS与PolarDB-X在TPC-H上的对比:
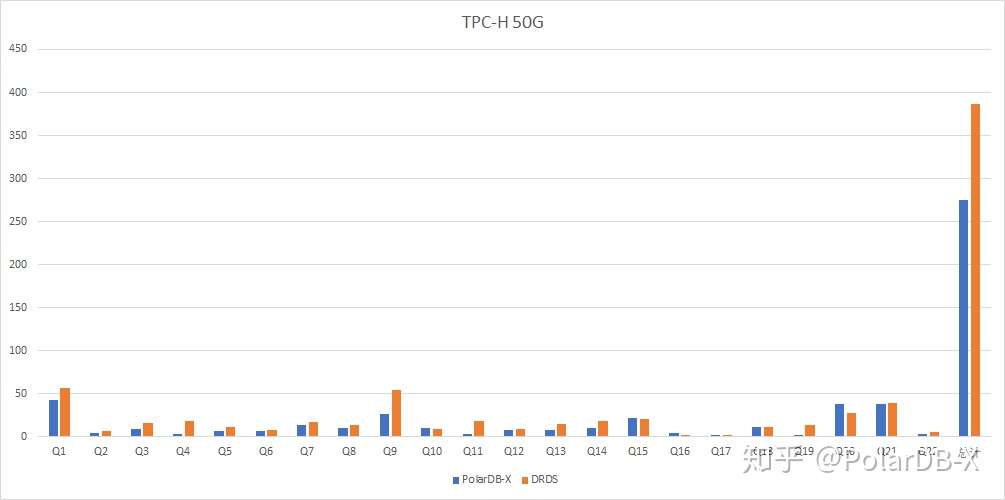
DRDS 总耗时386s,PolarDB-X总耗时274s。
小结
PolarDB-X与DRDS的差异是方方面面的,DRDS是分库分表中间件的代表,PolarDB-X是云原生分布式数据库。有一个形象的比喻,DRDS和PolarDB-X的关系相当于宝马3系和5系,她们将长期共存,为不同需求的用户提供服务。
来自:https://zhuanlan.zhihu.com/p/333458136
