
本期论文:MapReduce: Simplified Data Processing on Large Clusters
MapReduce是一种处理海量数据的并行编程模型,用于大规模数据集(通常大于1TB)的并行计算。以这种编程模型所编写的程序可以自动地在集群上并行执行,封装了并行计算、容错处理、数据存储、任务调度、任务间通信等细节,用户只需专心于并行程序的编写。MapReduce适用于复杂度不高的海量数据搜索、挖掘和分析。
MapReduce编程模型
MapReduce输入一个键值对,输出另一个键值对,用户则通过编写Map函数和Reduce函数来指定所要进行的计算。
Map:接受一个键值对(key-value pair),产生一组中间键值对。MapReduce会将Map函数产生的中间键值对传递给一个Reduce函数。
Reduce:接受一个键以及相关的一组值,将这组值进行合并产生一组规模更小的值(通常只有一个或零个值)。
在实现的过程中,Reduce函数使用Iterator读取中间结果,为了防止值过多,而无法全部放到内存中。
由用户提供的Map函数和Reduce函数应有如下类型:

即Reduce函数的输入类型必须与Map函数的输出类型相同。
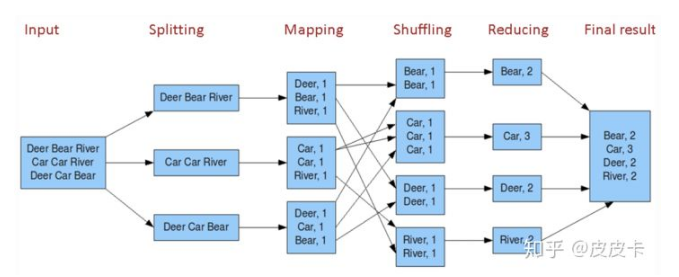
Word Count示例
map(String key, String value):
// key: document name
// value: document contents
for each word w in value:
EmitIntermediate(w, "1");
reduce(String key, Iterator values):
// key: a word
// values: a list of counts
int result = ;
for each v in values:
result += ParseInt(v);
Emit(AsString(result));MapReduce执行过程

- 用户程序将输入文件切分为M个16~64MB之间的split,并在集群中创建程序副本。
- 程序副本分为1个Master和多个Worker。Master选取空闲的Worker,并为其分配Map任务或Reduce任务。Master存储Map任务和Reduce任务的状态(空闲,工作中,完成)和worker机器(非空闲任务的机器)的标识。
- Mapper读取对应的split并解析为键值对,调用用户定义的map函数进行处理,将输出的中间结果键值对存储到内存中。
- Mapper将缓存的键值对通过Partition函数(通常为hash(key) mod R)划分为R个部分,并周期性地写入本地磁盘,同时将本地磁盘上中间结果的位置信息发送给Master。
- Master将收到的中间结果的位置信息发送给Reducer,Reducer通过RPC读取存储在Mapper本地磁盘上的中间结果。在读取完毕后,Reducer会根据key对中间结果进行排序。
- 对每一个key和其对应的一组值,调用用户定义的Reduce函数进行处理,输出结果存储在对应的Reduce Partition文件中。
- 当所有的Map任务和Reduce任务完成后,Master通知用户程序。
MapReduce容错机制
由于MapReduce很大程度上利用了由Google File System提供的分布式原子文件读写操作,所以容错机制简洁很多,主要集中在任务意外中断的恢复上。
worker失效
Master会周期性地ping每一个Worker,如果某个Worker在一段时间内没有响应,Master就会认为这个Worker已经不可用,对其上分配的任务重新分配给其他Worker。
master失效
Master会周期性地将集群的当前状态作为checkpoint写入到磁盘中。Master发生故障后,重新启动Master即可利用存储在磁盘中的近的checkpoint进行恢复。
数据存储机制
由于网络带宽是一种相当匮乏的计算资源,MapReduce将数据存储在本地磁盘,由GFS进行管理。GFS把每一份文件划分为多个64MB的block,通常情况下,每个block会在不同的机器上保存三份副本。Master在调度Map任务时会考虑输入数据的位置信息,采取就近原则,即尽量将Map任务调度到包含相关输入数据副本的机器上执行。因而大部分输入数据可以从本地读取,消耗非常少的网络带宽。
负载均衡机制
Master将Map任务和Reduce任务划分为M和R个片段,M和R的数量应远大于集群中Worker的数量。每个Worker执行大量不同的任务有助于提高集群的动态负载均衡能力,并且加快故障恢复的速度。
备份任务机制
如果集群中某个Worker花了很长时间才完成后几个Map任务或Reduce任务,导致MapReduce总执行时间延长,这样的Worker被称为落后者(Straggler)。MapReduce提供了备份任务机制来缓解这种情况。当MapReduce快要完成时,Master为剩下的正在运行的任务启动备份任务,将其分配给其他的空闲Worker来执行,并在其中一个Worker完成后将该任务视作已完成。通过备份任务机制,大大减少了MapReduce的执行时间。
此外,MapReduce还提供一些扩展功能,如Partition函数、Combiner函数、本地执行、状态信息、计数器等。
实验结果
作者在一个大型集群上进行Grep任务和排序任务来测试MapReduce的性能。实验结果表明,在1TB数据中匹配三个字符的模式用时150秒;对1TB数据进行排序用时891秒。此外,对于排序任务,当取消备份任务机制后,由于落后者的存在,其完成时间延长至1283秒,多了44%%;当kill掉1746个Worker中的200个Worker后,完成时间延长至933秒,只比正常情况多5%%。
参考文献
[1]Dean J, Ghemawat S. MapReduce: Simplified Data Processing on Large Clusters[C]. Proceedings of the 6th USENIX Symposium on Operating Systems Design and Implementation. 2004: 137-150.
