作者:黄天元,复旦大学博士在读,热爱数据科学与开源工具(R),致力于利用数据科学迅速积累行业经验优势和科学知识发现,涉猎内容包括但不限于信息计量、机器学习、数据可视化、应用统计建模、知识图谱等,著有《R语言数据高效处理指南》(《R语言数据高效处理指南》(黄天元)【摘要 书评 试读】- 京东图书)。知乎专栏:R语言数据挖掘。邮箱:huang.tian-yuan@qq.com.欢迎合作交流。
模型做好之后,获得的预测值与实际值之间差异的大小,能够用来评价模型的效果。对于数值型因变量的评价方法有很多,包括MASE/MAPE/MAE/RMSE等,个人常用的是RMSE。
对于每个指标的介绍,这里不做重复工作,可以参照:
1、AI科技大本营:避坑指南:如何选择适当的预测评价指标?| 程序员评测(中文)
2、3.4 Evaluating forecast accuracy | Forecasting: Principles and Practice(英文)
在fpp2包中,可以用accuracy函数来计算模型的准确度:
library(fpp2)
# 抽取目标序列
beer2 <- window(ausbeer,start=1992,end=c(2007,4))
# 分别利用平均值、简单方法、季节简单方法进行拟合,预测时长为10个时间单位
beerfit1 <- meanf(beer2,h=10)
beerfit2 <- rwf(beer2,h=10)
beerfit3 <- snaive(beer2,h=10)
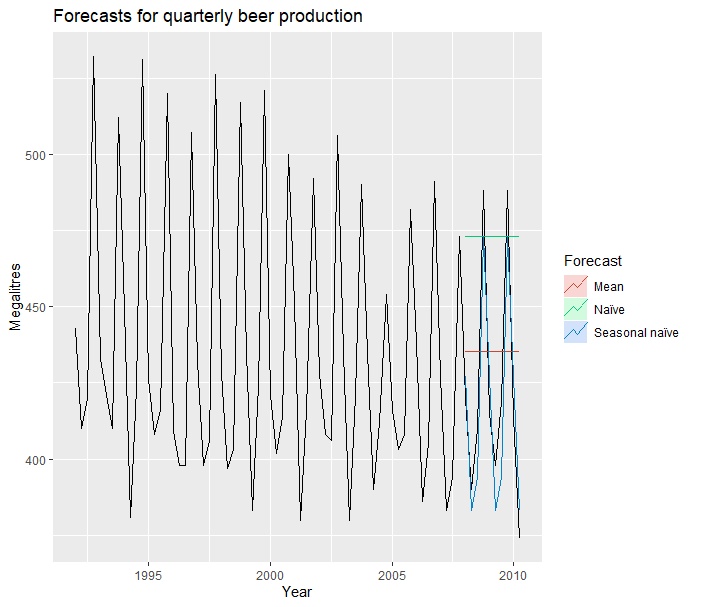
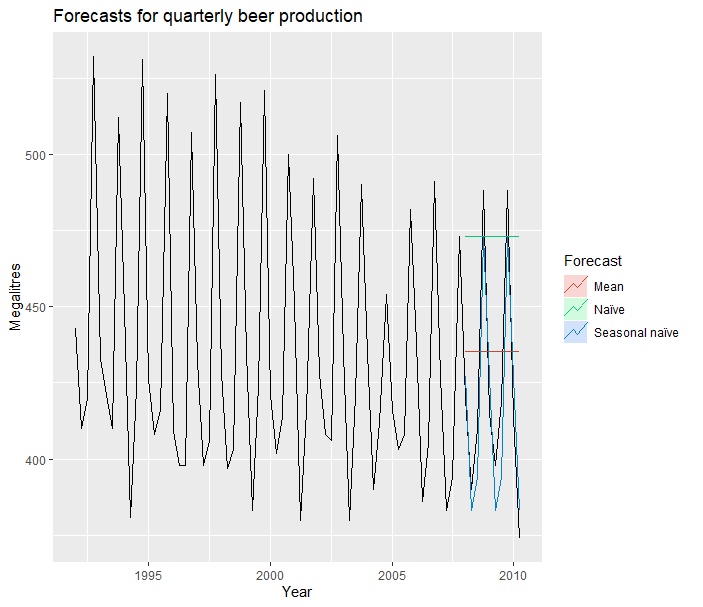
# 进行可视化
autoplot(window(ausbeer, start=1992)) +
autolayer(beerfit1, series="Mean", PI=FALSE) +
autolayer(beerfit2, series="Naïve", PI=FALSE) +
autolayer(beerfit3, series="Seasonal naïve", PI=FALSE) +
xlab("Year") + ylab("Megalitres") +
ggtitle("Forecasts for quarterly beer production") +
guides(colour=guide_legend(title="Forecast"))
# 提取验证集
beer3 <- window(ausbeer, start=2008)
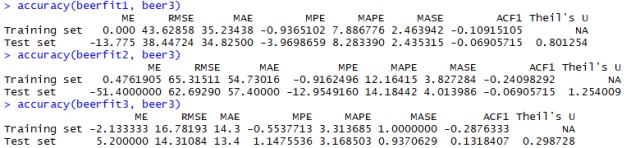
# 预测集与验证集进行比较,计算各项评价指标
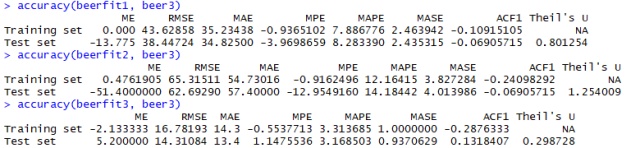
accuracy(beerfit1, beer3)
accuracy(beerfit2, beer3)
accuracy(beerfit3, beer3)所得核心结果如下:
上面这些方法,都是基于前面的大段序列,然后对未来的连续序列进行预测,并评估其效果。其实评价的设计还可以使用交叉验证(cross-validation)。比如有10天的数据,那么就用前3天的数据预测第4天,前4天预测第5天...前9天预测第10天,然后这些预测的残差综合起来,作为预测的终结果。示意图如下:
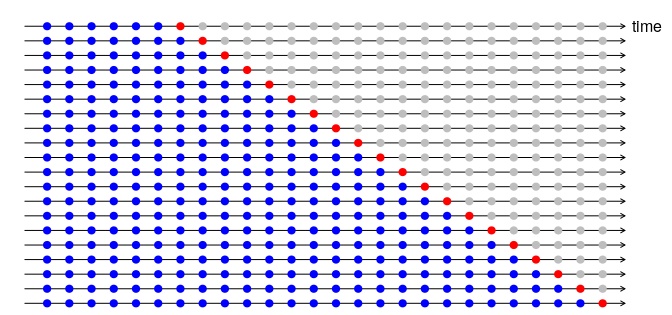
比如我们使用drift预测方法,预测后面的1个时间单位,其使用CV设计的RMSE的计算方法为:
goog200 %>% tsCV(forecastfunction=rwf, drift=TRUE, h=1) -> e
e^2 %>% mean(na.rm=TRUE) %>% sqrt()
#> [1] 6.233tsCV函数个参数为序列,第二个为预测函数,后面跟着预测函数的其他参数,输出为残差。残差求平方然后求均值再开放,即为RMSE。
有时候希望看看利用这个模型预测后面更多时间单位的数值,比如8个,那么例子如下:
e <- tsCV(goog200, forecastfunction=naive, h=8)
# Compute the MSE values and remove missing values
mse <- colMeans(e^2, na.rm = T)
# Plot the MSE values against the forecast horizon
data.frame(h = 1:8, MSE = mse) %>%
ggplot(aes(x = h, y = MSE)) + geom_point()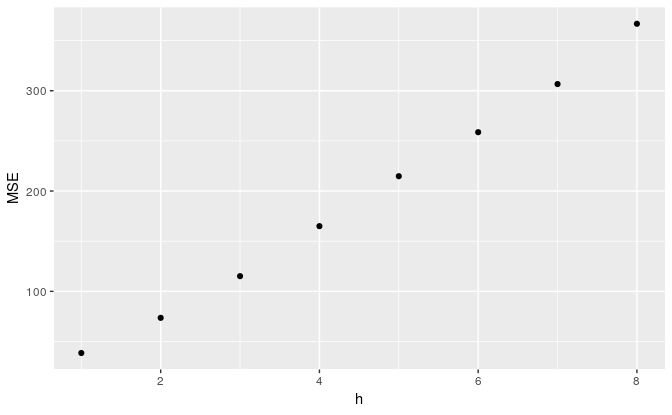
可以看出来,预测时间长度越长,那么模型可能越不准确(MSE越高)。
