作者:黄天元,复旦大学博士在读,热爱数据科学与开源工具(R),致力于利用数据科学迅速积累行业经验优势和科学知识发现,涉猎内容包括但不限于信息计量、机器学习、数据可视化、应用统计建模、知识图谱等,著有《R语言数据高效处理指南》(《R语言数据高效处理指南》(黄天元)【摘要 书评 试读】- 京东图书,《R语言数据高效处理指南》(黄天元)【简介_书评_在线阅读】 - 当当图书)。知乎专栏:R语言数据挖掘。邮箱:huang.tian-yuan@qq.com.欢迎合作交流。
近接到一个任务,需要把保存在Excel表格多工作表的数据读取出来,然后再进行各种清洗、处理和计算(如长宽转换、根据公式进行计算、统一杂乱无章的存储格式等)。一个工作簿中有80多个工作表,每个工作表有自己的名称,行有题目,第二行有中文标注,第三行有英文缩写码...如果直接用交互式操作肯定是崩溃的,估计一个月都不一定能做完。数据量不能说大,每张工作表也就8000+行,没有一个表格是破万的(事实上综合所有表格数据后统计总共有76000+条数据)。
为了完成这个任务,就不得不先读取所有Excel中的信息,包括工作表名称、题目、每个表格的所有列都是什么(不知道就没法计算)。读取Excel的话,这次用了realxl包,还是比较好用的。可以参考以下链接:
CRAN - Package readxl之所以用了它,是因为我手里的Excel表格不仅有xlsx格式的,还有xls格式的。如果工作表不多,可以转换一下,统一用openxlsx包,但是读取的时候使用一下还是很便捷的。
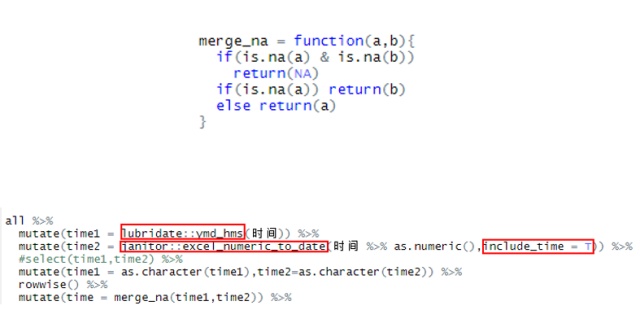
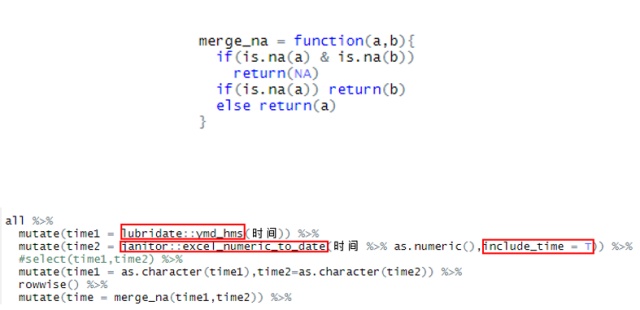
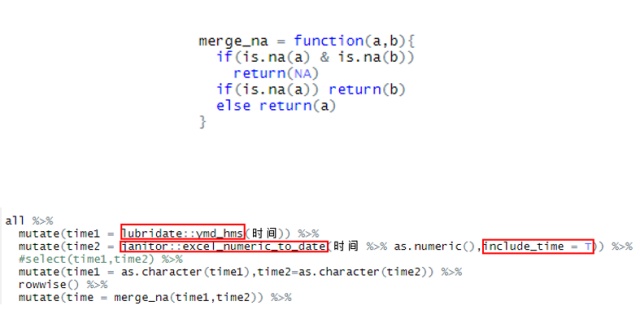
能够读取之后,后面所有的设计当然还是使用tidyverse生态系统来完成,几乎没有无法完成的任务,但中间还是遇到了很多难题,不断卡壳。比如时间的转化,发现时间的格式不统一,有的要使用lubridate包来做,有的时候则需要用janitor包来做,后还要吧两者的结果合并起来,如下图所示:
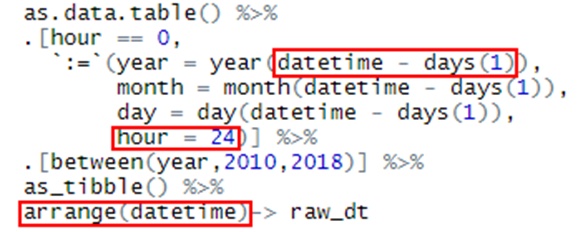
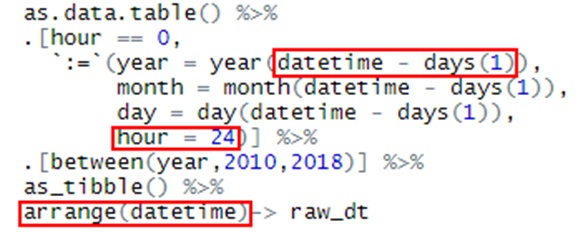
还有在时间上原始表格使用0时作为标准,但是规范化的结果表则需要使用24小时坐标标准,于是我只好把0换成24,但是日期要减少1天:
因为数据特别杂乱,根本无法设置通用函数来处理一切,为批处理带来了巨大的挑战。其中,使用汇总函数(max/min/mean)需要忽略缺失值,为了少写一些na.rm = T,我参考了SO的内容,进行了全局设置。此外,还需要认为定义上旬、中旬、下旬(case_when),并对组内的数据再次进行分组汇总:
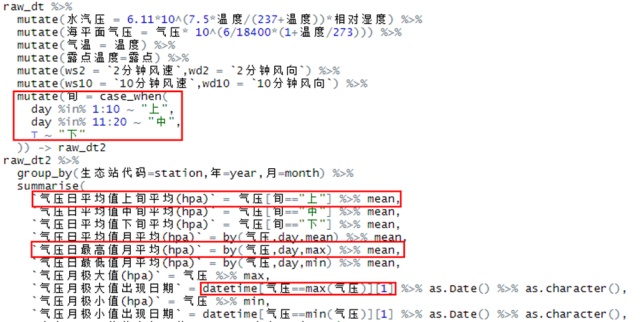
在summarise函数中使用by函数可以继续汇总,不过要保证汇总之后你还需要继续汇总,因为summarise函数终只能够返回一个值。同样,使用方括号的方法也能够实现定制化的组内汇总。
后不能不提的是,必须要把处理好的数据再次导入到多工作表的Excel中,这个任务我在以前都还是先导出为csv文件然后再复制粘贴的,但是这次的工作量太大,显然是不实际的。这时候我花了一点时间认真地学了一下openxlsx这个包,仅仅几个函数,就让这个任务变得便捷无比。链接如下:
CRAN - Package openxlsx这个包近一个月被下载20万+次,不是开玩笑。我主要用到了以下三个函数:
- loadWorkbook(读取)
- writeData(写入工作表)
- saveWorkbook(保存)
就是这么简单的几个函数,威力却极为巨大。对于xlsx文件来说,openxlsx无疑已经登峰造极了,不依赖Java,使用Rcpp加速。不过因为我要进行多次存取,对Excel文件的存取依然是相对费时的,建议使用二进制来进行读取,我这里用了readr包的的read/write_rds函数进行工作簿对象的读写。内存占用会稍微大一点(对于计算机来说空间没有时间重要),但是读写速度会非常快。
对于需要使用Excel进行批处理的小伙伴,这里强推openxlsx这个包,能够对多工作表的工作簿进行批量化读入写出,过程可以说是具备半自动化智能,真乃神器!
