FTEN,有人问美国阿帕奇Trafodion如何TM(孵化)栈对如Oracle,IBM DB2,微软SQL服务器,Informix的,MySQL和PostgreSQL,Teradata和一方面是其他关系数据库的数据库,并针对SQL-ON- Hadoop解决方案,例如Impala,Tez,Hive,Drill,Presto等。
Apache Trafodion是世界的数据库,与上面列出的关系数据库相比,堆叠得很好。每个数据库都具有另一个数据库所没有的功能。如果您正在从一种数据库技术转移到另一种数据库技术,那么除非您虔诚地仅使用ANSI SQL功能,否则您将面临与Trafodion相同的挑战。但是,如果您正在Trafodion上开发新的应用程序,那么您会发现它支持数据库通常所需的所有功能。
与其他SQL-on-Hadoop技术相比,Trafodion具有出色的数据库引擎,具有更多的功能。的区别在于Trafodion当前针对其进行了优化的工作负载类型。这并非缺乏能力。取而代之的是,当前使用Apache HBase TM的项目重点更适合于操作工作负载。相同的数据库技术在不同的存储引擎上运行,是为惠普提供巨大的EDW的强大动力,EDW包括三个250TB系统,每天运行数以万计的ELT并报告查询,其中数百个同时运行。
但是没有简单的答案。我希望这篇文章可以阐明为什么要使用Trafodion。
从OLTP到分析的工作量
企业IT数据库部署在处理的工作负载类型方面有所不同。一种简化是将这些工作负载分类为运营,业务智能和分析。运营通常意味着在线交易处理(OLTP)或运营数据存储(ODS)。为了简化术语,尽管有很多这样的简化方式,但操作工作负载有助于公司的日常运营,而BI和Analytic工作负载则有助于提高业务效率或改进业务,从而提高客户满意度,产品和服务。改善,更高的收入,更好的利润率,更多的增长等。由于这些工作负载之间存在多种差异,因此这些工作负载由不同的软件和硬件架构托管 以及针对特定工作负载的优化。人们可以争论这些工作负载之间的界限是什么,但是它们之间的差异可能可以归类为以下几种:


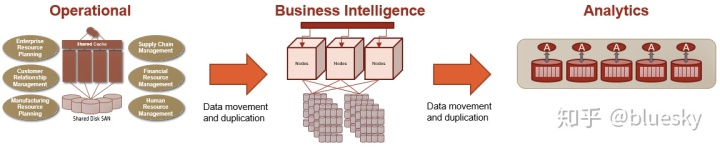
在这种工作负载范围内,我们过去看到的典型部署如下:
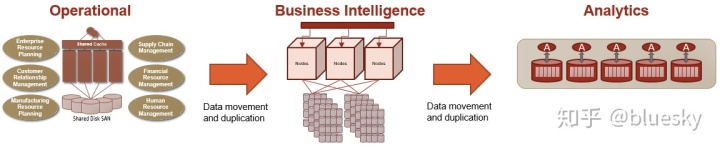

大多数操作部署都在具有共享缓存和磁盘的SMP体系结构上。还有一些例外,例如具有可扩展MPP架构的NonStop。从数据库角度来看,您通常会看到在Oracle或Oracle RAC,IBM DB2,Microsoft SQL Server以及开源数据库(例如MySQL和PostgreSQL)上部署的相对标准化的数据模型。这些环境中托管的应用程序本质上是OLTP或大多数是事务性的。
然后,将数据复制到商业智能环境中,在该环境中将其转换为维度模型。因为数据是历史数据,并且并行访问是获得良好性能的关键,所以这些系统通常部署在MPP体系结构(例如Teradata和Oracle Exadata)上。
运营数据存储区位于OLTP和BI之间。根据ODS托管的工作负载的性质,可以将它们部署在这两组平台中的任何一个上。一个人可以描述ODS和BI工作负载之间的区别,因为ODS工作负载涉及特定于客户,供应商,产品等的查询。因此,在这种意义上,它们更多地包含在对数据库的访问中。尽管BI工作负载主要跨越特定的客户,供应商和产品类型边界,但在访问多个维度上的大量数据时,查询却比典型的ODS所看到的更为复杂。
从BI出发,如果您想进行分析(例如应用统计分析,数据挖掘算法,机器学习算法,时间序列分析,会话化等),则将数据复制并聚合到针对此类工作负载优化的分析平台。这些是MPP部署,提供列式存储,将并行分析推送到数据库中以及其他功能,以促进分析。这些示例包括Vertica,Aster Data,Greenplum和Netezza。
大数据的BI和分析
随着大数据的到来,各种数据(例如外部社交数据或物联网(IoT)数据)已成为企业不可或缺的一部分,为提高业务绩效提供了进一步的见解。该数据可以被结构化,但实际上已经变得半结构化或非结构化。这可能包括文本消息,Twitter消息,电子邮件,音频或视频文件或来自各种设备的数据。这些数据越来越多地托管在具有MPP架构,可弹性伸缩和复制以实现高可用性的Hadoop平台上。数据映射到MVCC(多版本并发控制)或仅附加Hadoop文件系统(HDFS)结构。
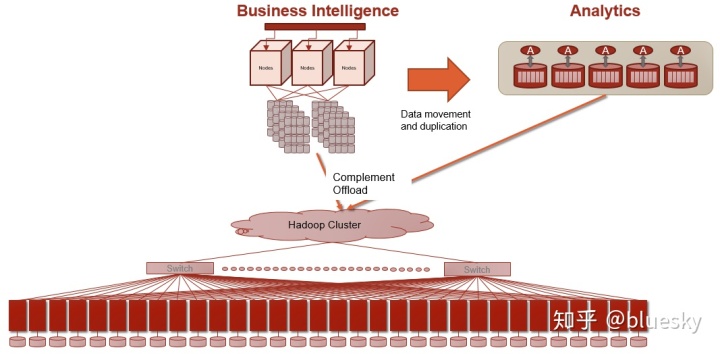
到目前为止,BI类型报告和分析工作负载一直是Hadoop部署的主要重点。这些本质上是对先前讨论的BI和Analytics平台上运行的内容的补充。外部数据通常是对那些平台上结构化数据的补充。结构化数据通常在操作系统内部在企业内部生成。在这一领域,诸如Hortonworks与Apache Tez,Apache Hive,Impala与Cloudera,Drill,Presto和Databricks与Spark一起提供了各种功能,它们利用了JSON文档存储,Avro,ORC文件和Parquet等基础结构(后两个是列式商店)。
但是随着Hadoop平台和这些工具的日趋成熟,将来自现有BI和Analytics平台的一些结构化数据与Hadoop上的数据进行集成以获取更好的见解的需求日益增加。由于Hadoop和开源部署的总拥有成本(TCO)较低,因此其中一些工作负载已从典型的BI和Analytics平台转移到Hadoop上。
OLTP和ODS现在在Hadoop上
但是操作工作量呢?许多操作性工作负载,无论是Web规模的事务性工作负载,还是操作性数据存储工作负载,也可以利用Hadoop平台来降低总拥有成本,降低弹性规模和复制以实现高可用性。企业资源计划(ERP),客户关系管理(CRM),制造资源计划(MRP),供应链管理(SCM),财务资源管理(FRM)和人力资源管理(HRM)系统经常需要可以以较低的总体拥有成本(TCO)扩展到SMP系统之外。


Hadoop将帮助扩展功能,或从这些关键任务环境中卸载工作负载。将较少任务关键的OLTP工作负载/应用程序移至Hadoop将抑制这些专有部署的增长,并保证在那些环境中运行的任务关键型应用程序具有更好的SLA。在Hadoop上,可操作的数据存储部署还可以使客户访问比其当前可能可用的更多历史数据。随着时间的流逝,随着客户变得越来越舒适,他们也可以开始在Hadoop上部署关键任务应用程序。
这就是针对Apache Trafodion TM(孵化)进行了优化的工作量。Trafodion提供跨多个行,表和语句的完整ACID事务处理功能。它提供了广泛的ANSI SQL支持,因此您可以利用当前的SQL技能和工具,并且可以更轻松地转换和现代化当前的应用程序,或构建新的应用程序。它具有一个非常复杂的数据库引擎,可以处理跨越事务更新,操作查询的工作负载,并一直使用Apace HBase TM作为存储引擎来报告工作负载。
Apache Trafodion TM价值主张
您可能会考虑对应用程序进行转换或现代化,以便通过更轻松地将半结构化和非结构化数据与结构化数据集成在一起,为客户或内部业务用户提供更多功能和更丰富的界面,因为所有数据都位于相同的平台。而且,一旦在Trafodion中捕获了数据,就可以利用整个Hadoop生态系统,无延迟地进行报告和分析。对于闭环分析,您可以生成分析模型,然后将其部署在Trafodion托管的应用程序中。无需从其他平台复制数据。可以在运营,历史和分析工作负载之间共享参考数据。由于数据的运营维度可用,因此BI和Google Analytics(分析)可以获取更多见解,以及历史和外部环境。它还具有基于BI和分析得出的情报快速采取操作措施的能力。这超出了Hadoop固有的弹性规模和低TCO优势。
