1 иғҢжҷҜ
жҲ‘们зҡ„дёҡеҠЎжңҚеҠЎйҡҸзқҖеҠҹиғҪ规模жү©еӨ§пјҢз”ЁжҲ·йҮҸжү©еўһпјҢжөҒйҮҸзҡ„дёҚж–ӯзҡ„еўһй•ҝпјҢз»ҸеёёдјҡйҒҮеҲ°дёҖдёӘй—®йўҳпјҢе°ұжҳҜж•°жҚ®еӯҳеӮЁжңҚеҠЎе“Қеә”еҸҳж…ўгҖӮ
еҜјиҮҙж•°жҚ®еә“жңҚеҠЎеҸҳж…ўзҡ„иҜұеӣ еҫҲеӨҡпјҢиҖҢRDйҮҚиҰҒзҡ„е·ҘдҪңд№ӢдёҖе°ұжҳҜжүҫеҲ°й—®йўҳ并解еҶій—®йўҳгҖӮ
дёӢйқўд»ҘMySQLдёәдҫӢеӯҗпјҢжҲ‘们д»ҺеҮ дёӘи§’еәҰеҲҶжһҗеҸҜиғҪдә§з”ҹеҺҹеӣ пјҢ并讨и®әи§ЈеҶізҡ„ж–№жЎҲгҖӮ
2 е®ҡдҪҚж…ўжҹҘиҜўзҡ„еҺҹеӣ 并дјҳеҢ–
2.1 ж…ўжҹҘиҜўзҡ„еҲҶжһҗ
ејҖеҗҜSlowLogпјҢй»ҳи®ӨжҳҜе…ій—ӯзҡ„пјҢз”ұеҸӮж•°slow_query_logеҶіе®ҡпјҢеңЁMySQLе‘Ҫд»Өз»Ҳз«Ҝдёӯиҫ“е…ҘдёӢйқўзҡ„е‘Ҫд»Өпјҡ
# жҳҜеҗҰејҖеҗҜпјҢиҝҷиҫ№дёәејҖеҗҜпјҢй»ҳи®Өжғ…еҶөдёӢжҳҜoff
set global slow_query_log=on;
# и®ҫзҪ®ж…ўжҹҘиҜўйҳҲеҖјпјҢеҚ•дҪҚжҳҜ sпјҢй»ҳи®Өдёә10sпјҢиҝҷиҫ№зҡ„ж„ҸжҖқжҳҜжҹҘиҜўиҖ—ж—¶и¶…иҝҮ0.5sпјҢдҫҝдјҡи®°еҪ•еҲ°ж…ўжҹҘиҜўж—Ҙеҝ—йҮҢйқў
set global long_query_time=0.5;
# зЎ®е®ҡж…ўжҹҘиҜўж—Ҙеҝ—зҡ„ж–Ү件еҗҚе’Ңи·Ҝеҫ„
mysql> show global variables like 'slow_query_log_file';
+---------------------+-------------------------------------------------------+
| Variable_name | Value |
+---------------------+-------------------------------------------------------+
| slow_query_log_file | /usr/local/mysql/data/MacintoshdeMacBook-Pro-slow.log |
+---------------------+-------------------------------------------------------+
1 row in set (0.00 sec)
# жЈҖжҹҘж…ўжҹҘиҜўзҡ„иҜҰз»ҶжҢҮж ҮпјҢеҸҜд»ҘзңӢеҲ°дёӢйқў slow_query_log = ONпјҢlong_query_time = 0.5 пјҢйғҪжҳҜеӣ дёәжҲ‘们и°ғж•ҙиҝҮзҡ„
mysql> show global variables like '%quer%';
+----------------------------------------+-------------------------------------------------------+
| Variable_name | Value |
+----------------------------------------+-------------------------------------------------------+
| binlog_rows_query_log_events | OFF |
| ft_query_expansion_limit | 20 |
| have_query_cache | NO |
| log_queries_not_using_indexes | OFF |
| log_throttle_queries_not_using_indexes | |
| long_query_time | 0.500000 |
| query_alloc_block_size | 8192 |
| query_prealloc_size | 8192 |
| slow_query_log | ON |
| slow_query_log_file | /usr/local/mysql/data/MacintoshdeMacBook-Pro-slow.log |
+----------------------------------------+-------------------------------------------------------+
10 rows in set (0.01 sec)
й…ҚзҪ®еҘҪд№ӢеҗҺпјҢе°ұдјҡжҢүз…§йҳҲеҖјй»ҳи®ӨжҠҠж…ўжҹҘиҜўж—Ҙеҝ—收йӣҶдёӢжқҘпјҢеҸҜд»ҘеҲ°еҜ№еә”зҡ„зӣ®еҪ•дёӢеҲҶжһҗе…·дҪ“зҡ„ж…ўиҜ·жұӮеҺҹеӣ гҖӮ
2.2 дҪҝз”ЁExplainиҝӣиЎҢжҹҘиҜўиҜӯеҸҘеҲҶжһҗ
2.2.1 еҲҶжһҗиҝҮзЁӢдёҫдҫӢ
еҫҲеӨҡж—¶еҖҷжҲ‘们еңЁиҜ„е®ЎRDеҗҢеӯҰд»Јз Ғе’ҢSQLи„ҡжң¬зҡ„ж—¶еҖҷпјҢдёҠдёӢж–Үе’ҢдҪҝз”ЁзҺҜеўғдёҚдәҶи§ЈпјҢдёҚиғҪеҒҡеҮәеҫҲеҮҶзЎ®зҡ„еҲӨж–ӯгҖӮ
иҝҷж—¶еҖҷдҪҝз”ЁExplainеҲҶжһҗSQLзҡ„жү§иЎҢи®ЎеҲ’е°ұжҳҫеҫ—йқһеёёжңүз”ЁпјҢжӢҝеҲ°е…·дҪ“зҺҜеўғдёӯRunдёҖдёӢе°ұиғҪзңӢеҮәеҫҲеӨҡй—®йўҳгҖӮ
дёҫдёӘдҫӢеӯҗпјҡ
жЁЎжӢҹдёҖдёӘеҚғдёҮзә§еҲ«зҡ„йӣҮе‘ҳиЎЁпјҢжҲ‘们еңЁжІЎжңүеҒҡзҙўеј•зҡ„еӯ—ж®өдёҠеҒҡдёҖдёӢжҹҘиҜўзңӢзңӢпјҢеңЁ500Wж•°жҚ®дёӯжҹҘиҜўдёҖдёӘеҗҚеҸ«LsHfFJAзҡ„е‘ҳе·ҘпјҢж¶ҲиҖ— 2.239S пјҢиҺ·еҸ–еҲ°дёҖжқЎidдёә4582071зҡ„ж•°жҚ®гҖӮ
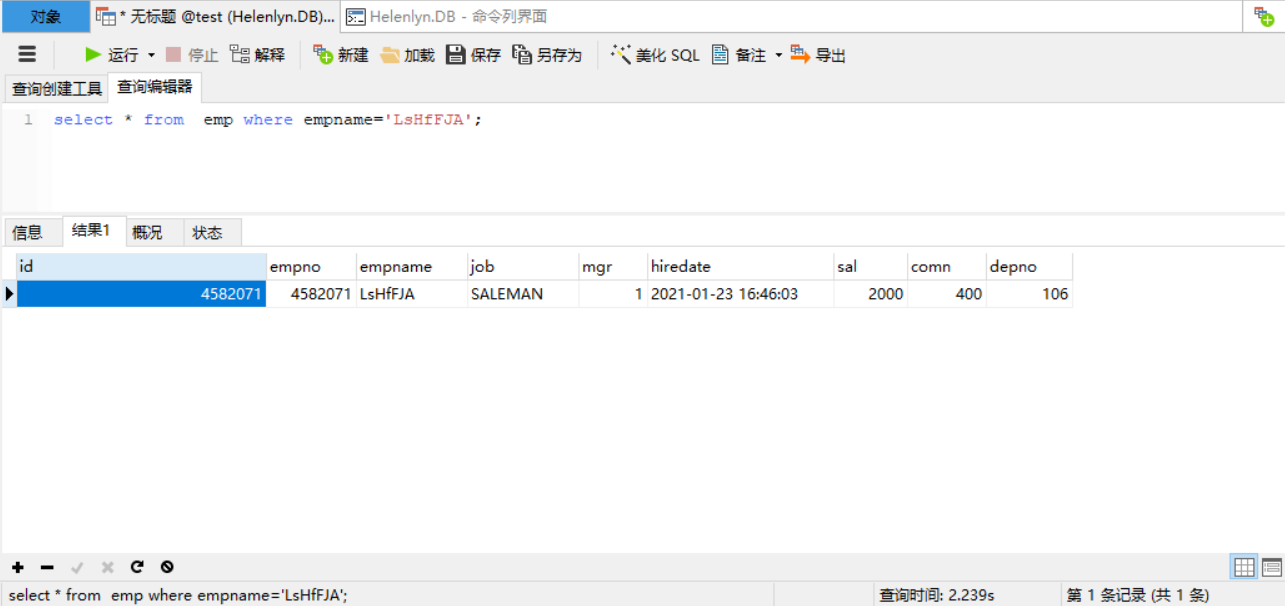
еҶҚзңӢзңӢд»–зҡ„жү§иЎҢи®ЎеҲ’пјҢжү«жҸҸдәҶ4952492 жқЎж•°жҚ®жүҚжүҫеҲ°иҜҘиЎҢж•°жҚ®пјҡ
mysql> explain select * from emp where empname='LsHfFJA';
+----+-------------+-------+------+---------------+------+---------+------+---------+-------------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------+------+---------------+------+---------+------+---------+-------------+
| 1 | SIMPLE | emp | ALL | NULL | NULL | NULL | NULL | 4952492 | Using where |
+----+-------------+-------+------+---------------+------+---------+------+---------+-------------+
1 row in set
иҝҷе°ұжҳҜж— зҙўеј•жҲ–иҖ…зҙўеј•дёҚеҗҲзҗҶзҡ„з»“жһңпјҢиҝҷдёӘж—¶еҖҷжҲ‘们е°ұеҸҜд»Ҙж №жҚ®е®һйҷ…жғ…еҶөиҝӣиЎҢжҹҘиҜўдјҳеҢ–дәҶгҖӮ
2.2.2 ExplainйңҖиҰҒе…іжіЁзҡ„жҢҮж Ү
жҜ”иҫғж ёеҝғиҰҒе…іжіЁзҡ„еӯ—ж®өдёҖиҲ¬жңү select_typeгҖҒtypeгҖҒpossible_keysгҖҒkeyгҖҒrowsгҖҒExtraзӯү
жҲ‘们жқҘдёҖдёӘдёӘиҜҙжҳҺпјҡ
- select_typeпјҡд»ЈиЎЁиЎЁзӨәжҹҘиҜўдёӯжҜҸдёӘselectеӯҗеҸҘзҡ„зұ»еһӢпјҢжҳҜз®ҖеҚ•жҹҘиҜўиҝҳжҳҜиҒ”еҗҲжҹҘиҜўиҝҳжҳҜеӯҗжҹҘиҜўпјҢдёҖзӣ®дәҶ然гҖӮе’ұ们дёҠйқўзҡ„дҫӢеӯҗжҳҜSIMPLEпјҢд»ЈиЎЁз®ҖеҚ•жҹҘиҜўпјҢе…¶д»–жһҡдёҫеҸӮиҖғдёӢеҲ—иЎЁж јпјҡ
| select_typeзҡ„еҖј | и§ЈйҮҠ |
|---|---|
| SIMPLE | з®ҖеҚ•жҹҘиҜўпјҲдёҚдҪҝз”Ёе…іиҒ”жҹҘиҜўжҲ–еӯҗжҹҘиҜўпјү |
| PRIMARY | еҰӮжһңеҢ…еҗ«е…іиҒ”жҹҘиҜўжҲ–иҖ…еӯҗжҹҘиҜўпјҢеҲҷеӨ–еұӮзҡ„жҹҘиҜўйғЁеҲҶж Үи®°primary |
| UNION | иҒ”еҗҲжҹҘиҜўпјҲUNIONпјүдёӯ第дәҢдёӘеҸҠеҗҺйқўзҡ„жҹҘиҜў |
| DEPENDENT UNION | UNIONдёӯзҡ„第дәҢдёӘжҲ–еҗҺйқўзҡ„SELECTиҜӯеҸҘпјҢеҸ–еҶідәҺеӨ–йқўзҡ„жҹҘиҜў |
| UNION RESULT | UNIONзҡ„з»“жһңпјҢunionиҜӯеҸҘдёӯ第дәҢдёӘselectејҖе§ӢеҗҺйқўжүҖжңүselect |
| SUBQUERY | еӯ—жҹҘиҜўдёӯзҡ„дёӘж“Ұи®Ҝ |
| DEPENDENT SUBQUERY | еӯҗжҹҘиҜўдёӯзҡ„дёӘжҹҘиҜўпјҢ并且дҫқиө–еӨ–йғЁжҹҘиҜў |
| DERIVED | жҙҫз”ҹиЎЁзҡ„SELECT, FROMеӯҗеҸҘзҡ„еӯҗжҹҘиҜў |
| MATERIALIZED | иў«зү©еҢ–зҡ„еӯҗжҹҘиҜў |
| UNCACHEABLE SUBQUERY | дёҖдёӘеӯҗжҹҘиҜўзҡ„з»“жһңдёҚиғҪиў«зј“еӯҳпјҢеҝ…йЎ»йҮҚж–°иҜ„дј°еӨ–й“ҫжҺҘзҡ„иЎҢ |
- typeпјҡиЎЁзӨәMySQLеңЁиЎЁдёӯжҹҘжүҫжүҖйңҖж•°жҚ®зҡ„ж–№ејҸпјҢд№ҹз§°вҖңи®ҝй—®зұ»еһӢвҖқпјҢе’ұ们дёҠйқўзҡ„дҫӢеӯҗжҳҜAllпјҢд»ЈиЎЁе…ЁиЎЁжү«жҸҸпјҢжҳҜйқһеёёе·®зҡ„жЁЎејҸпјҢе…¶д»–жһҡдёҫеҸӮиҖғдёӢеҲ—иЎЁж јпјҡ
| typeзҡ„еҖј | и§ЈйҮҠ |
|---|---|
| system | жҹҘиҜўеҜ№иұЎиЎЁеҸӘжңүдёҖиЎҢж•°жҚ®пјҢдё”еҸӘиғҪз”ЁдәҺMyISAMе’ҢMemoryеј•ж“Һзҡ„иЎЁпјҢиҝҷжҳҜеҘҪзҡ„жғ…еҶө |
| const | еҹәдәҺдё»й”®жҲ–зҙўеј•жҹҘиҜўпјҢеӨҡиҝ”еӣһдёҖжқЎз»“жһң |
| eq_ref | зұ»дјјrefпјҢеҢәеҲ«е°ұеңЁдҪҝз”Ёзҡ„зҙўеј•жҳҜзҙўеј•пјҢеҜ№дәҺжҜҸдёӘзҙўеј•й”®еҖјпјҢиЎЁдёӯеҸӘжңүдёҖжқЎи®°еҪ•еҢ№й…ҚпјҢз®ҖеҚ•жқҘиҜҙпјҢе°ұжҳҜеӨҡиЎЁиҝһжҺҘдёӯдҪҝз”Ёprimary keyжҲ–иҖ… unique keyдҪңдёәе…іиҒ”жқЎд»¶ |
| ref | иЎЁзӨәдёҠиҝ°иЎЁзҡ„иҝһжҺҘеҢ№й…ҚжқЎд»¶пјҢеҚіе“ӘдәӣеҲ—жҲ–еёёйҮҸиў«з”ЁдәҺжҹҘжүҫзҙўеј•еҲ—дёҠзҡ„еҖј |
| fulltext | е…Ёж–ҮжЈҖзҙў |
| ref_or_null | иЎЁиҝһжҺҘзұ»еһӢжҳҜrefпјҢдҪҶиҝӣиЎҢжү«жҸҸзҡ„зҙўеј•еҲ—дёӯеҸҜиғҪеҢ…еҗ«NULLеҖј |
| index_merge | еҲ©з”ЁеӨҡдёӘзҙўеј• |
| unique_subquery | еӯҗжҹҘиҜўдёӯдҪҝз”Ёзҙўеј• |
| index_subquery | еӯҗжҹҘиҜўдёӯдҪҝз”Ёжҷ®йҖҡзҙўеј• |
| range | еҸӘжЈҖзҙўз»ҷе®ҡиҢғеӣҙзҡ„иЎҢпјҢдҪҝз”ЁдёҖдёӘзҙўеј•жқҘйҖүжӢ©иЎҢ |
| index | Full Index ScanпјҢindexдёҺALLеҢәеҲ«дёәindexзұ»еһӢеҸӘйҒҚеҺҶзҙўеј•ж ‘ |
| ALL | Full Table ScanпјҢ MySQLе°ҶйҒҚеҺҶе…ЁиЎЁд»ҘжүҫеҲ°еҢ№й…Қзҡ„иЎҢ |
- possible_keysпјҡеә”иҜҘжҲ–е»әи®®дҪҝз”Ёзҡ„зҙўеј•
иЎЁзӨәMySQLиғҪдҪҝз”Ёе“ӘдёӘзҙўеј•еңЁиЎЁдёӯжүҫеҲ°и®°еҪ•пјҢжҹҘиҜўж¶үеҸҠеҲ°зҡ„еӯ—ж®өдёҠиӢҘеӯҳеңЁзҙўеј•пјҢеҲҷиҜҘзҙўеј•е°Ҷиў«еҲ—еҮәпјҢдҪҶдёҚдёҖе®ҡиў«жҹҘиҜўдҪҝз”ЁгҖӮиҝҷдёӘи¶Ӣеҗ‘дәҺжҢҮеҜјжҖ§дҪңз”ЁгҖӮ
- keyпјҡе®һйҷ…дҪҝз”Ёзҡ„зҙўеј•пјҢжІЎжңүзҡ„жғ…еҶөдёӢдёәNULL
жҳҫзӨәMySQLеңЁжҹҘиҜўдёӯе®һйҷ…дҪҝз”Ёзҡ„зҙўеј•пјҢиӢҘжІЎжңүдҪҝз”Ёзҙўеј•пјҢжҳҫзӨәдёәNULL
- rowsпјҡйў„дј°жү«жҸҸдәҶдәҶеӨҡе°‘иЎҢпјҢе’ұ们дёҠйқўзҡ„дҫӢеӯҗ 4952492 пјҢйқһеёёдёҚеҗҲзҗҶгҖӮ
иЎЁзӨәMySQLж №жҚ®иЎЁз»ҹи®ЎдҝЎжҒҜеҸҠзҙўеј•йҖүз”Ёжғ…еҶөпјҢдј°з®—зҡ„жүҫеҲ°жүҖйңҖзҡ„и®°еҪ•жүҖйңҖиҰҒиҜ»еҸ–зҡ„иЎҢж•°гҖӮеҹәжң¬иЎЁзҺ°дёәе®һйҷ…жү«жҸҸиҝҮзҡ„иЎҢж•°гҖӮ
3 дёҖдәӣдҪҝз”ЁдёҠзҡ„规иҢғ
3.1 еҲҶжһҗжҳҜеҗҰжңүдёҚеҗҲзҗҶзҡ„жҹҘиҜў
вҳ… д»ҘдёӢжҳҜжҲ‘们еӣўйҳҹзҡ„еҮҶе…Ҙ规иҢғпјҢд№ҹжҳҜCodeReview ж ҮеҮҶгҖӮ
- е°ҪйҮҸйҒҝе…ҚдҪҝз”Ёselect *пјҢjoinиҜӯеҸҘдҪҝз”Ёselect * еҸҜиғҪеҜјиҮҙеҸӘйңҖиҰҒи®ҝй—®зҙўеј•еҚіеҸҜе®ҢжҲҗзҡ„жҹҘиҜўйңҖиҰҒеӣһиЎЁеҸ–ж•°гҖӮ
дёҖз§ҚжҳҜеҸҜиғҪеҸ–еҮәеҫҲеӨҡдёҚйңҖиҰҒзҡ„ж•°жҚ®пјҢеҜ№дәҺе®ҪиЎЁжқҘиҜҙпјҢиҝҷжҳҜзҒҫйҡҫпјӣдёҖз§ҚжҳҜе°ҪеҸҜиғҪйҒҝе…ҚеӣһиЎЁпјҢеӣ дёәеҸ–дёҖдәӣж №жң¬дёҚйңҖиҰҒзҡ„ж•°жҚ®иҖҢеӣһиЎЁеҜјиҮҙжҖ§иғҪдҪҺдёӢпјҢжҳҜеҫҲдёҚеҗҲз®—гҖӮ - дёҘзҰҒдҪҝз”Ёselect * from t_nameпјҢдёҚеҠ д»»дҪ•whereжқЎд»¶пјҢйҒ“зҗҶдёҖж ·пјҢиҝҷж ·дјҡеҸҳжҲҗе…ЁиЎЁе…Ёеӯ—ж®өжү«жҸҸгҖӮ
- MySQLдёӯзҡ„textзұ»еһӢеӯ—ж®өеӯҳеӮЁпјҡ
- дёҚдёҺе…¶д»–жҷ®йҖҡеӯ—ж®өеӯҳж”ҫеңЁдёҖиө·,еӣ дёәиҜ»еҸ–ж•ҲзҺҮдҪҺпјҢд№ҹдјҡеҪұе“Қе…¶д»–иҪ»йҮҸеӯ—ж®өеӯҳеҸ–ж•ҲзҺҮгҖӮеӨ§е®ҪиЎЁгҖҒеӨ§еӯ—ж®өиЎЁпјҢж•ҙдҪ“жҖ§иғҪд№ҹдёҚеҘҪгҖӮ
- еҰӮжһңдёҚйңҖиҰҒtextзұ»еһӢеӯ—ж®өпјҢеҸҲдҪҝз”ЁдәҶselect *пјҢдјҡи®©иҜҘжү§иЎҢж¶ҲиҖ—еӨ§йҮҸioпјҢж•ҲзҺҮд№ҹеҫҲдҪҺдёӢ
- еңЁеҸ–еҮәеӯ—ж®өдёҠеҸҜд»ҘдҪҝз”Ёзӣёе…іеҮҪж•°пјҢдҪҶеә”е°ҪеҸҜиғҪйҒҝе…ҚеҮәзҺ° now() , rand() , sysdate() зӯүдёҚзЎ®е®ҡз»“жһңзҡ„еҮҪж•°пјҢеңЁWhereжқЎд»¶дёӯзҡ„иҝҮж»ӨжқЎд»¶еӯ—ж®өдёҠдёҘзҰҒдҪҝз”Ёд»»дҪ•еҮҪж•°пјҢеҢ…жӢ¬ж•°жҚ®зұ»еһӢиҪ¬жҚўеҮҪж•°гҖӮеӨ§йҮҸзҡ„и®Ўз®—е’ҢиҪ¬жҚўдјҡйҖ жҲҗж•ҲзҺҮдҪҺдёӢпјҢиҝҷдёӘеңЁзҙўеј•йӮЈиҫ№д№ҹжҸҸиҝ°иҝҮдәҶгҖӮ
- еҲҶйЎөжҹҘиҜўиҜӯеҸҘе…ЁйғЁйғҪйңҖиҰҒеёҰжңүжҺ’еәҸжқЎд»¶ , еҗҰеҲҷеҫҲе®№жҳ“еј•иө·д№ұеәҸ
- з”Ёin()/unionжӣҝжҚўorпјҢж•ҲзҺҮдјҡеҘҪдёҖдәӣпјҢ并注ж„Ҹinзҡ„дёӘж•°е°ҸдәҺ300
- дёҘзҰҒдҪҝз”Ё%еүҚзјҖиҝӣиЎҢжЁЎзіҠеүҚзјҖжҹҘиҜўгҖӮ
-- еҰӮдёӢпјҢиҝҷз§ҚжҹҘиҜўдјҡеҜјиҮҙжү«жҸҸиЎЁпјҡ
select a,b,c from t_name where a like '%name';
-- еҸҜд»ҘдҪҝз”Ё%жЁЎзіҠеҗҺзјҖжҹҘиҜўеҰӮпјҡ
select a,b from t_name where a like 'name%';
- е°ҪйҮҸйҒҝе…ҚдҪҝз”ЁеӯҗжҹҘиҜўпјҢеҸҜд»ҘжҠҠеӯҗжҹҘиҜўдјҳеҢ–дёәjoinж“ҚдҪңпјҢйҖҡеёёеӯҗжҹҘиҜўеңЁinеӯҗеҸҘдёӯпјҢдё”еӯҗжҹҘиҜўдёӯдёәз®ҖеҚ•SQL(дёҚеҢ…еҗ«unionгҖҒgroup byгҖҒorder byгҖҒlimitд»ҺеҸҘ)ж—¶пјҢжүҚеҸҜд»ҘжҠҠеӯҗжҹҘиҜўиҪ¬еҢ–дёәе…іиҒ”жҹҘиҜўиҝӣиЎҢдјҳеҢ–гҖӮеӯҗжҹҘиҜўжҖ§иғҪе·®зҡ„еҺҹеӣ пјҡ
- еӯҗжҹҘиҜўзҡ„з»“жһңйӣҶж— жі•дҪҝз”Ёзҙўеј•пјҢйҖҡеёёеӯҗжҹҘиҜўзҡ„з»“жһңйӣҶ*дјҡиў«еӯҳеӮЁеҲ°дёҙж—¶иЎЁдёӯпјҢдёҚи®әжҳҜеҶ…еӯҳдёҙж—¶иЎЁиҝҳжҳҜзЈҒзӣҳдёҙж—¶иЎЁйғҪдёҚдјҡеӯҳеңЁзҙўеј•пјҢжүҖд»ҘжҹҘиҜўжҖ§иғҪдјҡеҸ—еҲ°дёҖе®ҡзҡ„еҪұе“Қпјӣ
- зү№еҲ«жҳҜеҜ№дәҺиҝ”еӣһз»“жһңйӣҶжҜ”иҫғеӨ§зҡ„еӯҗжҹҘиҜўпјҢе…¶еҜ№жҹҘиҜўжҖ§иғҪзҡ„еҪұе“Қд№ҹе°ұи¶ҠеӨ§пјӣ
- з”ұдәҺеӯҗжҹҘиҜўдјҡдә§з”ҹеӨ§йҮҸзҡ„дёҙж—¶иЎЁд№ҹжІЎжңүзҙўеј•пјҢжүҖд»Ҙдјҡж¶ҲиҖ—иҝҮеӨҡзҡ„CPUе’ҢIOиө„жәҗпјҢдә§з”ҹеӨ§йҮҸзҡ„ж…ўжҹҘиҜўгҖӮ
- еңЁеӨҡиЎЁjoinдёӯпјҢе°ҪйҮҸйҖүеҸ–з»“жһңйӣҶиҫғе°Ҹзҡ„иЎЁдҪңдёәй©ұеҠЁиЎЁпјҢжқҘjoinе…¶д»–иЎЁгҖӮ
- еҲҶйЎөжҹҘиҜўпјҢеҪ“limitиө·зӮ№иҫғй«ҳж—¶пјҢеҸҜе…Ҳз”ЁиҝҮж»ӨжқЎд»¶иҝӣиЎҢиҝҮж»ӨпјҢеҰӮдёӢгҖӮеҺҹзҗҶеҸӮиҖғиҝҷзҜҮ
-- еҰӮ
select a,b,c from t1 limit 10000,20;
-- дјҳеҢ–дёә:
select a,b,c from t1 where id>10000 limit 20;
3.2 жЈҖжҹҘжҳҜеҗҰжңүдёҚеҗҲзҗҶзҡ„зҙўеј•дҪҝз”Ё
е»әи®®еҸӮиҖғ笔иҖ…иҝҷзҜҮгҖҠжһ„е»әй«ҳжҖ§иғҪзҙўеј•пјҲзӯ–з•ҘзҜҮпјүгҖӢпјҢжҜ”иҫғе®Ңж•ҙ
- зҙўеј•еҢәеҲҶеәҰпјҲ> 0.2пјү
зҙўеј•еҝ…йЎ»еҲӣе»әеңЁзҙўеј•йҖүжӢ©жҖ§пјҲеҢәеҲҶеәҰпјүиҫғй«ҳзҡ„еҲ—дёҠпјҢйҖүжӢ©жҖ§зҡ„и®Ўз®—ж–№ејҸдёә:
selecttivity = count(distinct c_name)/count(*) ;
еҰӮжһңеҢәеҲҶеәҰз»“жһңе°ҸдәҺ0.2пјҢеҲҷдёҚе»әи®®еңЁжӯӨеҲ—дёҠеҲӣе»әзҙўеј•пјҢеҗҰеҲҷеӨ§жҰӮзҺҮдјҡжӢ–ж…ўSQLжү§иЎҢ
- йҒөеҫӘе·ҰеүҚзјҖпјҢе°Ҷзҙўеј•еҢәеҲҶеәҰй«ҳзҡ„ж”ҫеңЁе·Ұиҫ№
еҜ№дәҺзЎ®е®ҡйңҖиҰҒз»„жҲҗз»„еҗҲзҙўеј•зҡ„еӨҡдёӘеӯ—ж®өпјҢи®ҫи®Ўж—¶е»әи®®е°ҶйҖүжӢ©жҖ§й«ҳзҡ„еӯ—ж®өйқ еүҚж”ҫгҖӮдҪҝз”Ёж—¶пјҢз»„еҗҲзҙўеј•зҡ„йҰ–еӯ—ж®өпјҢеҝ…йЎ»еңЁwhereжқЎд»¶дёӯпјҢдё”йңҖиҰҒжҢүз…§е·ҰеүҚзјҖ规еҲҷеҺ»еҢ№й…ҚгҖӮ
жӯЈзЎ®зҗҶи§Је’Ңи®Ўз®—зҙўеј•еӯ—ж®өзҡ„еҢәеҲҶеәҰпјҢж–Үдёӯжңү计算规еҲҷпјҢеҢәеҲҶеәҰй«ҳзҡ„зҙўеј•пјҢеҸҜд»Ҙеҝ«йҖҹеҫ—е®ҡдҪҚж•°жҚ®пјҢеҢәеҲҶеәҰеӨӘдҪҺпјҢж— жі•жңүж•Ҳзҡ„еҲ©з”Ёзҙўеј•пјҢеҸҜиғҪйңҖиҰҒжү«жҸҸеӨ§йҮҸж•°жҚ®йЎөпјҢе’ҢдёҚдҪҝз”Ёзҙўеј•жІЎд»Җд№Ҳе·®еҲ«гҖӮ
зҰҒжӯўдҪҝз”ЁеӨ–й”®пјҢеҸҜд»ҘеңЁзЁӢеәҸзә§еҲ«жқҘзәҰжқҹе®Ңж•ҙжҖ§
varcharгҖҒtextзұ»еһӢеӯ—ж®өеҰӮжһңйңҖиҰҒеҲӣе»әзҙўеј•пјҢеҝ…йЎ»дҪҝз”ЁеүҚзјҖзҙўеј•гҖӮ
еүҚзјҖзҙўеј•и®Ўз®—е…¬ејҸеҰӮдёӢпјҢcalcul_len жҳҜж•°еӯ—пјҢй•ҝеәҰдёә1 ~ c_nameеӯ—ж®өзҡ„й•ҝеҖјпјҢеҸҜд»ҘйҖҗдёҖжҜ”иҫғпјҢеҜ№жҜ”еҢәеҲҶеәҰй«ҳзҡ„еҮәжқҘ
жӯЈзЎ®зҗҶи§Је’Ңи®Ўз®—еүҚзјҖзҙўеј•зҡ„еӯ—ж®өй•ҝеәҰпјҢж–ҮдёӯжңүеҲӨж–ӯ规еҲҷпјҢеҗҲйҖӮзҡ„й•ҝеәҰиҰҒдҝқиҜҒй«ҳзҡ„еҢәеҲҶеәҰе’ҢжҒ°еҪ“зҡ„зҙўеј•еӯҳеӮЁе®№йҮҸпјҢеҸӘжңүиҫҫеҲ°дҪізҠ¶жҖҒпјҢжүҚжҳҜдҝқиҜҒй«ҳж•ҲзҺҮзҡ„зҙўеј•гҖӮ
select count(distinct left(`c_name`,calcul_len))/count(*) from t_name;
- еҚ•еј иЎЁзҡ„зҙўеј•ж•°йҮҸзҗҶи®әдёҠеә”жҺ§еҲ¶еңЁ5дёӘд»ҘеҶ…гҖӮз»ҸеёёжңүеӨ§жү№йҮҸжҸ’е…ҘгҖҒжӣҙж–°ж“ҚдҪңиЎЁпјҢеә”е°ҪйҮҸе°‘е»әзҙўеј•пјҢзҙўеј•е»әз«Ӣзҡ„еҺҹеҲҷзҗҶи®әдёҠжҳҜеӨҡиҜ»е°‘еҶҷзҡ„еңәжҷҜгҖӮ
- ORDER BYпјҢGROUP BYпјҢDISTINCTзҡ„еӯ—ж®өйңҖиҰҒж·»еҠ еңЁзҙўеј•зҡ„еҗҺйқўпјҢеҪўжҲҗиҰҶзӣ–зҙўеј•
- иҒ”еҗҲзҙўеј•жіЁж„Ҹе·ҰеҢ№й…ҚеҺҹеҲҷпјҡжҹҘиҜўж—¶еҝ…йЎ»жҢүз…§д»Һе·ҰеҲ°еҸізҡ„йЎәеәҸеҢ№й…ҚпјҢMySQLдјҡдёҖзӣҙеҗ‘еҸіеҢ№й…Қзҙўеј•зӣҙеҲ°йҒҮеҲ°иҢғеӣҙжҹҘиҜў(>гҖҒ<гҖҒbetweenгҖҒlike)然еҗҺеҒңжӯўеҢ№й…ҚгҖӮеҰӮпјҡ
-- еҰӮжһңе»әз«Ӣ(depno,empname,job)йЎәеәҸзҡ„зҙўеј•пјҢjobжҳҜз”ЁдёҚеҲ°зҙўеј•зҡ„гҖӮ
depno=1 and empname>'' and job=1
- еә”йңҖиҖҢеҸ–зӯ–з•ҘпјҢжҹҘиҜўи®°еҪ•зҡ„ж—¶еҖҷпјҢдёҚиҰҒдёҖдёҠжқҘе°ұдҪҝз”Ё*пјҢеҸӘеҸ–йңҖиҰҒзҡ„ж•°жҚ®пјҢеҸҜиғҪзҡ„иҜқе°ҪйҮҸеҸӘеҲ©з”Ёзҙўеј•иҰҶзӣ–пјҢеҸҜд»ҘеҮҸе°‘еӣһиЎЁж“ҚдҪңпјҢжҸҗеҚҮж•ҲзҺҮгҖӮ
- жӯЈзЎ®еҲӨж–ӯжҳҜеҗҰдҪҝз”ЁиҒ”еҗҲзҙўеј•пјҢеә”йҒҝе…Қзҙўеј•дёӢжҺЁпјҲIPCпјүпјҢеҮҸе°‘еӣһиЎЁж“ҚдҪңпјҢжҸҗеҚҮж•ҲзҺҮгҖӮ
- йҒҝе…Қзҙўеј•еӨұж•Ҳзҡ„еҺҹеҲҷпјҡзҰҒжӯўеҜ№зҙўеј•еӯ—ж®өдҪҝз”ЁеҮҪж•°гҖҒиҝҗз®—з¬Ұж“ҚдҪңпјҢдјҡдҪҝзҙўеј•еӨұж•ҲгҖӮиҝҷжҳҜе®һйҷ…дёҠе°ұжҳҜйңҖиҰҒдҝқиҜҒзҙўеј•жүҖеҜ№еә”еӯ—ж®өзҡ„вҖқе№ІеҮҖеәҰвҖңгҖӮ
- йҒҝе…Қйқһеҝ…иҰҒзҡ„зұ»еһӢиҪ¬жҚўпјҢеӯ—з¬ҰдёІеӯ—ж®өдҪҝз”Ёж•°еҖјиҝӣиЎҢжҜ”иҫғзҡ„ж—¶еҖҷдјҡеҜјиҮҙзҙўеј•гҖӮ
- жЁЎзіҠжҹҘиҜў'%value%'дјҡдҪҝзҙўеј•пјҢеҸҳдёәе…ЁиЎЁжү«жҸҸпјҢеӣ дёәж— жі•еҲӨж–ӯжү«жҸҸзҡ„еҢәй—ҙпјҢдҪҶжҳҜ'value%'жҳҜеҸҜд»Ҙжңүж•ҲеҲ©з”Ёзҙўеј•гҖӮ
- зҙўеј•иҰҶзӣ–жҺ’еәҸеӯ—ж®өпјҢиҝҷж ·еҸҜд»ҘеҮҸе°‘жҺ’еәҸжӯҘйӘӨпјҢжҸҗеҚҮжҹҘиҜўж•ҲзҺҮ
- е°ҪйҮҸзҡ„жү©еұ•зҙўеј•пјҢйқһеҝ…иҰҒдёҚж–°е»әзҙўеј•гҖӮжҜ”еҰӮиЎЁдёӯе·Із»Ҹжңүaзҡ„зҙўеј•пјҢзҺ°еңЁиҰҒеҠ (a,b)зҡ„зҙўеј•пјҢйӮЈд№ҲеҸӘйңҖиҰҒдҝ®ж”№еҺҹжқҘзҡ„зҙўеј•еҚіеҸҜгҖӮ
дёҫдҫӢеӯҗпјҡжҜ”еҰӮдёҖдёӘе“ҒзүҢиЎЁпјҢе»әз«Ӣзҡ„зҡ„зҙўеј•еҰӮдёӢпјҢдёҖдёӘдё»й”®зҙўеј•пјҢдёҖдёӘзҙўеј•
PRIMARYKEY (`id`),
UNIQUEKEY `uni_brand_define` (`app_id`,`define_id`)
е®һйҷ…еңәжҷҜдёӯпјҢе»әи®®д»Јз ҒдәӨеҸүиҜ„е®ЎпјҢеҪ“дҪ еҗҢдәӢдёҡеҠЎд»Јз Ғдёӯзҡ„жЈҖзҙўиҜӯеҸҘеҰӮдёӢзҡ„ж—¶еҖҷпјҢеә”е»әи®®и°ғж•ҙпјҡ
select brand_id,brand_name from ds_brand_system where status=? and define_id=? and app_id=?
е»әи®®ж”№жҲҗеҰӮдёӢпјҡ
select brand_id,brand_name from ds_brand_system where app_id=? and define_id=? and status=?
иҷҪ然иҜҙ MySQLзҡ„жҹҘиҜўдјҳеҢ–еҷЁдјҡж №жҚ®е®һйҷ…зҙўеј•жғ…еҶөиҝӣиЎҢйЎәеәҸдјҳеҢ–пјҢжүҖд»Ҙиҝҷиҫ№дёҚеҒҡејәеҲ¶гҖӮдҪҶжҳҜеҗҢзӯүжқЎд»¶дёӢиҝҳжҳҜжҢүз…§йЎәеәҸиҝӣиЎҢжҺ’еҲ—пјҢжҜ”иҫғжё…жҷ°пјҢ并且иҠӮзңҒжҹҘиҜўдјҳеҢ–еҷЁзҡ„еӨ„зҗҶгҖӮ
4 жҖ»з»“
иҝҷиҫ№д»…д»…жҳҜд»ҺжҹҘиҜўиҜӯеҸҘзҡ„и§’еәҰиҝӣиЎҢеҲҶжһҗпјҢе®һйҷ…дёҠзј“еӯҳжңҚеҠЎеҸҳж…ўзҡ„еҸҜиғҪжҖ§еҫҲеӨҡпјҢдёҚд»…д»…жҳҜж…ўжҹҘиҜўжҖҺд№ҲеҲҶжһҗпјҲSlow LogгҖҒExplainе‘Ҫд»ӨпјүгҖӮиҝҳеә”иҜҘе…Ёйқўзҡ„еҲҶжһҗеҺҹеӣ пјҢ并з»ҷеҮәеӨ„зҗҶж–№жЎҲпјҢеҰӮ еҲҶжһҗSQLи„ҡжң¬еҗҲзҗҶжҖ§гҖҒе»әз«Ӣзҙўеј•жҲ–дјҳеҢ–зҙўеј•гҖҒиҜ»еҶҷеҲҶзҰ»гҖҒеһӮзӣҙ+ж°ҙе№іеҲҶеҢәпјүгҖҒеӨҡиҜ»е°‘еҶҷ/еҶ·ж•°жҚ® еҒҡзј“еӯҳгҖҒдјҳеҢ–ж•°жҚ®еә“зҡ„й”Ғз«һдәүгҖҒж•°жҚ®еә“й…ҚзҪ®и°ғдјҳгҖҒ硬件иө„жәҗеҚҮзә§ зӯүзӯүпјҢеҗҺйқўеҮ зҜҮжҲ‘们慢慢иҜҙгҖӮ
