摘要:本文将介绍业界MPP分布式数据库join查询模型,以及ClickHouse的分布式查询原理解析和Colocate join性能表现。
本文分享自华为云社区《ClickHouse一种高性能分布式join查询模型(Colocate Join)》,作者:tiantangniao 。
ClickHouse是一款开源的面向联机分析处理的列式数据库,具有的压缩率和极速查询性能。ClickHouse支持SQL查询,基于大宽表的聚合分析查询性能非常优异,在特定场景下ClickHouse也具备较优的join性能。本文将介绍业界MPP分布式数据库join查询模型,以及ClickHouse的分布式查询原理解析和Colocate join性能表现。
1. ClickHouse分布式join
ClicHouse分布式join通常涉及到左右表为分布式表,分布式执行过程中需要将数据在节点间进行交换,我们将数据在节点间交换的动作在分布式执行计划中称为数据的流动streaming算子,ClickHouse支持的streaming算子有如下三种:
- Broadcast Join
- Shuffer Join
- Colocate Join
以上种其实是数据广播算子,第二种为数据重分布算子,第三种为数据在本地不需要分布式交换。其实对于ClickHouse来说,说是实现了Shuffle JOIN比较勉强,其只实现了类Broadcast JOIN类型,ClickHouse的当前的分布式join查询框架更多的还是实现了两阶段查询按任务(这里不详细讲解,后续几个章节分别进行展开讲解,大家可以体会),业界MPP数据库分布式join查询框架模型的数据在节点间交换Streaming算子通常为以下几种:

种Gather算子类似于在ClickHouse中的SQL发起initiator节点,阶段在各个节点完成本地join后,会将各节点结果发送给initiator节点进行第二阶段的汇总工作,initiator节点再讲结果发送给客户端;第二种为数据广播,单个节点将自己拥有的数据发送给目标节点,对应到ClickHouse为Broadcast JOIN;第三种为数据重分布,数据重分布会将数据按照一定的重分布规则发送到对应的目标节点,对应到ClickHouse为Shuffer JOIN;后一种数据会在本地进行join,对应到ClickHouse为Colocate join,其不需要数据重分布或广播,节点间和网络上无数据交换和传播,此实现方式的join性能也佳。以下分别将几种join方式在ClickHouse中实现方式进行介绍。
1.1 Shuffer Join
1)有如下分布式Join SQL语句:

2)执行过程如下:
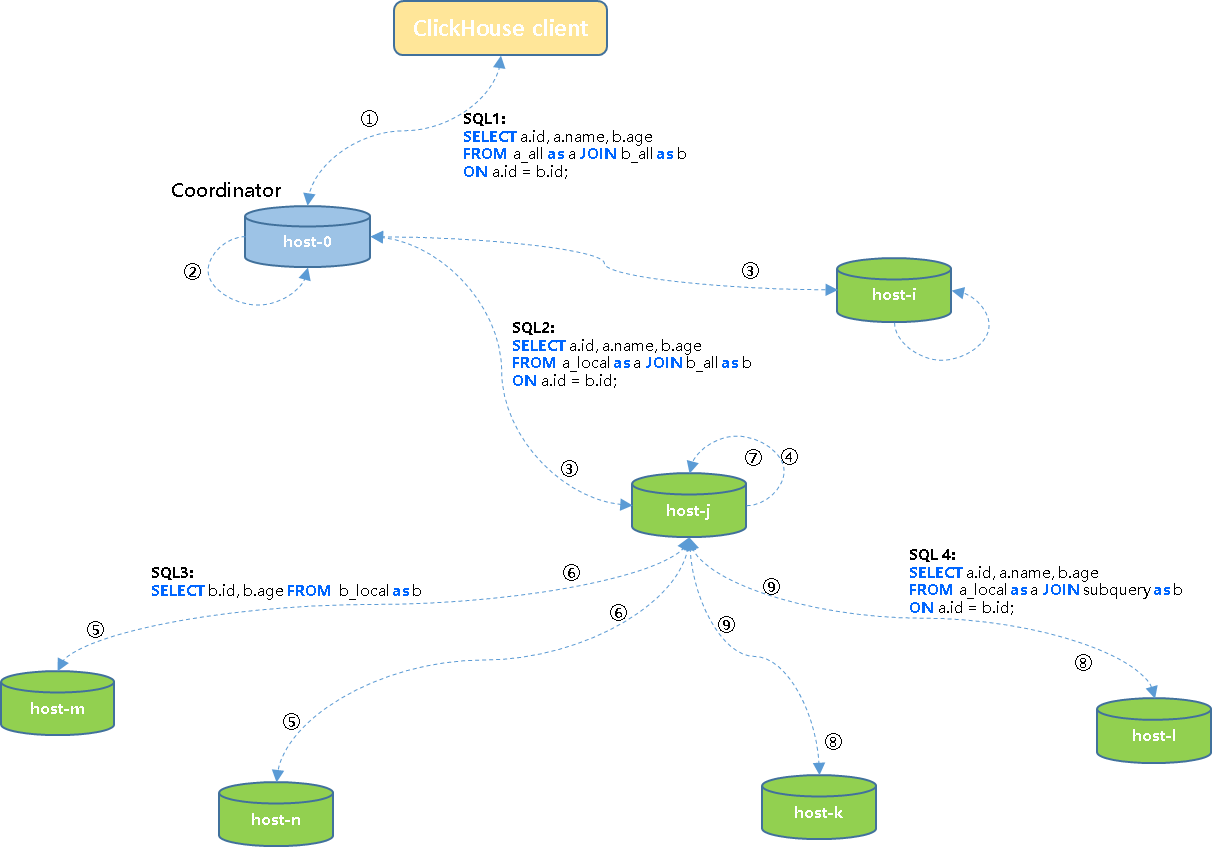
① 客户端将SQL1发送给集群中一个节点host-0(initiator/coordinator);
② host-0节点将任务改写为SQL2查询任务;
③ Coordinator节点将SQL2查询任务下发到集群各个节点执行;
④ 各节点将SQL2解析为SQL3子查询;
⑤ 子查询被下发到所有节点执行;
⑥ 子查询执行完成后将结果集返回到协调节点,如:host-j;
⑦ 协调节点将各个子结果集汇总为一个结果集;
⑧ 协调节点将结果集发送到集群各个节点,同时将SQL4任务下发到各个节点执行;
⑨ 各节点在本地将左表的分片和右表子查询结果集进行join计算,然后将结果返回到客户端。
3)总结:
- ClickHouse 普通分布式JOIN查询并未按JOIN KEY去Shuffle数据,而是每个节点全量拉取右表数据跟左表分片进行join计算;
- 如果右表为分布式表,则集群中每个节点会去执行分布式查询,查询会存在一个非常严重的读放大现象。假设集群有N个节点,右表查询会在集群中执行N*N次;
- ClickHouse 的这种join方式和业界MPP的区别:虽然是叫做Shuffle join/redistribute join,但是从根本来说不是真正的redistribute join,存在查询放大问题,也是性能较差的一种查询方式。
1.2 Broadcast Join
1)有如下分布式Join SQL语句:

2)执行过程如下:
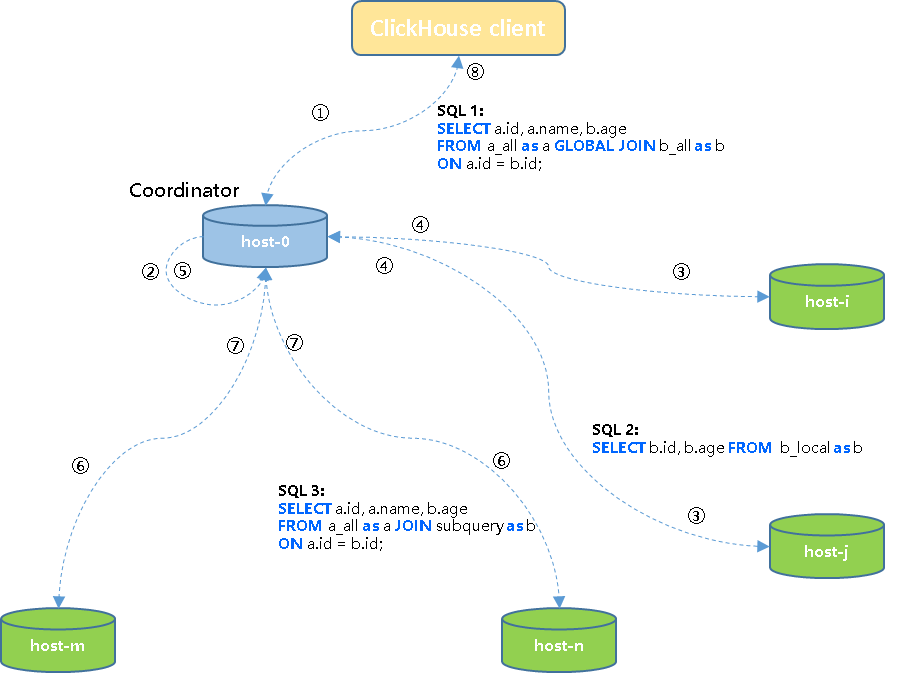
① 客户端将SQL1发送给集群中一个节点host-0(initiator/coordinator);
② host-0节点将任务改写为SQL2子查询任务;
③ Coordinator节点将SQL2子查询任务下发到集群各个节点执行;
④ 各子节点任务执行完成之后将结果发回到协调节点;
⑤ 协调节点将上一步接收到的结果汇总为结果集;
⑥ 协调节点将结果集发送到集群各个节点,同时将SQL3任务下发到各个节点;
⑦ 各节点在本地将左表的分片和右表子查询结果集进行join计算,然后将结果及发回到协调节点;
⑧ 协调节点将终结果返回给客户端。
3)总结:
- 右表的查询在initiator节点完成后,通过网络发送到其他节点,避免其他节点重复计算,从而避免查询放大问题;
- GLOBAL JOIN 可以看做一个不完整的Broadcast JOIN实现。如果JOIN的右表数据量较大,就会占用大量网络带宽,导致查询性能降低;
- ClickHouse的global join方式和业界MPP的区别:
- ClickHouse会将右表过滤结果汇总到一个节点,然后又发送到所有节点,对单节点内存/磁盘空间占用较大,全量数据发送到所有节点,对网络带宽消耗也较大;
- 而业界MPP数据库每个节点并行的将自己一部分数据广播发到所有节点,之后就可以直接进行下一阶段的本地join动作,多个节点都能并行执行,同时数据也不需要从一个节点发送到所有节点,对网络和单节点磁盘及内存消耗较少。
1.3 Colocate Join
1)有如下分布式Join SQL语句:

2)执行过程如下:
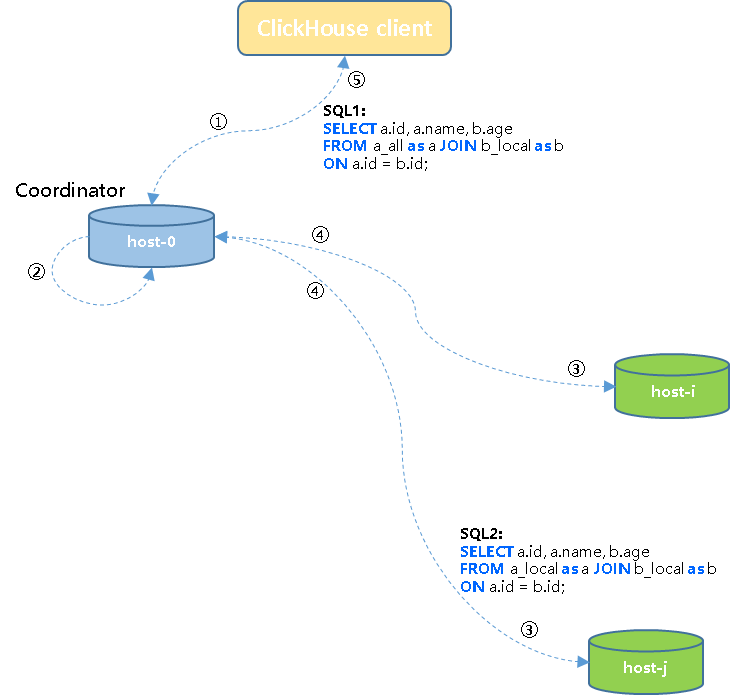
① 客户端将SQL1发送给集群中一个节点host-0(initiator/coordinator);
② host-0节点将任务改写为SQL2子查询任务;
③ Coordinator节点将SQL2子查询任务下发到集群各个节点执行;
④ 各子节点任务执行完成之后将结果发回到协调节点;
⑤ 协调节点将上一步接收到的结果汇总为结果集返回给客户端。
3)总结:
- 由于数据已经进行了预分区/分布,相同的JOIN KEY对应的数据一定存储在同一个计算节点,join计算过程中不会进行跨节点的数据交换工作,所以无需对右表做分布式查询,也能获得正确结果,并且性能较优。
2. ClickHouse Colocate join
2.1 Colocate JOIN原理:
- 根据“相同JOIN KEY必定相同分片”原理,我们将涉及JOIN计算的表,按JOIN KEY在集群维度作分片。将分布式JOIN转为节点的本地JOIN,极大减少了查询放大问题。按如下操作:
1)将涉及JOIN的表字段按JOIN KEY用同样分片算法进行分片;
2)将JOIN SQL中右表换成相应的本地表名称进行join。
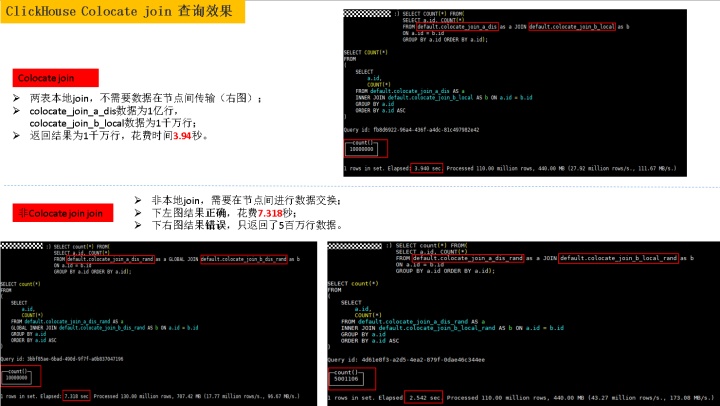
2.2 Colocate JOIN性能:
- 数据和用例准备
1)环境:准备2 shard,2副本共4个节点的ClickHouse计算节点集群;
2)用例:分别创建join字段按id % 2(2为shard个数,可根据实际集群环境进行调整)取余数据分布方式(相同id数据分布到同一个节点),以及RandRowbin (数据随机rand分布)数据分布方式分布式表和本地表,分布式表指定分布方式,本地表为Replicated表,具体用例如下:
- colocate_join_a_local数据按照2分片(id % 2或哈希取模)进行数据分布;
- 相同分布列的字段key的数据会分布到同一个节点;
- 数据通过分布式表colocate_join_a_dis把数据写入分布到各数据节点。

- colocate_join_a_local_rand数据(rand())随机分布;
- 相同分布列的字段key数据会随机分布到各节点;
- 数据通过分布式表colocate_join_a_dis_rand写入进行分布。

- 结果对比
2.3 Colocate Join场景约束
1)数据写入
Colocate join场景需要用户在系统建设前提前进行数据规划,数据写入时join的左右表join条件字段需要使用相同哈希算法入库分布,保证join key相同数据写入到同一个计算节点上。
- 如果对数据写入时效性要求不太高的场景,可通过分布式表进行生成数据,生成数据简单快捷,性能较慢;
- 如果对数据写入时效性要求较高的场景,可通过应用/中间件写入数据到local表,中间件需要实现入库数据分布算法,入库性能较好。
2)扩缩容
- 扩缩容完成后,需要将全部数据重写/重分布一遍,缺点:耗时长,占用存储可能暂时会翻倍,一种节省空间的方式是:逐个表进行重分布,每个表数据重分布完成后可删除重分布前的数据,避免占用过多存储。将来的改进/增强:重分布过程中支持可写在线,重分布尽量少或不影响写入查询的在线操作,减少重分布过程中对客户业务的影响。
3. 总结
业界所宣称的ClickHouse只能做大宽表查询,而通过以上分析,事实上在特定场景下ClickHouse也可以进行高效的join(Broadcast join和Colocate join)查询,如果将表结构设计及数据分布的足够好,查询性能也并不会太差:Broadcast join对于大小表关联,需要将小表数据放在右边;Colocate join需要将join key字段使用相同的分布算法,将分布键相同数据分布在同一个计算节点。对于ClickHouse而言,当前优化器能力较弱,如join场景reorder以及统计信息缺失,基于成本代价估算CBO的优化能力较弱,用户SQL所写即所得,可能会要求人人都是DBA,人人都要对ClickHouse或数据库有深入的理解及经验才能设计出较优的数据库结构以及写出较高性能的SQL语句。对于ClickHouse手动挡数据库,将来我们也会在统计信息、CBO优化器、分布式join模型框架、大大表等多表关联查询以及复杂查询上进行优化增强,以降低用户使用门槛,提升用户使用体验。
