Apache Hive 2.1已于几个月前发布,它引入了内存计算,这使得Hive计算性能得到极大提升,这将会影响SQL On Hadoop目前的竞争局面。据测试,其性能提高约26倍。
Apache Hive 2.1新引入了6大性能,包括:
(1)LLAP。Apache Hive 2.0引入了LLAP(Live Long And Process),而2.1则对其进行了极大的优化,相比于Apache Hive 1,其性能提升约25倍;
(2)更鲁邦的SQL ACID支持;
(3)2X ETL性能提升。引入更智能的CBO(Cost Based Optimizer),更快的类型转换以及动态分区优化;
(4)支持存储过程。加大简化了从EDW迁移到Hive的流程。这是通过开源项目HPL/SQL(Apache开源协议,http://www.hplsql.org/)实现的,HPL/SQL的目的是为Apache Hive,SparkSQL, Impala 以及其他SQL-on-Hadoop 实现, 任何 NoSQL和 RDBMS增加存储过程的实现;
(5)对文本格式数据增加向量化计算的支持;
(6)引入新的诊断和监控工具,包括新的HiveServer2 UI,LLAPUI和改进的Tez UI。
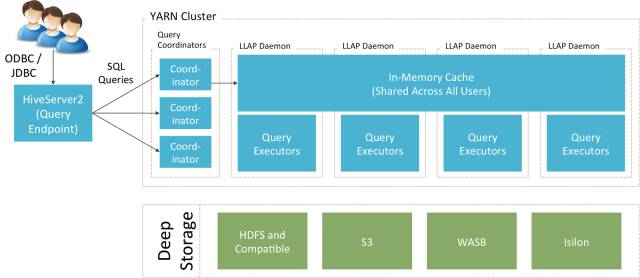
接下来详细介绍对Apache Hive 2.1性能提升至关重要的优化:LLAP。LLAP是“Live Long and Process”的简写,它引入了分布式持久化查询服务,并结合经优化的数据缓存机制,可快速启动查询计算作业并避免无需的磁盘IO操作。简而言之,LLAP是下一代分布式计算架构,它能够智能地将数据缓存到多台机器内存中,并允许所有客户端共享这些缓存的数据,同时保留了弹性伸缩能力。
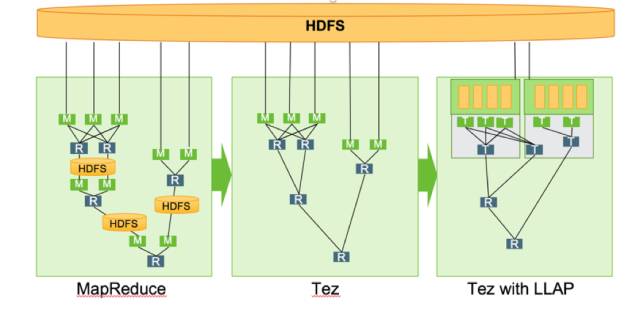
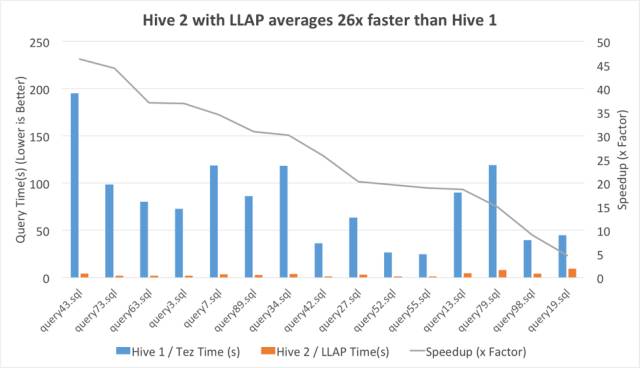
相比于Hive 1 + Tez,Hive2+ Tez+LLAP性能提升约26倍,测试结果如下图所示(测试结果是通过https://github.com/hortonworks/hive-testbench得到的):
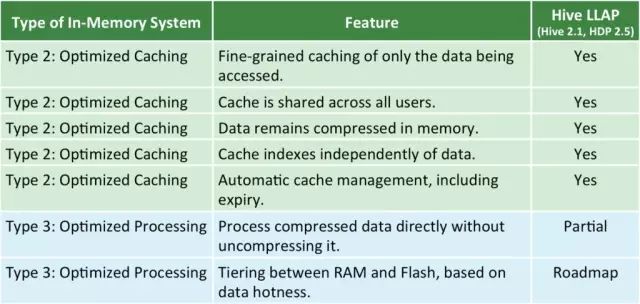
Hive2 LLAP的引入,标志着Apache Hive进入内存计算时代。总结起来,内存计算类型可分为以下三类:
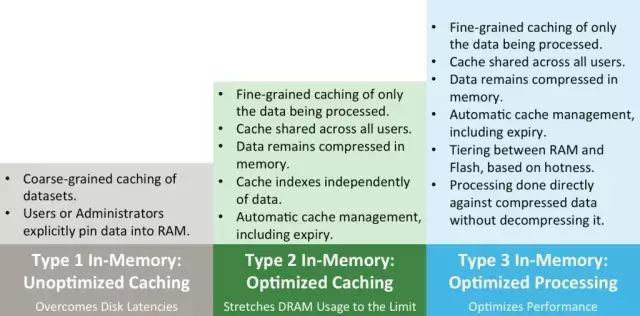
其中,Type1已被Apache hadoop生态系统证明其性能不会太高,因而Hive直接进入Type2,目前对Type2中所有特性均支持地很好,包括分布式内存管理和优化,内存数据共享等。此外,Apache Hive正进一步优化性能,包括支持新型存储介质Flash,扩展LLAP能力,使其可以直接处理压缩数据而无需事先解压。
原文链接:https://mp.weixin.qq.com/s/TZx15oP9AJ_YB-aqoPMImw
