近几年机器学习非常火,几乎每一个项目组都在思考自己手头的项目能不能用机器学习的方法进行优化。对于前端同学来说,有一个主要的难点在于前端技术栈和机器学习所需要的基础技能有很大的gap,市面上的机器学习的基础教程,对读者的数学基础要求偏高,有些基本的原理或者世界观,被当做自然而然的事情忽略,会导致理解上的困难。本文试着填补一下从高中数学到通常的机器学习入门之间的空白。
概率论回忆
随机事件:在随机试验中,可能出现也可能不出现,而在大量重复试验中具有某种规律性的事件叫做随机事件(简称事件)
样本空间:随机事件所有结果的总和
随机变量:随机事件的结果对应的数字,随机变量本质上来讲,是样本空间的子集到实数空间的一个映射。
举例来说,连续扔两次硬币,H记为正面向上,T表示背面向上,那么样本空间就可以记为

,我们定义一个随机变量X,叫做抛硬币结果中出现正面的个数,于是有下表:

假设每个实验结果出现的概率都是四分之一,那么就可以计算出来随机变量的概率

真实世界举例
mnist
然而真实世界里面的问题,不能做这种每次实验结果概率都相等的假设。即使做了这种假设,实验结果的集合Ω可能非常庞大,不可能像上面的例子那样列举出来,也无法计算。
假设我们现在有一个手写数字识别的任务(mnist)。

每个图片都是28*28=784个像素的一张图片,每个像素的取值范围是0-255,所以一共有

个不同的样本,暴力的方法来看,生成全部这些样本,做一个字典,做好每一个样本对应的数字,这个问题也就解决了。
然而上述解法只是理论上的,

这个量级的数据的存储、检索、标记,都是一个不可能完成的任务。幸运的是,这也并不是必须的。事实上,假如每一个像素都是随机的,那么我们大概率得到的图像是这样的:

在这个巨大的样本空间中,只有很小的部分是数字。我们定义一个随机变量X,那么P(X=0)=?理论上来讲,需要统计一下,看起来被认为是0的图片有多少个,然后除以

。然而这个数字是没办法获取的。那么问题来了,随机生成一个这样的样本,它是数字的概率是多少?是0的概率呢?给定一个这样的图片,怎么判断它是不是数字呢?更进一步,是不是0?
我们可能想写一些描述性的代码,比如有一个环形的白色像素,中间是黑色,这样的图片是0.然而编程实现起来,难度很大。环形怎么定义?缺了一个像素不连通了,还是不是0?0和非0差的那1个像素,到底从哪里界限?0的右边往下延长就是9,那么多出来几个像素的时候,是0和9的分界线呢?
事实上,这就是大部分现实情况下的概率问题,我们面对的是一个巨大的样本空间,并且没办法通过简单的文字描述或者计算公式,来计算每一个随机变量的概率密度。想象一下你现在要教一个不识字的盲人认字,你想告诉他什么是0,什么是1,你打算怎么教他呢?只能用我上面说的描述性的办法,学习效果怎么样呢?
我们小学的时候学数字,也从来没有这么教过,也没有给过你一个的数学描述(其实粗略的语言描述也没有),说什么样的写法是0,什么样的写法是1。而是老师写了几个例子,然后告诉你,这样子的就是0,那个样子的是1。然后你自己在家练习,自己写一遍,然后你就记住了。在这里,我们本质上是对数字0的样本整体进行了采样,然后用采样后的样本,来表示数字0的图像的概率分布。
这种把样本看成某种未知的概率分布的采样的思想,对理解机器学习任务有这很大的帮助。比方说人脸检测,随机给一张图片,它是人脸的概率是多少?有多少图片会是一张人脸?文字描述是更加困难的,数学公式表达是不可能的,只能给出一批采样,然后告诉你,类似这样的,都是人脸。这叫做样本表示的概率密度。

这些内容,其实高中也有涉及,统计抽样,给一批正态分布的样本,计算它的均值方差,然后估计这个正态分布的参数。然而高中你很难理解为什么要这么做以及这么做有什么意义。有了这样的例子,你会知道大多数概率密度,都是没法像正态分布二项分布之类的,用带参数的数学公式表达的。只能做采样,用样本来表示这个概率分布。
回到我们数字识别的正题,一个可能的想法是这样的,假如要识别的不是数字,而是下面这样的图片就好了:

我们可以很简单的写下判断语句:中间二分之一是白色,等于0,否则不是。甚至还能算出来的概率,当然这个就稍微超出了高中数学概率的范畴。
上面描述的,比方说,有一圈的白色像素,中间黑色,或者上下是黑色,中间是白色,就是机器学习里面的特征。有的特征描述起来比较费力,甚至没法用程序语言描述;有些特征却只需要一行代码就能描述。后面的部分,就是通常的机器学习里面的基础部分了,做一个非线性映射,把难以描述的样本特征映射到一个可以简单到画条线就能分开,比方说下面这个经典的网络:

所谓的深度学习,其实就是把以前依赖手工观察得到的特征转换的部分,放到了模型当中,前面的部分,都是描述这个样本的特征的。接下来的部分,就是通常的机器学习基础教程里面的“术”的部分了,比方说什么CNN、池化、激活函数之类的,大家可以自行学习。
统计语言模型
大刘有过一个科幻小说,叫做《诗云》,说在一个科技超级发达地方,有一个外星人,喜欢上了李白的诗,于是造了一个庞大的数据库,存储了方块字的所有可能的组合,把文科生的艺术创作变成了技术男的大数据检索。这事理论上的确有可能,而且按照这个思路来看,什么塞尚梵高贝多芬巴扎特的艺术作品,我们都可以用类似的技术去实现一个画云,乐云什么的。
当然以我们地球人现在的科技,还做不到上述方案,我们只能采用和上述的手写数字类似的思路,用采样后的概率问题去解决。在自然语言的例子里面,一个问题是这样的,一个十个字组成的序列,它是一个人类能够理解的句子的概率有多大?
统计的方法来看,也不难,假设是中文,有3000个词,于是总量就是

种可能,在这里面有多少是句子呢?答案是没法统计。至于用规则去描述什么是句子,曾经人类花费了大量的时间精力去试图用规则的方式定义句子,换句话说,就是用主谓宾定状补之类的试图解构自然语言。
在语言学家和计算机专家的努力下,后得到了数千条规则,整个系统无比复杂,但效果一直不理想,直到基于统计的语言模型的出现。
在统计语言模型的视角里面,不再费心去研究句子的描述,而是拿到一批句子的样本(这个比较好获得,找找人类写出来的文章就行),然后用这批样本去描述人类自然语言的概率分布,而不是曾经尝试的用规则去描述,从此揭开了自然语言理解新的篇章。
假定S表示某个有意义的句子,由一连串特定顺序排列的词

组成,这里n是句子的长度。现在,我们想知道S在文本中出现的可能性,即S的概率P(S),则
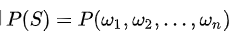
利用条件概率的公式:

这样这个概率就是可统计的了,然而实际统计起来仍然有困难,于是做了一个假设:每一个词只和它前面的N个词有关,这就是N-gram模型,假设N=2,于是,新的公式是这样的:

这样,给一个文本,简单统计一下,就可以得到上述概率。这个输出,就是这个样本的统计特征,接着就可以对这个特征做一些非线性的映射,再接入不同的自然语言任务,和上面mnist类似,不再细讲。
当然,新的语言模型要比这个复杂得多,N-gram的假设也有问题,词可能和它的很远的另一个词有相关性,具体解决起来要用更复杂的模型,但是思路是一致的,都是用句子样本来表示概率分布,然后对样本特征进行各种转换,后接入不同的自然语言理解任务。
总结
这种视角还有很多不同的应用,比方说上面说的莫扎特的作品,我们也可以用类似的思路:收集莫扎特的所有作品,做特征变换,然后做一些很有趣的事情,比方说分类任务——判断一首曲子是不是莫扎特的。也可以用生成模型,比如GAN,实质上做的是一个概率分布转换的事情,就是把一个随机的均匀分布或者正态分布的样本,转换成莫扎特的曲子的所在的概率空间的分布,于是输入随机噪声,生成了莫扎特的曲子。
类似的思路,也可以拿来写诗,写对联,画画,等等。只要理解了样本空间表示的概率密度这件事情,这些都是类似的。这可以理解成机器学习的“道”,至于具体怎么做,怎么样设计模型,里面哪些参数需要调节,都是只是技术问题而已。
