全并行的分布式查询处理是GaussDB 100中核心的技术,它可以大限度的降低查询时节点之间的数据流动,以提升查询效率。
GaussDB 100为达成高性能数据分析目标,实现了一套高性能的分布式执行引擎,执行引擎以SQL引擎生成的执行计划为输入,将元组按执行计划的要求进行加工并将结果返回给客户端。
图1 分布式查询示意图
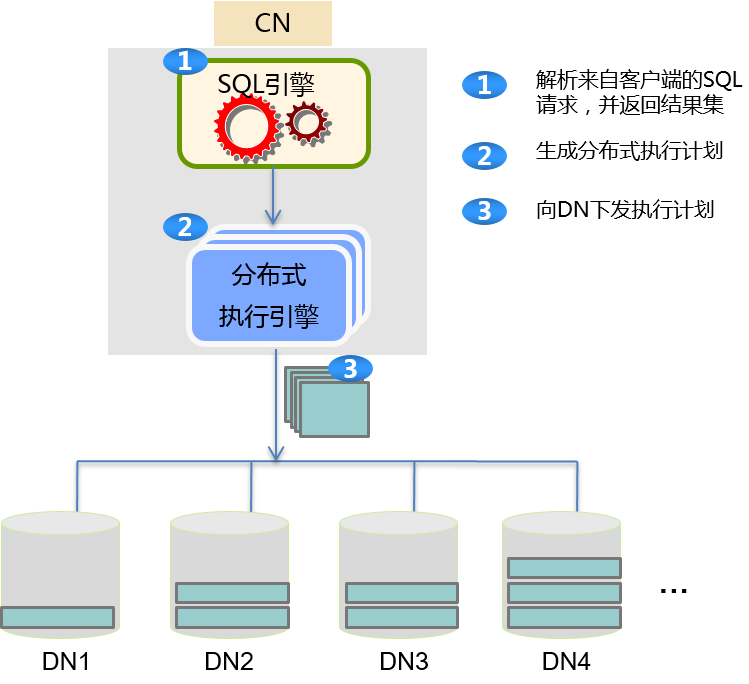
一个涉及多个执行算子的复杂查询的大概执行过程如下:
- CN接收到查询任务(通常是SQL语句描述)后,对SQL语句进行语法解析并分解出基础的查询和数据处理执行算子,比如DataScan、Sort、Aggregation以及Join。
- 随后CN会生成优的基础任务执行序列,并将这些基础任务部署到各个节点上去执行。
- 各个DN完成数据处理后,会将结果汇总到CN上并输出到客户端。
