行存储通常用于高并发在线事务处理和事务分析混合场景。需求明确的是,RapidsDB的行存储都是存储在物理内存里,所有行存储表的总组合大小受集群中叶节点上可用物理内存总量的限制。为此,查询执行保留合理数量的物理内存(例如 20%)非常重要。行存储表的有效总容量会降低可用内存容量。
对于执行频繁的单行查找和少量插入、更新和删除的应用程序,行存储的性能比列存储高效得多。一般来说,由于行存储支持更多种类的工作负载,此时它是一个很好的使用选择。
RapidsDB的行存(内存)表可以指定一个分布键和一个或多个索引,这些分布键和索引是可选的,同时支持用户强制的主键。我们可以做个使用小测试,先建一张行存表:
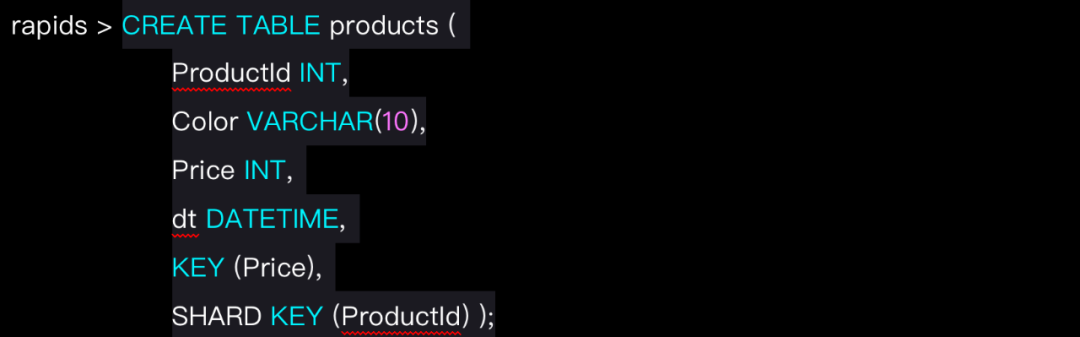
这里定义了一个分布键来控制数据分布,并通过字段ProductId来定义它。因为在一个或多个高基数列(极少发生重复数据)上,数据通常分布更均匀,还可以规避数据偏斜。
如果没有定义主键,则通过缺少的分布键或者定义空的分布键 SHARD KEY() 来随机分布数据。
行存表索引
具有多个索引的行存储通过多个不同的键或“访问路径”快速检索到一行或几行数据。RapidsDB行存储能够沿多个不同的访问路径提供极快的查找,并且查询之间的响应时间差异极小。
以下语句创建了一个products表,其中包含索引Price和Color,以及上的(主)键ProductId:
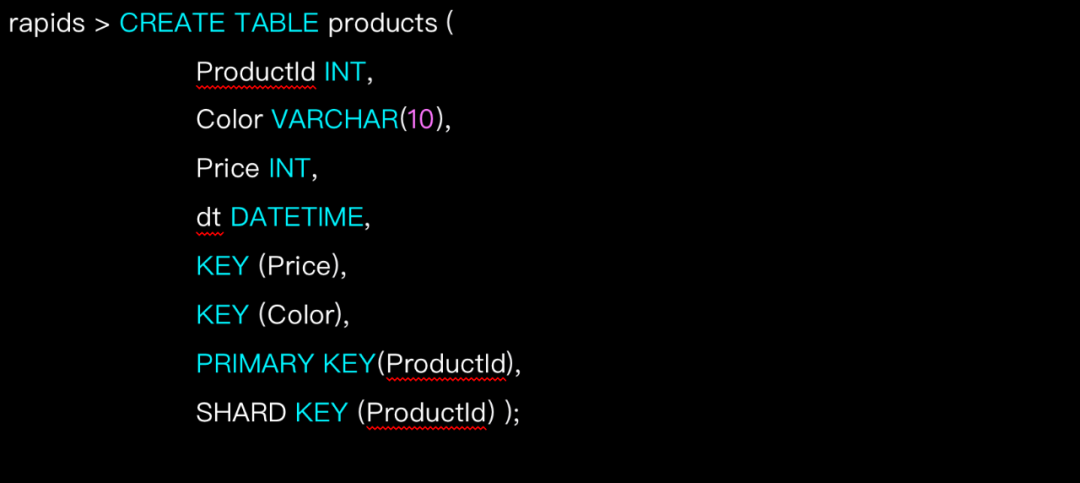
注意:主键必须包含分布键中的所有列,这样就可以通过只查看单个分布区域中的数据来有效的检索它们。只创建主键而不指定分布键的话,系统会自动将通过主键进行分布。
平时可以单独通过语句CREATE INDEX在行式表中创建索引。
行式表持久性
需要声明的是,行存储的数据是完全持久的!!!
行式表的更新是在事务中完成的。持久性则是使用内存中数据的定期快照和预写日志来为行存储实现的。这两者都存储在文件系统中,以使它们存在。如果RapidsDB节点重新启动,它的所有行存储数据将从快照和日志中恢复,并且行存储的内存状态将被重建。
大型数据集上的OLTP操作
对于大型表上的OLTP操作,在使用行存储时,配置足够的内存以及足够的服务器的总成本可能会成为一些用户非常关心的问题。如果是这种情况,并且应用程序不需要快的行查找时间,可以考虑使用列式表,在常用的查找键列上使用散列索引。或者,对于具有许多空值的宽表,可以通过使用具有稀疏数据压缩的行式表来降低总拥有成本。
上段已经提到了列存表,现在马上给大家介绍列存储的优化加速原理:
聚集列存储索引:RapidsDB会定义一个聚集列存储索引,它代表完整的表结构并且是其主存储。
列存储键列:这是创建列存储索引时,会将一列或多列定义为列存储索引的键列。列存储中的数据按键列顺序存储。因此,选择一个好的列存储键可以显著提高性能。
行段:行段表示列存储索引中的一组逻辑行,它有利于用户日常的增删改等数据操作。RapidsDB将每个行段的元数据存储在内存中,其中包括该段的总行数和跟踪哪些行已被删除的位掩码。
列段:每个行段包含表中每一列的列段。列段是列存储表的存储单元,包含行段中特定列的所有值。列段中的值始终以相同的逻辑顺序存储在同一行段内的列段之间。RapidsDB将每个列段的元数据存储在内存中,其中包括段中包含的小值和大值。此元数据在查询执行时用于确定段是否可能匹配过滤器,该过程称为段消除。
已排序的行段组:已排序的行段组表示在列存储键列上一起排序的一组行段。这意味着,在已排序的行段组中,不会有行段与构成列存储索引键的列的值范围重叠。在对表运行INSERT、LOAD或UPDATE查询后创建更多段时,会形成新的段组。
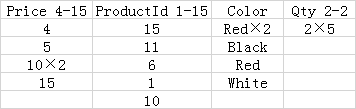
用个例子来说明在日常查询中,RapidsDB的列存表是怎么样实现高性能的,下面是在Products表中使用Price列作为关键字的RapidsDB列式表索引的示例:
注:列段通常包含几十万行,在本例中,为了可读性,段的大小为5行。

已排序的行段组1组:
行段组2组:
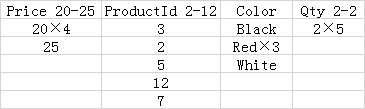
行段组3组:
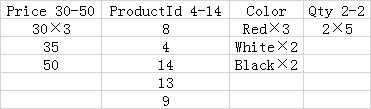
注:×N表示该值被重复N次
对具有列式表索引的表查询可以利用列式表索引的五个特征:
所有查询都能够利用以下情形:只需要扫描包含查询中引用的列的列段,以及列存储的压缩导致需要被扫描的数据较少。以上表为例,查询SELECT SUM(Qty) FROM Products;,将只需要扫描三个Qty列段,并且由于压缩,每个列段只包含了一个值。
一些查询可以简单地通过读取查询中引用的列段的内存元数据来执行。例如,查询SELECT COUNT(*) FROM Products; 将只需要读取行计数并删除所有行段的位掩码来产生结果,完全消除了从磁盘读取列段的需要。如果没有对列段执行删除操作,使用MIN或MAX聚合的查询可以消除从磁盘读取列段的需要。
一些查询可以通过基于段元数据(段的大值或小值)消除这些段来减少需要从磁盘读取的段的数量。这种方法的效率取决于实际可以消除的片段的百分比。
对于筛选列存储索引的键列查询,段删除通常非常有效,因为每行段内的段都不会覆盖重叠的值范围。例如,在上表中,查询SELECT AVG(Price), AVG(Qty) FROM Products WHERE Price BETWEEN 1 AND 10; 将消除除了要被扫描的行段1组,列段Price 4-15和行段1组,列段Qty 2-2以外的所有段。
对于筛选与键列不相关的非键列的查询,段删除的价值可能要低得多,因为每行段内的的段可以覆盖重叠的范围。例如,在上表中,查询SELECT AVG(Price) FROM Products WHERE Color = 'Red';将被强制扫描Price和Color列的所有段,因为Red值被包含在Color这一列的所有段中时,没有段可以被删除。
通过使用合并连接算法,可以非常高效地对列存储索引的索引列表上的表进行连接查询,该算法允许通过简单地扫描需要在锁步中连接的两个段来执行连接。
某些类型的数据允许在不将数据从其序列化为磁盘格式解压缩的情况下执行。筛选和分组操作。这通过减少需要处理的数据量极大地提高了性能,尤其是当涉及的列基数较低时。这种优化只在执行运行时间得到改善的情况下执行。
带有选择性过滤器的查询使用子段访问,这些查询寻找列段来读取所需的值,而不是扫描整个段。对于列式表MyTable,查询SELECT Field1, Field2 FROM MyTable WHERE Field1 > 50使用子段访问。具有多种条件的选择性筛选器,例如SELECT Field1, Field2 FROM MyTable WHERE Field1 > 50 AND Field2 > 100也同样使用子段访问。
使用相等过滤器的查询可以利用散列索引,因为等式过滤器通常是选择性过滤器。
柏睿数据RapidsDB在某国有大行普惠金融项目应用中,就是使用了列存储的方式处理行内业务,出色地支撑行方50000多个客户经理在日常业务中的大量灵活组合查询需求。
✦
