《深入浅出话DB》之高性能篇 目录
第二回:行列混存,Here we go!
RapidsDB具有出色的面向海量数据的数据存储及处理分析能力,提供行列混合存储技术,支持在同一个SQL查询中对行存储表和列存储表同时进行访问。在用户数据无法在预算内满足全内存加载存储时,列存储提供了一个很好的混合存储手段,在提升查询性能,实现单节点优化的同时,解决了内存存储空间压力过大的问题。
面向行的存储或“行存储”是关系型数据库使用的常见的数据库存储类型。顾名思义,行存储将每一行视为一个单元,并将给定行的所有字段一起存储在同一物理位置中。这使得行存储非常适合事务型工作负载,在这种情况下,数据库的选择、插入、更新和删除单个行的操作,通常会引用大多数或所有的列。
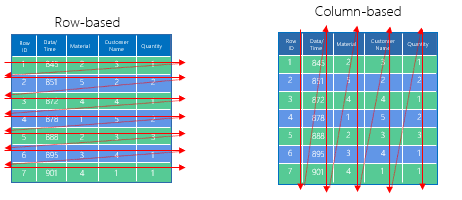
面向列的存储或“列存储”将每一列视为一个单元,并将每列的数据段一起存储在同一物理位置中,这个手段实现了两个重要的功能:
一个功能是可以单独扫描每一列。本质上,能够只扫描查询所需的列,在扫描期间具有良好的缓存局部性。
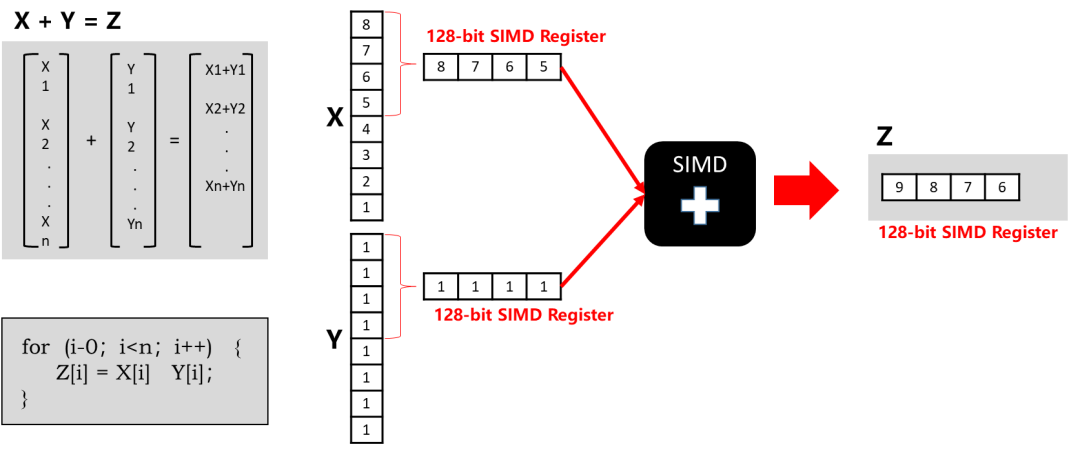
另一个功能是列存储非常适合进行压缩。例如,复和相似的值可以很容易地压缩在一起。同时,基于列式存储格式,可以使用基于硬件SIMD指令集的向量化执行模式(Vector-at-a-time)提高数据访问的效率。
RapidsDB支持使用全内存的行式存储和基于内存的列式存储来存储和处理数据。基于全内存的行式存储为事务型工作负载提供了佳的实时性能。基于内存的列式存储适合跨大型历史数据集的分析工作负载。列式表的数据写入过程首先要在内存通过列存储索引对数据进行计算,将各数据块的元数据保存于内存中,同时将压缩备份的数据存放于磁盘中。此外,事务、缓存、执行计划等均在内存中计算、存储。磁盘中大部分操作均为写入操作,读取操作大部分在内存中完成,更加保障了查询效率的提升。
海量数据处理以OLAP分析型场景居多,这些场景的特点之一便是批量查询场景较多,这个时候我们的列存储提供的特有建立索引及数据分区和数据压缩特点,可以一定程度的提升查询效率。当列存储表面对特定的查询只需要对极少数的字段进行操作,而不用关心其他字段,这将大大减少了读取数据的量。此外,在面对海量数据时,基于很多用户的预算问题,无法支持将所有数据都存于内存当中。列存储提供了将小表基于全内存,大表基于磁盘的混合存储模式,可以极大限度提升面对海量数据的处理分析能力。
传统业务数据处理分为联机事务处理(OLTP)与联机分析处理(OLAP)两类,通过统一架构同时支持OLTP和OLAP混合负载成为数据库发展的新需求。
目前支持混合负载技术架构大致有以下几种:
种是行存为主,内存列存为辅。针对有需要的表会同时存在一份行存储和列存储,在列存储上做分析操作,在行存储上进行更新,定期同步到列存储里,可以灵活指定需要采用行存与列存的表。技术难点在于哪些数据转为列存、如何用行存和列存回答查询。
第二种是列存为主,行存为辅。增量数据通过delta表定期转为列存,主列存主要处理OLAP类分析查询,增量行存负责OLTP类事务操作,并直接将更新数据定期合并到主列存中。缺点是OLTP处理性能中等,扩展性也不高,负载隔离性很低。
第三种是主机行存、备机内存列存。备机通过日志复制转为内存的列存提供分析能力,查询基于代价估计后决定是否下推到内存列引擎中执行,常被访问的热数据将会留在内存中,冷数据将会被压缩后持久化到外存中。
第四种是多副本行列共存。通过多副本进行存储,主采用行存,副本采用列存,通过异步复制Raft log的方式将更新从行存节点同步到列存节点,具有较高负载隔离性和扩展性,数据分析新鲜度偏低。
RapidsDB通过统一的行列混存架构同时支持OLAP、OLTP实时分析处理。用户可以通过标准的SQL DDL语法创建列式表或者行式表,并可以通过使用行式存储表和列式存储表的组合来达到在一个查询任务中合并实时数据和历史数据的目的,从而简化技术堆栈。
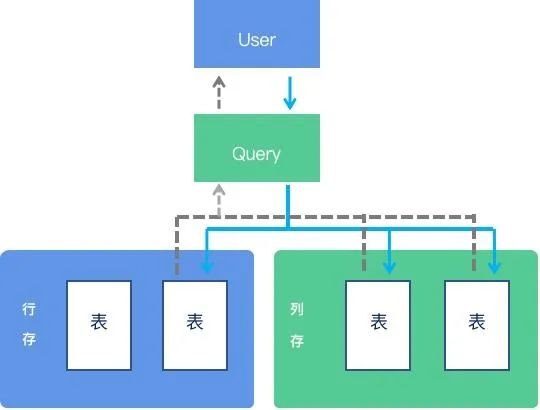
RapidsDB可提供行式存储、列式存储以及行列混合存储作为建表结构,以对应不同的业务场景。
实践应用
在某国有大行普惠金融项目应用中,因为列存储具有可负载大量分析工作、快速聚合和表扫描、可跨大型历史数据集等技术特性,很好的支持了该行在大数据量(1100亿行数据、40TB数据量)、大并发(典型几百并发、极端4000+ 数据库并发)、多表复杂查询(查询SQL由前端应用系统灵活组合而成,多15个表Join操作)的复杂应用场景,为全行5万个客户经理提供日常业务查询,支撑精准营销及信贷风控的业务需要。
✦
