
今天是Numpy专题第6篇文章,我们一起来看看Numpy库当中剩余的部分。
数组的持久化
在我们做机器学习模型的研究或者是学习的时候,在完成了训练之后,有时候会希望能够将相应的参数保存下来。否则的话,如果是在Notebook当中,当Notebook关闭的时候,这些值就丢失了。一般的解决方案是将我们需要的值或者是数组“持久化”,通常的做法是存储在磁盘上。
Python当中读写文件稍稍有些麻烦,我们还需要创建文件句柄,然后一行行写入,写入完成之后需要关闭句柄。即使是用with语句,也依然不够简便。针对这个问题,numpy当中自带了写入文件的api,我们直接调用即可。
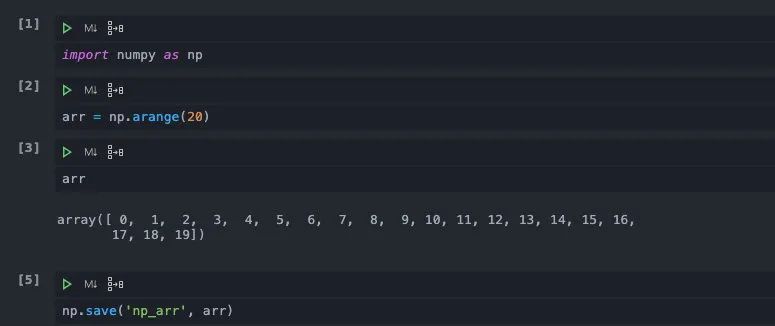
通过numpy当中save的文件是二进制格式的,所以我们是无法读取其中内容的,即使强行打开也会是乱码。

以二进制的形式存储数据避免了数据类型转化的过程,尤其是numpy底层的数据是以C++实现的,如果使用Python的文件接口的话,势必要先转化成Python的格式,这会带来大量开销。既然可以存储,自然也可以读取,我们可以调用numpy的load函数将numpy文件读取进来。

要注意我们保存的时候没有添加文件后缀,numpy会自动为我们添加后缀,但是读取的时候必须要指定文件的全名,否则会numpy无法找到,会引发报错。
不仅如此,numpy还支持我们同时保存多个数组进入一个文件当中。

我们使用savez来完成,在这个api当中我们传入了a=arr,b=arr,其实是以类似字典的形式传入的。在文件当中,numpy会将变量名和数组的值映射起来。这样我们在读入的时候,就可以通过变量名访问到对应的值了。

如果要存储的数据非常大的话,我们还可以对数据进行压缩,我们只需要更换savez成savez_compressed即可。

线性代数
Numpy除了科学计算之外,另外一大强大的功能就是支持矩阵运算,这也是它广为流行并且在机器学习当中大受欢迎的原因之一。我们在之前的线性代数的文章当中曾经提到过Numpy这方面的一些应用,我们今天再在这篇文章当中汇总一些常用的线性代数的接口。
点乘
说起来矩阵点乘应该是常用的线代api了,比如在神经网络当中,如果抛开激活函数的话,一层神经元对于当前数据的影响,其实等价于特征矩阵点乘了一个系数矩阵。再比如在逻辑回归当中,我们计算样本的加权和的时候,也是通过矩阵点乘来实现的。
在Andrew的深度学习课上,他曾经做过这样的实现,对于两个巨大的矩阵进行矩阵相乘的运算。一次是通过Python的循环来实现,一次是通过Numpy的dot函数实现,两者的时间开销相差了足足上百倍。这当中的效率差距和Python语言的特性以及并发能力有关,所以在机器学习领域当中,我们总是将样本向量化或者矩阵化,通过点乘来计算加权求和,或者是系数相乘。
在Numpy当中我们采用dot函数来计算两个矩阵的点积,既可以写成a.dot(b),也可以写成np.dot(a, b)。一般来说我更加喜欢前者,因为写起来更加方便清晰。如果你喜欢后者也问题不大,这个只是个人喜好。
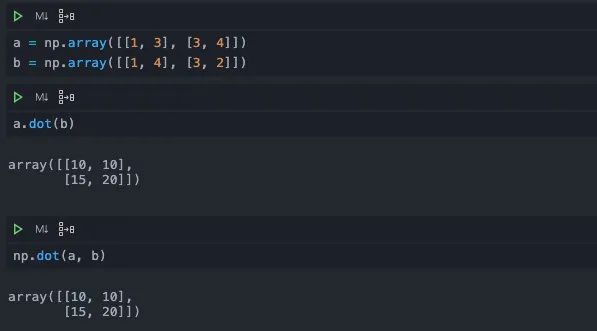
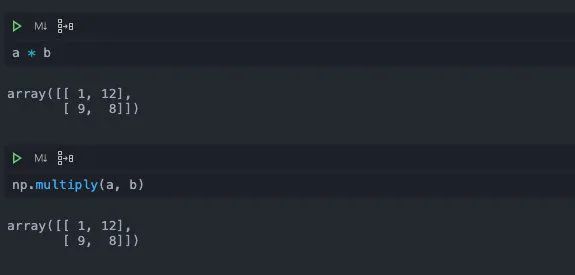
注意不要写成*,这个符号代表两个矩阵元素两两相乘,而不是进行点积运算。它等价于np当中的multiply函数。
转置与逆矩阵
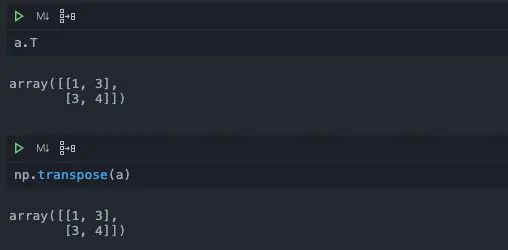
转置我们曾经在之前的文章当中提到过,可以通过.T或者是np.transpose来完成。
Numpy中还提供了求解逆矩阵的操作,这个函数在numpy的linalg路径下,这个路径下实现了许多常用的线性代数函数。根据线性代数当中的知识,只有满秩的方阵才有逆矩阵。我们可以通过numpy.linalg.det先来计算行列式来判断,否则如果直接调用的话,对于没有逆矩阵的矩阵会报错。

在这个例子当中,由于矩阵b的行列式为0,说明它并不是满秩的,所以我们求它的逆矩阵会报错。
除了这些函数之外,linalg当中还封装了其他一些常用的函数。比如进行qr分解的qr函数,进行奇异值分解的svd函数,求解线性方程组的solve函数等。相比之下,这些函数的使用频率相对不高,所以就不展开一一介绍了,我们可以用到的时候再去详细研究。
随机
Numpy当中另外一个常用的领域就是随机数,我们经常使用Numpy来生成各种各样的随机数。这一块在Numpy当中其实也有很多的api以及很复杂的用法,同样,我们不过多深入,挑其中比较重要也是经常使用的和大家分享一下。
随机数的所有函数都在numpy.random这个路径下,我们为了简化,就不写完整的路径了,大家记住就好。
randn

要注意的是,我们传入的shape不是一个元组,而是每一维的大小,这一点和其他地方的用法不太一样,需要注意一下。除了正态分布的randn之外,还有均匀分布的uniform和Gamma分布的gamma,卡方分布的chisquare。
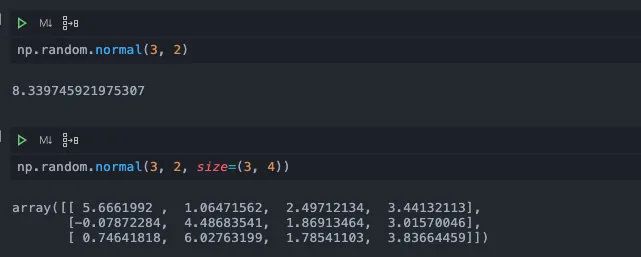
normal
normal其实也是生成正态分布的样本值,但不同的是,它支持我们指定样本的均值和标准差。如果我们想要生成多个样本,还可以在size参数当中传入指定的shape。
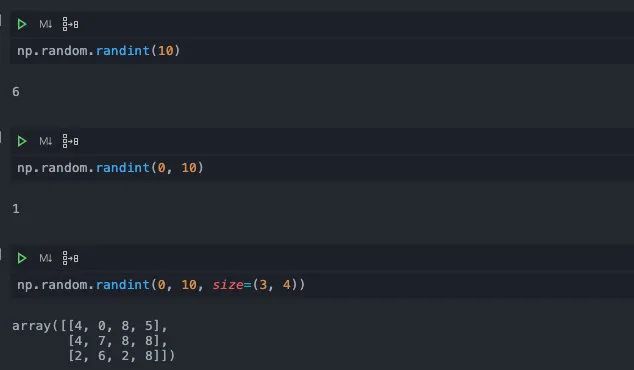
randint
顾名思义,这个函数是用来生成随机整数的。它接受传入随机数的上下界,少也要传入一个上界(默认下界是0)。
如果想要生成多个int,我们可以在size参数传入一个shape,它会返回一个对应大小的数组,这一点和uniform用法一样。
shuffle
shuffle的功能是对一个数组进行乱序,返回乱序之后的结果。一般用在机器学习当中,如果存在样本聚集的情况,我们一般会使用shuffle进行乱序,避免模型受到样本分布的影响。

shuffle是一个inplace的方法,它会在原本值上进行改动,而不会返回一个新值。
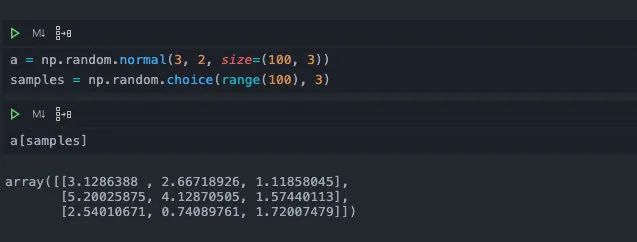
choice
这也是一个非常常用的api,它可以在数据当中抽取指定条数据。
但是它只支持一维的数组,一般用在批量训练的时候,我们通过choice采样出样本的下标,再通过数组索引去找到这些样本的值。比如这样:
总结
今天我们一起研究了Numpy中数据持久化、线性代数、随机数相关api的使用方法,由于篇幅的限制,我们只是选择了其中比较常用,或者是比较重要的用法,还存在一些较为冷门的api和用法,大家感兴趣的可以自行研究一下,一般来说文章当中提到的用法已经足够了。
今天这篇是Numpy专题的后一篇了,如果你坚持看完本专题所有的文章,那么相信你对于Numpy包一定有了一个深入的理解和认识了,给自己鼓鼓掌吧。之后周四会开启Pandas专题,敬请期待哦。
如果喜欢本文,可以的话,请点个关注,给我一点鼓励,也方便获取更多文章。
