#### 一、现状简介
有关MGR的介绍和优势之前已经写过好几篇文章,本文不再展开,大家有兴趣可以查看专栏中的其他MGR文章做进一步了解。在网易内部,MGR已通过RDS金融版服务在云环境提供,在考拉海购上实现规模使用,实例数200+。在物理机环境上,与DDB一起部署的适配方案也已确定,将在云音乐等业务场景上使用。
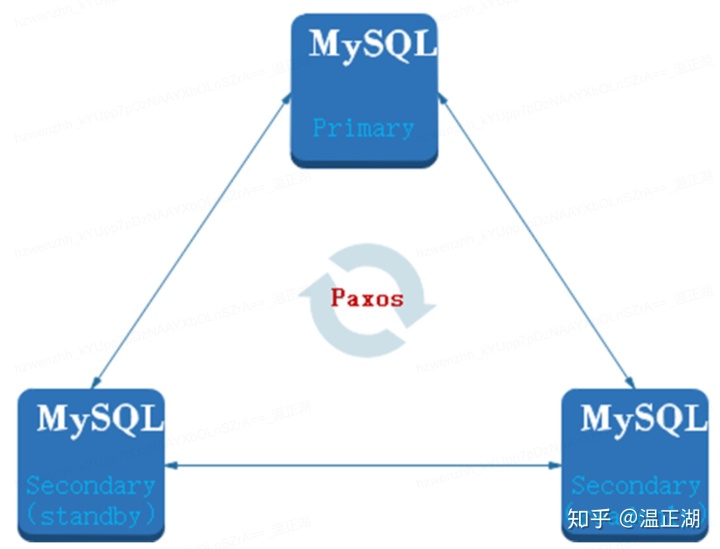
按照目前主流的MGR部署模式,MGR相比传统的MySQL高可用实例会有一半的成本增加:
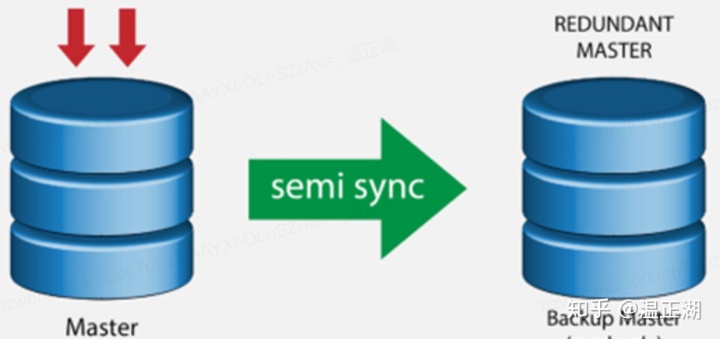
上图所示的传统高可用实例,使用semi-sync复制,1主1备/从(从库和备库表示同样意思),仅需2个节点。
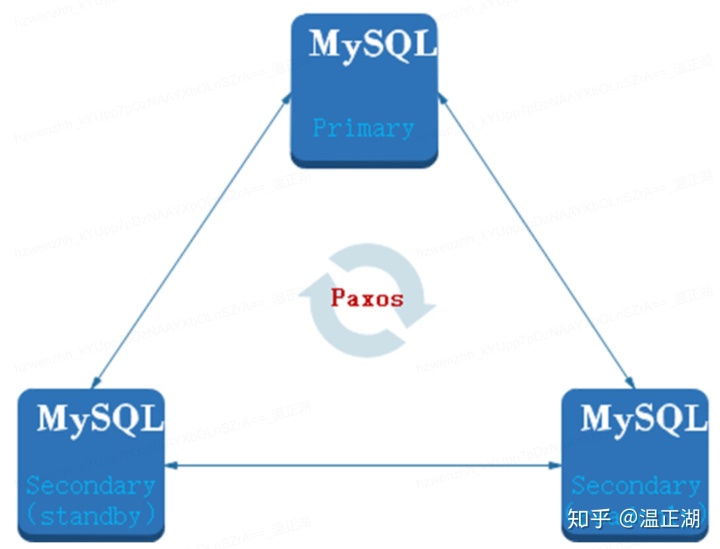
上图是MGR的部署模式,由3个节点组成paxos集群,事务提交时需要至少通过2个节点达成majority后才能成功返回,相比多出1个节点。当然,如果业务还需要进行读写分离,那就会再部署至少1个只读节点,在有只读实例的情况下,MGR可以将3个节点中的一个作为只读节点使用,因此在成本上没有劣势,如下图所示。

但是,并不是所有业务都需要只读节点的。为了能够让MGR在更广泛的场景上使用,部署成本问题必须得到解决。
#### 二、早期优化方案
针对成本问题,其实有很多克服的办法,关键是选择怎么样的方式。在Arbiter方案形成之前,曾希望通过直接减少MGR实例的节点数来解决。
等等,2个节点的MGR?如果挂掉1个节点,仅1个节点存活没法形成majority,MGR实例会不可写啊?
###### 可行否
我本来的看法是:
so what,那又怎样。基于semi-sync的2个节点高可用实例,如果挂掉1个节点(备节点),那么主节点也是会卡主的(意思是写事务commit时无法返回,因为需要等待备/从库回复表示Binlog已经收到的ack信息),所以,其实2节点的MGR实例跟2节点的semi-sync实例出现从库故障时一样,都需要上层的管控服务(可能是RDS管控,也可以是DBA管控系统)介入,或者通过force_member将MGR存活节点重配置成单节点的MGR实例,或者通过切异步将卡住的事务顺利提交。
应该说,2个节点MGR实例跟基于semi-sync的高可用实例在管理方式上是类似的,同时还具备了正常运行时的流控、故障恢复等能力。
###### 不足之处
2节点MGR方案不足之处在于:对使用async复制的业务来说可用性降低了。因为异步复制实例,备节点挂掉不影响主节点的读写事务正常提交,而2节点MGR做不到,肯定会对业务多多少少造成一些影响。
#### 三、Arbiter节点方案来源
成本优化方案,在MGR落地考拉业务时,并没有拿来重点考虑,因为考拉的目标是跨机房高可用,对服务可用性和数据可靠性要求比一般业务高,通过2节点省成本不是高优先级问题,所以只是作为 想法存在,并没有花时间推动实施。
而现在想将MGR在更多的业务上落地,使MGR成为未来MySQL部署一般标准,那么成本问题就变得为突出。另外,经过几个月的思考和沉淀,也对优化方案有了更好的设计。下面简单说下促成Arbiter方案的其他2个有价值的思路来源:
###### 阿里的RDS企业版实例
这是阿里云在2019年下半年刚推出的MySQL高可用方案。其内核应该是阿里集团内部用的X-Cluster,其相比MGR有个显著的优势是支持更多的节点类型,其中之一就是日志(Log)节点角色,按照公开文档描述,X-Cluster的日志节点只保存日志,不存储数据,有投票权没有选举权,引入日志节点的目的是为了降低部署成本。
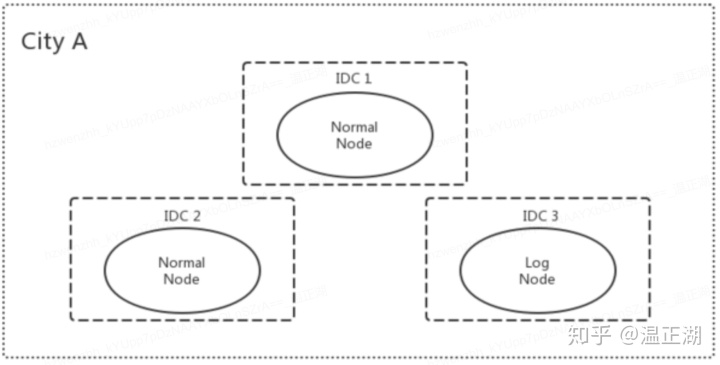
X-Cluster的同城部署三副本能够方便的实现零数据丢失的实例容灾以及机房级容灾。 相比主备方式,额外增加了一个日志节点,换取强一致以及可用性。
之所以要创建不同的类型的副本,还是出于应用需求以及成本控制的考虑。相比传统的两节点主备复制,X-Cluster的常规同城部署方式是三节点。
日志型副本是作为降低部署成本的一种选择。日志型副本只存储日志,不需要存储数据,也不需要回放日志更新数据。因此无论是存储还是CPU的开销,日志型副本相比普通副本都有很大的优势。在实际应用规划中,非常适合来当作容灾型的节点部署。
这似乎跟我们想要的作用挺类似。不一样的是,X-Cluster的日志是异化的Binlog信息。
###### MongoDB的Arbiter节点角色
MongoDB虽然出现和流行比MySQL晚,但MongoDB在高可用架构上的进化速度相比MySQL快很多,其实应该说是MySQL在这方面太落后了。相信现在没有人会新建基于Master-Slave高可用的MongoDB实例,复制集/ReplicaSet是MongoDB在生产环境的标准配置,在部署成本这块,MongoDB提供了[Arbiter角色](Replica Set Arbiter),只不过,MongoDB的Arbiter只有投票功能,连oplog日志也没有。

Since the arbiter does not hold a copy of the data, these deployments provides only one complete copy of the data. Arbiters require fewer resources, at the expense of more limited redundancy and fault tolerance.
However, a deployment with a primary, secondary, and an arbiter ensures that a replica set remains available if the primary or the secondary is unavailable. If the primary is unavailable, the replica set will elect the secondary to be primary.
对于我们来说,初衷也是想增加一个投票节点,不保存数据。至于是否有日志(Binlog),这不是重要的考虑因素。所以,将角色名取为Arbiter。
#### 四、Arbiter方案可行性
有了想法,那就看看是否有可行性,如果认为可行,那就需要进行原型验证。这里,我们要节省的成本主要分为2块,计算和存储:计算上尽可能降低内存和cpu开销,存储上尽可能减少需保存的数据量。
##### 如何不保存数据?
其实,在MySQL中,一个节点不保存数据是很容易的,因为MySQL提供了Blackhole存储引擎,只要将存储引擎从InnoDB改为Blackhole就能办到。如下所示:
```
node1>show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mysql |
| performance_schema |
| sys |
+--------------------+
4 rows in set (0.01 sec)
node1>create database hzwenzhh;
Query OK, 1 row affected (0.00 sec)
node1>use hzwenzhh
Database changed
node1>create table t1 (a int primary key, b varchar(10)) engine=blackhole;
Query OK, 0 rows affected (0.00 sec)
node1>insert into t1 values (1,'10');
Query OK, 1 row affected (0.00 sec)
node1>select * from t1;
Empty set (0.00 sec)
node1>update t1 set a=2 where a=1;
Query OK, 0 rows affected, 1 warning (0.00 sec)
Rows matched: 0 Changed: 0 Warnings: 1
node1>show warnings;
+---------+------+-------------------------------------------------------------------------------------------------------------+
| Level | Code | Message |
+---------+------+-------------------------------------------------------------------------------------------------------------+
| Warning | 1870 | Row events are not logged for UPDATE statements that modify BLACKHOLE tables in row format. Table(s): 't1.' |
+---------+------+-------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
node1>exit
Bye
hzwenzhh@innosql3:~$ ls -lh node1/data/hzwenzhh/
total 16K
-rw-r----- 1 hzwenzhh neteaseusers 67 Jan 3 15:44 db.opt
-rw-r----- 1 hzwenzhh neteaseusers 8.4K Jan 3 15:44 t1.frm
hzwenzhh@innosql3:~$
```创建一个blackhole类型的表t1,插入一条记录后select没有插入的记录,update出现一个warning。查看对应的数据目录发现只有t1.frm元文件,没有对应的数据文件。这说明blackhole满足我们基本的需求。
##### 如何作为secondary节点?
引入blackhole引擎后,面临的个问题是能否作为从/备节点,也就是主节点的引擎是InnoDB,从节点对应表的引擎是blackhole?显然,DDL操作应该不影响,DML是重点,其中Insert没有问题,Delete和Update会如何?为此做些实验:
**一、将node2的默认存储引擎设置为blackhole,将其作为node1的从节点。主上执行建表操作并增加一个二级索引:**
```
node1>use hzwenzhh
Database changed
node1>create table t1 (a int primary key, b varchar(10));
Query OK, 0 rows affected (0.00 sec)
node1>show create table t1;
+-------+-----------------------------------------------------------------------------------------------------------------------------------------+
| Table | Create Table |
+-------+-----------------------------------------------------------------------------------------------------------------------------------------+
| t1 | CREATE TABLE `t1` (
`a` int(11) NOT NULL,
`b` varchar(10) DEFAULT NULL,
PRIMARY KEY (`a`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 |
+-------+-----------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.01 sec)
node1>alter table t1 add index b_idx(b);
Query OK, 0 rows affected (0.00 sec)
Records: 0 Duplicates: 0 Warnings: 0
node1>show create table t1;
+-------+--------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Table | Create Table |
+-------+--------------------------------------------------------------------------------------------------------------------------------------------------------------+
| t1 | CREATE TABLE `t1` (
`a` int(11) NOT NULL,
`b` varchar(10) DEFAULT NULL,
PRIMARY KEY (`a`),
KEY `b_idx` (`b`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4 |
+-------+--------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
```从上通过复制回放得到的t1如下:
```
node2>show variables like "%default_storage%";
+------------------------+-----------+
| Variable_name | Value |
+------------------------+-----------+
| default_storage_engine | BLACKHOLE |
+------------------------+-----------+
1 row in set (0.00 sec)
node2>show create table t1;
+-------+--------------------------------------------------------------------------------------------------------------------------------------------+
| Table | Create Table |
+-------+--------------------------------------------------------------------------------------------------------------------------------------------+
| t1 | CREATE TABLE `t1` (
`a` int(11) NOT NULL,
`b` varchar(10) DEFAULT NULL,
PRIMARY KEY (`a`)
) ENGINE=BLACKHOLE DEFAULT CHARSET=utf8mb4 |
+-------+--------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
node2>show create table t1;
+-------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------+
| Table | Create Table |
+-------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------+
| t1 | CREATE TABLE `t1` (
`a` int(11) NOT NULL,
`b` varchar(10) DEFAULT NULL,
PRIMARY KEY (`a`),
KEY `b_idx` (`b`) // 新增的二级索引
) ENGINE=BLACKHOLE DEFAULT CHARSET=utf8mb4 |
+-------+-----------------------------------------------------------------------------------------------------------------------------------------------------------------+
1 row in set (0.00 sec)
```**二、通过上面实验,我们先认为这种部署方式下,执行DDL是没有问题的。接下来试试Insert和Delete操作:**
```
node1>insert into t1 values (1,'hzwenzhh');
Query OK, 1 row affected (0.00 sec)
node1>show master status\G
*************************** 1. row ***************************
File: mysql-bin.000002
Position: 1357
Binlog_Do_DB:
Binlog_Ignore_DB:
Executed_Gtid_Set: 0b91f44e-2dff-11ea-b898-246e963b3e60:1-6
1 row in set (0.00 sec)
node1>delete from t1 where a=1;
Query OK, 1 row affected (0.00 sec)
node1>show master status\G
*************************** 1. row ***************************
File: mysql-bin.000002
Position: 1610
Binlog_Do_DB:
Binlog_Ignore_DB:
Executed_Gtid_Set: 0b91f44e-2dff-11ea-b898-246e963b3e60:1-7
1 row in set (0.00 sec)
```从节点情况:
```
node2>show master status\G
*************************** 1. row ***************************
File: mysql-bin.000003
Position: 430
Binlog_Do_DB:
Binlog_Ignore_DB:
Executed_Gtid_Set: 0b91f44e-2dff-11ea-b898-246e963b3e60:1-6
1 row in set (0.00 sec)
node2>select * from t1;
Empty set (0.00 sec)
node2>show master status\G
*************************** 1. row ***************************
File: mysql-bin.000003
Position: 670
Binlog_Do_DB:
Binlog_Ignore_DB:
Executed_Gtid_Set: 0b91f44e-2dff-11ea-b898-246e963b3e60:1-7
1 row in set (0.00 sec)
```**三、从库看起来也是一切正常,继续执行update操作:**
```
node1>insert into t1 values (1,'hzwenzhh');
Query OK, 1 row affected (0.00 sec)
node1>update t1 set a=2 where a=1;
Query OK, 1 row affected (0.00 sec)
Rows matched: 1 Changed: 1 Warnings: 0
node1>show master status\G
*************************** 1. row ***************************
File: mysql-bin.000002
Position: 2131
Binlog_Do_DB:
Binlog_Ignore_DB:
Executed_Gtid_Set: 0b91f44e-2dff-11ea-b898-246e963b3e60:1-9
1 row in set (0.00 sec)
```从库看起来也没问题,出乎意外。在主从复制下没有问题,进一步又在MGR secondary节点做了验证,确认DML也是没有问题的。
```
node2>show master status\G
*************************** 1. row ***************************
File: mysql-bin.000003
Position: 1165
Binlog_Do_DB:
Binlog_Ignore_DB:
Executed_Gtid_Set: 0b91f44e-2dff-11ea-b898-246e963b3e60:1-9
1 row in set (0.00 sec)
```##### Binlog文件保存问题?
在上述验证的基础上,使用sysbench工具跑了下oltp测试(修改了common.lua,去掉建表时的engine字段),确认虽然数据文件没有了,但是Binlog和relay-log还是存在的,可以通过[relay_log_space_limit](16.1.6.3 Replication Slave Options and Variables)和[binlog_expire_logs_seconds](17.1.6.4 Binary Logging Options and Variables)来控制两者的大小(binlog_expire_logs_seconds该参数在社区版8.0提供,InnoSQL在5.7.20版本开始提供。),如果将max_binlog_size设置小些,binlog_expire_logs_seconds设置为分秒级可以达到接近不记录Binlog的作用。
个人认为,应该视Arbiter节点部署时的具体用途来决定,保留一定时间内的Binlog文件并不会过多占用存储空间,而且有额外的作用,包括可以用来作为其他节点进行分布式故障恢复的源节点(donor),另外可以作为第三方工具拉通Binlog的源节点,这样可以降低MGR数据节点的负载,进一步发挥Arbiter节点的作用。
##### DDL转换问题?
通过调整参数配置,可以实现MGR的Arbiter节点功能。不过,还有个点需要解决,那就是DDL语句的引擎问题。对于没有MySQL源码修改能力的团队,可以通过不在DDL中指定engine字段,并将Arbiter节点的默认存储引擎设置为blackhole来适配。
##### 仍有优化余地
通过上面的验证,只要确保DDL语句不带engine字段,就可以在不修改MySQL源码的情况下,做到MGR的部署成本大幅降低。
- * 从存储层面,基本上可以省的空间都省了,Binlog还是有使用价值的,可选择保留。
- * 在计算层面,内存消耗得到了很大控制,占大头的InnoDB buffer pool所需内存已节省。在cpu这块,虽然省了引擎层的事务逻辑等计算和IO开销,但Server层的计算消耗还有优化的余地,如果不要Binlog文件,那么完全可以将relay-log文件和MGR的Binlog回放流程都取消掉。
#### 五、Arbiter实现方案
虽然不修改MySQL源码可享受Arbiter功能,但在部署和使用上多有不便,且做得并不彻底。好的方式应该是从代码层面提供完整的Arbiter特性,下面对其实现方案进行分析。根据所需修改的MySQL源码数量和所涉及的模块,Arbiter特性实现时可以分为相对独立的2个迭代。
##### 迭代一 完整的功能集
这个迭代解决的是Arbiter特性的可用和易用性问题,实现功能包括:
- 增加一个MGR变量用于指定Arbiter角色,如arbiter_member=ON。角色的作用包括设置默认存储引擎为blackhole,将member_weight设置为0,由于该参数值会同步给其他MGR节点,因此实际上起到了无被选举权的作用;
- 提供一个初始化工具。该工具的作用是在Arbiter新节点加入MGR集群前,从其他节点通过mysqldump --no-data/-d 选项来获取schema信息用来初始化Arbiter节点,在将schema信息导入前,需要将建表语句的engine字段从innodb替换为blackhole;
- DDL语句引擎自动转换功能。该功能用于在Arbiter节点加入集群后,回放relay-log时,将create table和alter table等可能携带存储引擎字段(engine)的DDL语句自动修改为blackhole,防止因为回放了InnoDB引擎的DDL语句而产生数据文件;
##### 迭代二 提供更多可选参数
这个阶段是Arbiter功能的扩展,通过暴露可选参数让用户决定Arbiter节点的实际用途,实现功能包括:
- 增加一个MGR变量用于选择是否需要Binlog日志,如arbiter_no_binlog。可保留Binlog日志,也可选择不产生Binlog。如果为OFF,那么无需做任何额外改动。
如果该选项为ON,那么其实有难易两种实现方法:
- 简单的方法是取消Arbiter节点的log_slave_update为ON的限制。
- 另一种方法就是直接将relay-log也去掉,这也是应该采用的实现方式,方案详细介绍如下。
###### Arbiter节点无日志功能方案
因为MGR的Applier模块采用的是pipeline实现方式,其实实现也不是很难,如下所示:
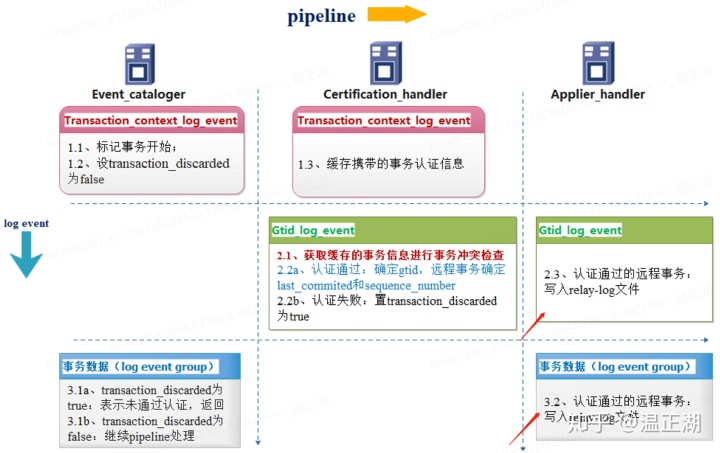
这给功能实现增加了很多便利。理论上说,只需要进行如下适配即可:
- 2.2a确定了gtid后,直接将gtid更新到gtid_executed全局变量中,无需再确定last_commit和sequence_number。修改的是certification_handler的处理函数;
- 2.3和3.2这两步过滤掉所有的用户表DML操作,仅写入DDL语句,修改的是applier_handler的处理函数;
##### 六、总结
MGR是极具吸引力的MySQL高可用方案,但由于其部署成本相比普通高可用实例高,限制了其使用场景。本文为MGR新增Arbiter节点,仅需低规格云主机和小容量数据盘即可进行Arbiter节点部署,大大降低其部署成本,相比普通高可用实例,只需非常有限的新增投入就可以享受到MGR带来的诸多好处,为MGR的广泛使用扫除障碍,可极大拓宽其使用场景。相信MGR能够成为未来MySQL在生产环境部署的标准高可用配置。
注:文中图片若有版权问题,请告知删除。
