转自:https://greenplum.cn/2019/10/30/greenplum6-0-open-class/
昨天(2019年10月29日)晚上8点,北京室外寒风凛冽,但线上的Greenplum 6.0直播室却热火朝天。Greenplum研发工程总监杨瑜在直播过程中为大家分享了Greenplum 6.0诸多新特性,并对Greenplum 7.0的新功能特性进行了展望。没有参加活动的小伙伴也不用担心哦,让我们用一篇文章带你回顾公开课的所有干货!
Greenplum是基于MPP架构的,开源的,集机器学习和人工智能处理能力于一体的数据平台。 9月4日发布的Greenplum 6.0版本在功能和性能上都有了大幅提升,在并发性上的改进尤为显著,对OLTP型和混合负载业务的支持更为强大,是Greenplum发展的重要里程碑。
Greenplum是基于PostgreSQL的MPP数据库。此次Greenplum 6.0的发布,其Postgres内核进行了大幅度的升级。Greenplum6的内核从Greenplum 5的Postgres8.3版本的内核一直升级到Postgres9.4版本的内核,一共升级11720个提交,包括了非常多的Postgres新特性。

此外,在这一版的Greenplum中,OLTP性能得到了大幅度提升,经内部在GCP上的测试,Greenplum 的TPCB提升了70倍。其中更新操作的TPS达到24448次,插入操作的TPS达到46570次,查询操作的TPS达到14万次。这一重大优化使得Greenplum能够更好的胜任混合查询的应用场景。


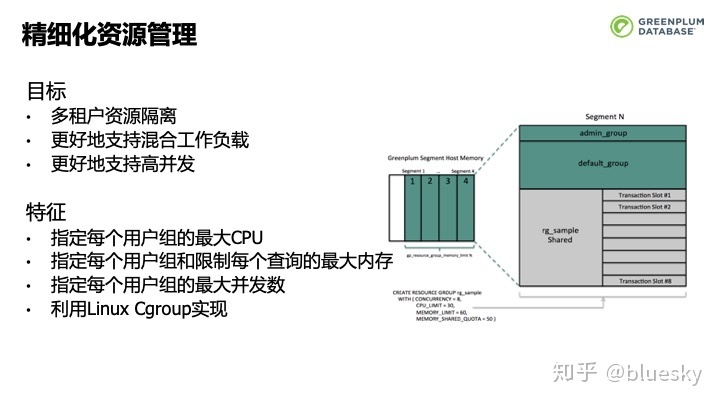
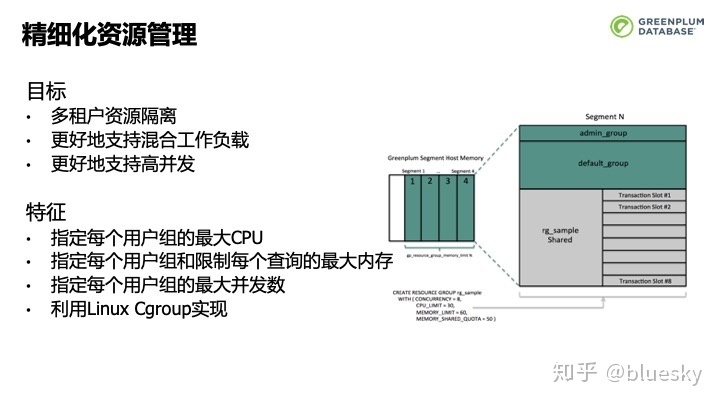
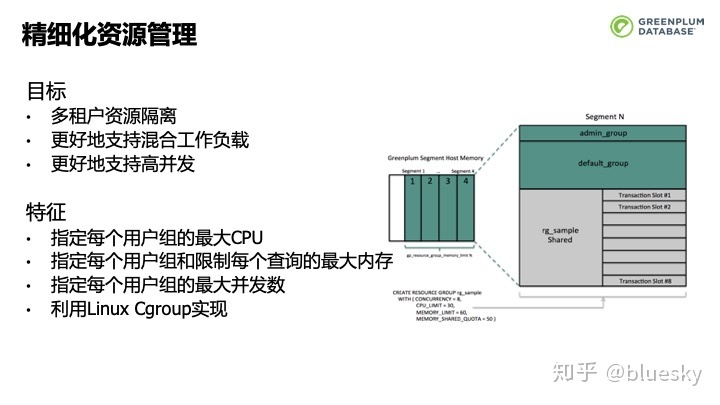
为了对多租户提供更好的资源隔离,更好的支持混合工作负载和高并发,我们在此版本中引入了资源组。我们可以指定每个资源组能使用的大CPU,控制每个查询所使用的大内存,还可以指定每个资源组的大并发数,这一切都是利用Linux Cgroup实现的。
在多租户的场景下,磁盘配额是与租户的SLA(Service Level Agreement)的一部分。Greenplum 支持Schema和用户级别的磁盘配额创建和管理。当磁盘使用量达到限额时,将阻止用户继续占用磁盘空间。Greenplum的磁盘配额是基于 Extension framework和Background worker framework实现的。在Extension framework下,可以减少对Greenplum内核的侵入,易于turn on/off。由于Diskquota的工作是使用独立的进程完成的, 现在Greenplum也做到了Diskquota的进程的启动无需重启Greenplum。
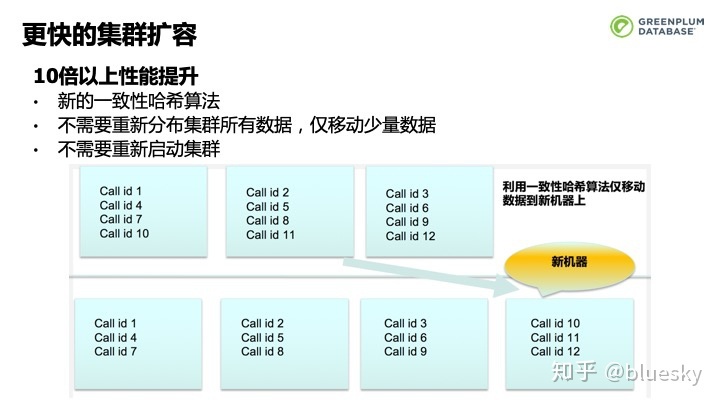

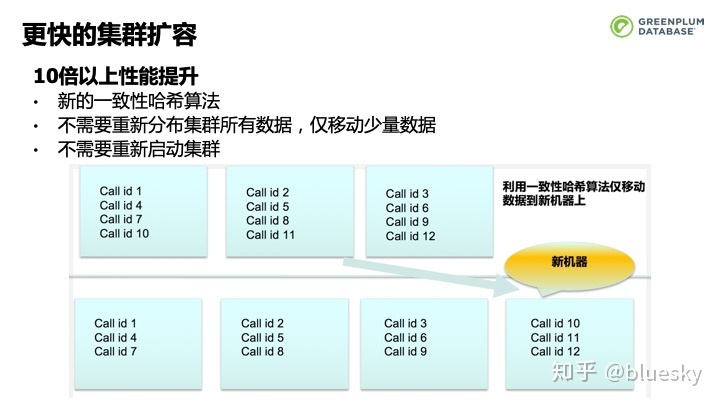
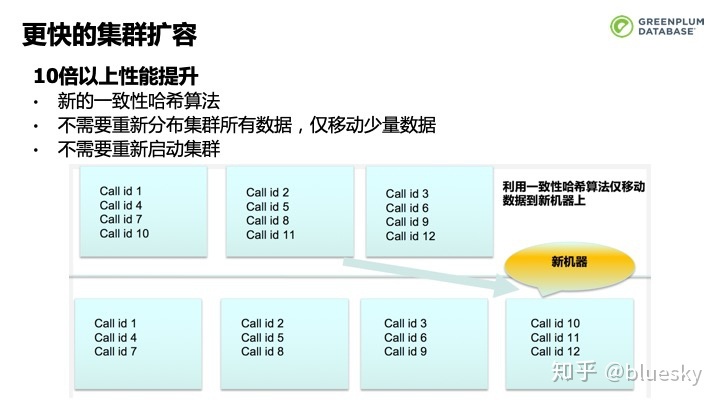
针对用户实际使用场景的痛点,我们对集群的扩容进行了优化和增强。Greenplum 6.0引入了一致性哈希算法,新的算法不使得Greenplum不需要重新分布集群所有数据,仅移动少量数据,也不需要重新启动集群,从而有效减少因为增加机器节点需要挪动的数据量。
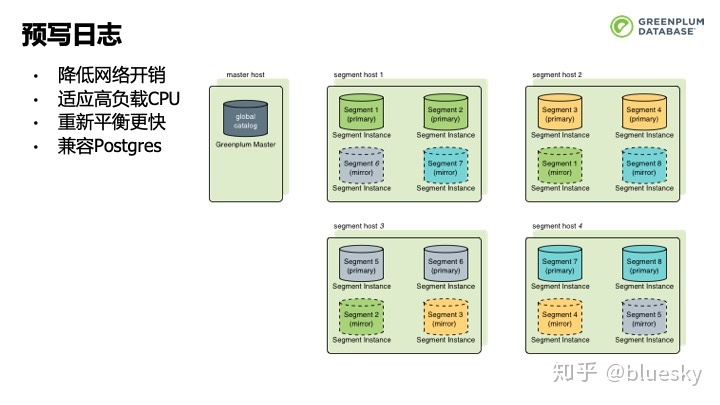

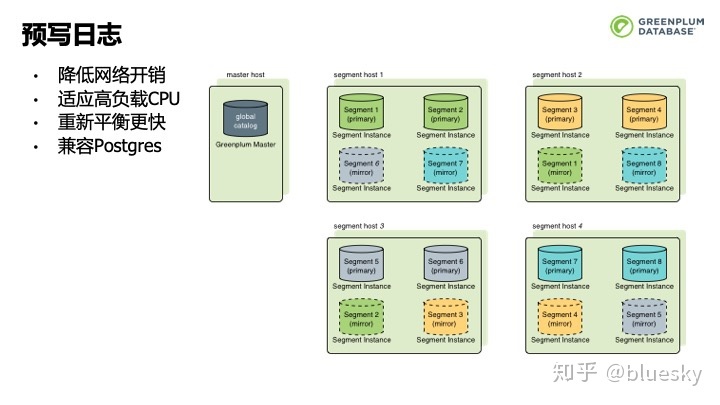
此外,新版本的Greenplum引入了预写日志来进行主备节点间数据的同步。预写日志支持以增量的方式复制数据,相比于之前的FileRep,减少了网络开销,提高了响应速度。

针对用户场景中的痛点,Greenplum 6.0开始支持复制表。例如:当用户想将城市列表作为小表,每个节点上各放一份并行数据过滤,在之前的版本中是没法做到的,但新的版本中使用复制表可以很容易实现。
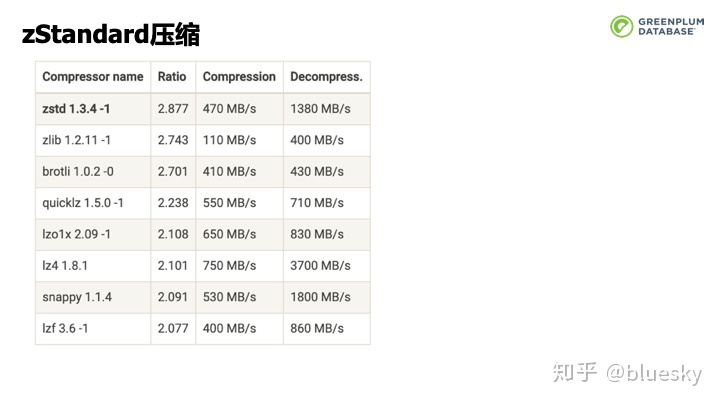
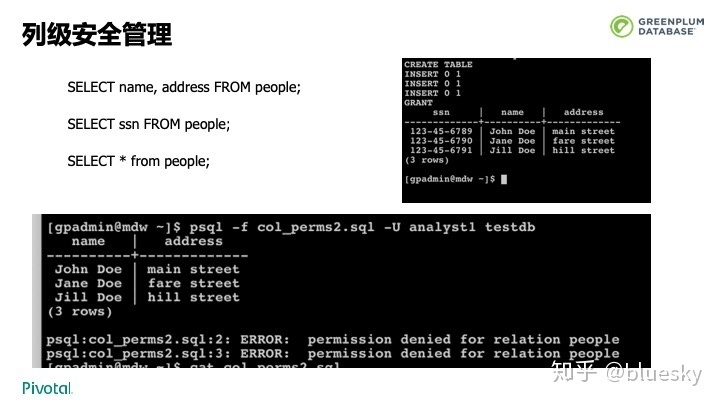
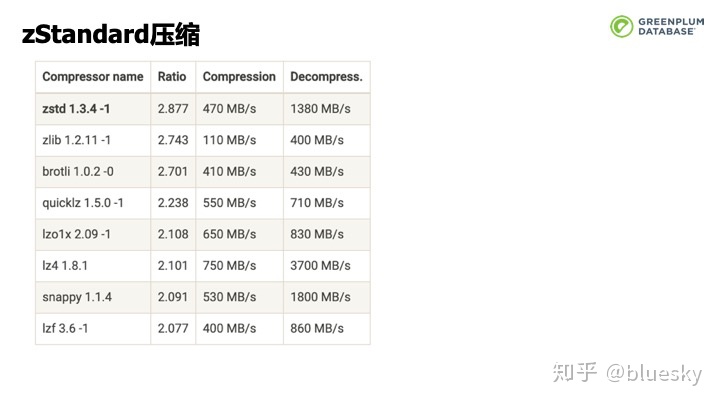
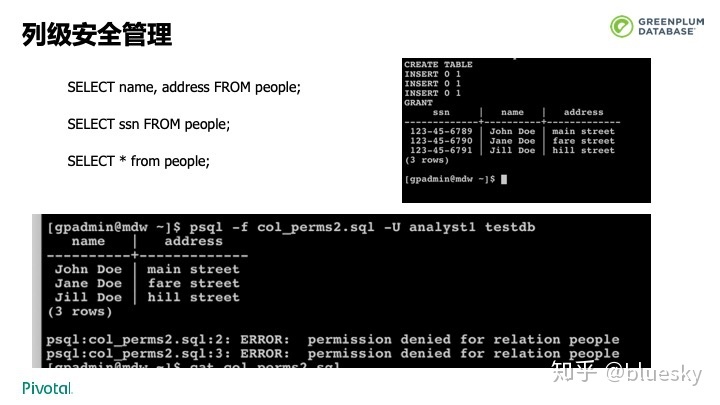
同时,在Greenplum 6.0中,我们升级了压缩,在获得更高压缩率的同时,压缩和解压速度也得到了大幅提升。此外,我们也提供了对表数据更为细粒度的权限管理。用户可以控制列的访问权限而不再是粗粒度的整个表。
针对用户想要更快的大批量倒入数据的情况,我们支持了Unlogged表。对该表的修改不需要写日志,所以性能比普通表要快得多,但是如果系统发生崩溃,数据可能会丢失。用户可以根据自己的应用场景合理选择。


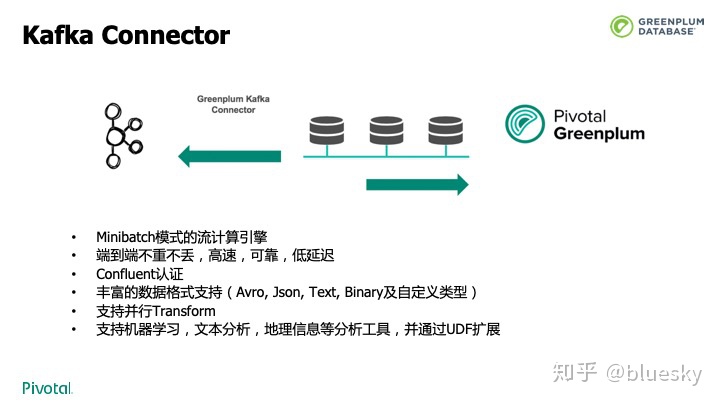
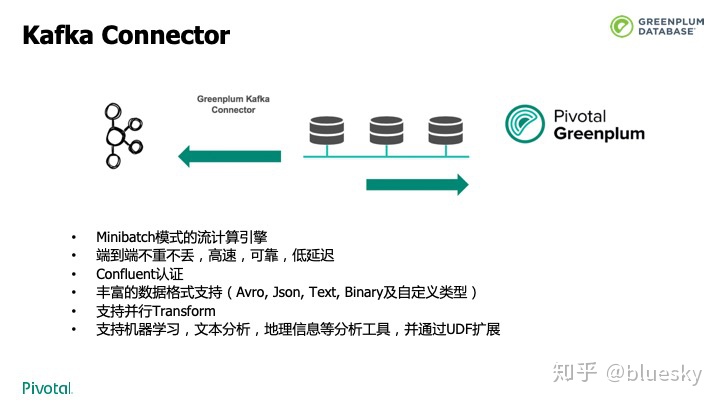
在Greenplum 6.0中,很多组件也进行了升级。为了更快的,低延迟,不重不丢的导入流式数据,我们研发了Kafka 连接器。支持exactly once语义,支持并行消息处理、窗口,多种数据类型,和多字节分隔符等。
监控方面,Greenplum监控工具GPCC也对Greenplum 6进行了支持,用户无需运行额外的gpperfmon服务进程就可以获取查询的详细信息。 此外,用户还可以使用过滤器缩小历史日志的查询范围,并通过GPCC监控standby master的状态 。


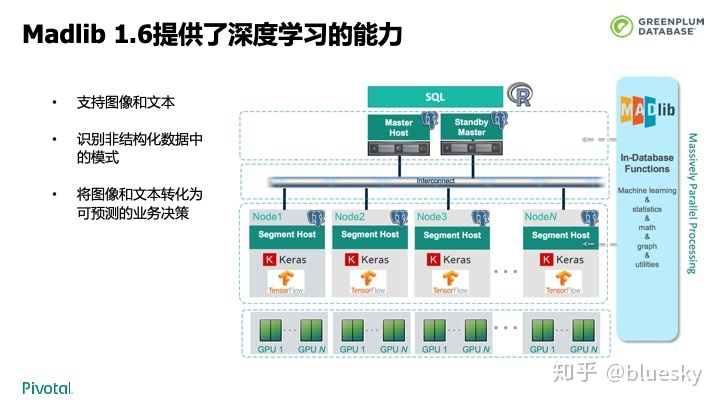
除了传统的数仓, Greenplum 还通过Apache 开源项目 MADLib 实现了对数据库内分析的支持。Madlib 1.6提供了强大的深度学习算法,以内置数据库的方式在Greenplum中运行,将计算发送到数据节点,而不是数据拉到计算节点,性能更好。对图像,文本,半结构化数据都能很好的支持。

Greenplum 6.0是Greenplum大数据平台一个里程碑的版本。这次发布与以往不同的是,基于开源协议的Greenplum 6.0社区版也在同一天发布, 感兴趣的爱好者可以前往Github下载尝试。


如今,在Greenplum工程师的努力下,内核升级到Postgres 9.5的工作已经完成,在新的内核版本中,将包括 Upset,行级安全管理,Block Range Indices等特性,排序性能和多CPU机器性能将大幅提升。

同时,内核升级到Postgres 9.6的工作也已经开始,包括并行执行顺序扫描,Join和聚合、避免在Vacuum操作期间不必要地扫描存储页 、全文检索具备搜索短语能力(多个相邻单词)、postgres_fdw支持远程Join,排序,更新和删除等多个特性即将集成,性能也将大幅提升,尤其是在多CPU插槽服务器上的可扩展性方面 。Postgres 9.5和9.6都将被包含到Greenplum 7.0版本中。

此外,多中心数据复制正在有条不紊的开展中,包括预写日志、对故障转移和故障恢复的支持,数据可用性的大化,对冷热待机的支持,对数据安全的提高等功能都将包含在Greenplum 7.0中。

在Greenplum 7.0版本中,用户还可以期待跨集群的查询能力。该能力可以让用户可以快速可靠的跨Greenplum集群查询,从而达到“扩大”Greenplum集群规模的作用,得以减少数据冗余,可以支持跨集群表间Join和谓词下推。


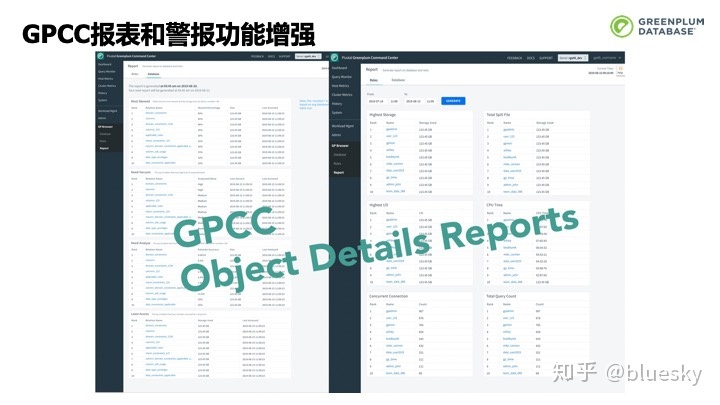
Greenplum官方监控工具GPCC报表和警报功能将在Greenplum 7.0版本进行增强。将支持更加详细丰富的报表,并能够对表数据空间进行跟踪和报警。

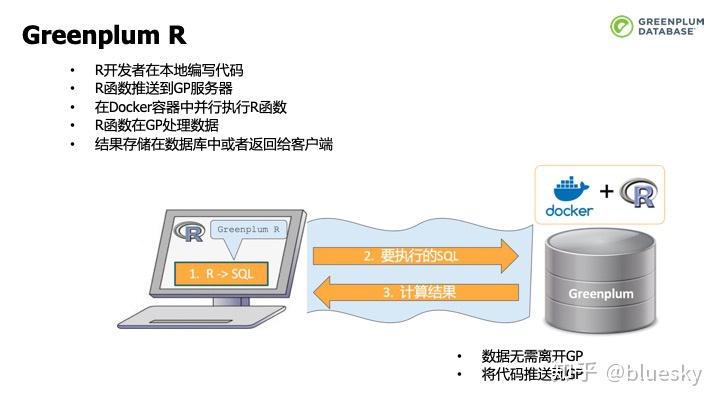
此外,Greenpum还提供了2种方式让用户得以自行进行扩展。种方式是通过Procedure Language(PL), 另一种方式则是为开发人员提供透明的计算能力,首先会支持R,这就是GreenplumR项目。 通过这个项目,R开发者可以在本地编写代码,将R函数推送到Greenplum服务器上,在Docker容器中并行执行R函数。通过R函数在Greenplum上处理数据。将结果存储在数据库中或返回给客户端。整个过程对R开发人员透明,同时也可以获得Greenplum提供的强大的并行计算能力。
无论是内核,HTAP能力,还是关键业务的可用性、不断优化的监控系统,Greenplum一直在不断创新,我们期待在接下来的Greenplum版本中,可以为用户提供更多惊喜。
