本文是MySQL Group Replication(MGR)不足和优化系列文章的延续。在之前的文章中讲了事务认证机制/冲突检测数据库不足和优化。其中的优化点在我们的InnoSQL 5.7.20-v3b版本上实现,其优化效果也得到了初步验证。本篇文章主要分析作为MGR底层的节点间网络通信层(Paxos)存在的问题及其优化。
###### 前言
从InnoSQL 5.7.20 GA到InnoSQL 5.7.20-v3b版本,我们持续对MGR进行着优化。截止目前,MGR已经在多个业务场景上得到了验证,应该说在绝大部分业务场景下MGR都能够运行良好。但在测试过程中,我们也发现在一些特别的场景下仍存在问题,典型的场景是在批量导数据时,比如使用NDC在不同MySQL实例间迁移数据。或者使用sqoop工具将数据从大数据系统迁移到MySQL实例上。为了提高迁移效率,常常会将多条记录batch成一个事务进行批量插入,同时增加并发度。一般来说,如果待迁移的表中每条记录的大小较小时,并不会有什么问题。但若记录本身较大,或batch个数较多,再加上并发度较大时。往往会导致迁移过程中mysqld占用的内存不断增涨。若mysqld增涨的内存超过了系统可用内存,则会引发OOM。
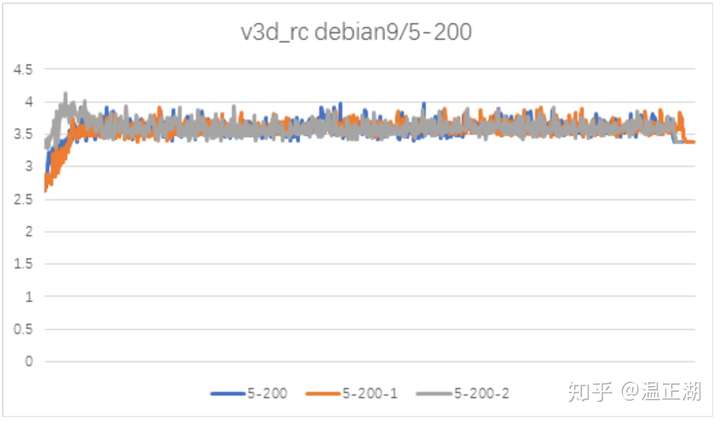
上图是我们在某个业务表上使用NDC进行数据迁移,设置的参数是5个事务并发,每个事务200条记录(约30MB),图中展示了3次测试过程中的内存曲线。可以看到整个过程内存非常平稳。当我们把并发数从5提高为10时,情况就变得比较糟糕。如下图所示。
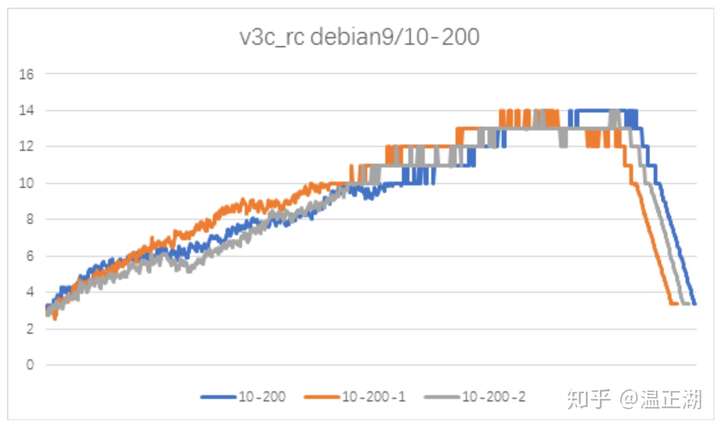
在10并发场景下,随着测试的进行,mysqld内存线性增涨。测试结束后,内存又快速恢复到初始值。如果数据量较大,迁移时间较长,那么就可能导致mysqld OOM。尤其是在云环境下,每个mysqld允许的内存增长空间有限的情况下问题会更加突出。
我们在MySQL主从复制部署模式下也进行了相同的测试。结果发现内存并没有出现线性增涨的情况。所以确认是MGR模块导致的。
##### 问题现象及解释
在内存增长期间,我们观察了节点的网卡流量均已达到瓶颈。同时mysqld系统日志中也会出现2类不寻常的日志信息,下面逐一进行分析。
###### 周期性广播消息紊乱
类日志如下:
```
[Warning] Plugin group_replication reported: 'The member with address 10.177.12.212:3331 has already sent the stable set. Therefore discarding the second message.'
[Warning] Plugin group_replication reported: 'The member with address 10.177.12.211:3331 has already sent the stable set. Therefore discarding the second message.'
```
该日志对应的代码位于http://certifier.cc中,也就是说是与冲突检测/事务认证模块相关的,具体代码如下:
```
/*
As member is already received we can throw the necessary warning of the
member message already received.
*/
Group_member_info *member_info=
group_member_mgr->get_group_member_info_by_member_id(gcs_member_id);
if (member_info != NULL)
{
log_message(MY_WARNING_LEVEL, "The member with address %s:%u has "
"already sent the stable set. Therefore discarding the second "
"message.", member_info->get_hostname().c_str(),
member_info->get_port());
}
```
在上一篇文章中曾提到:
MGR每个节点都以固定的时间间隔(MySQL社区版为60s,在我们InnoSQL中可通过group_replication_broadcast_gtid_executed_period参数可调)来广播自己的gtid_executed信息,节点收集了MGR集群中各个节点的gtid_executed信息后,取交集来清理冲突检测数据库中不再需要的writeset信息(包括事务更新的主键/键信息、该键值对应的快照版本和用于确定并行复制行为的sequence_number)。
我们假设MGR的3个节点分别是10.177.12.211:3331、10.177.12.212:3331和10.177.12.213:3331,其中10.177.12.213:3331为Primary节点。该日志的意思是在没有收到10.177.12.213:3331节点gtid_executed消息的情况下又重复收到了其他2个节点的新消息。问题的重点是10.177.12.213:3331为什么没有广播gtid_executed消息呢?
节点的gtid_executed广播间隔/周期一般为20s,如果各个节点周期一样且都存活的情况下(确认如此),显然不应该出现这种情况。为什么?我们先提出疑问。
###### 获取Paxos日志/消息失败
再看第二类:
```
[Note] Plugin group_replication reported: 'dispatch_op /home/hzwenzhh/build-dir/rapid/plugin/group_replication/libmysqlgcs/src/bindings/xcom/xcom/xcom_base.c:3847 die_op executed_msg={1355c950 6746 1} delivered_msg={1355c950 6746 1} p->synode={1355c950 6748 2} p->delivered_msg={1355c950 6764 0} p->max_synode={1355c950 6763 2} '
```
什么时候会打印该日志呢。我们从xcom_base.c代码里面看看die_op是怎么回事:
```
if (/*ep->p->op == prepare_op && */ **was_removed_from_cache**(ep->p->synode)) {
DBGOUT(FN; STRLIT("send_die ");
STRLIT(pax_op_to_str(ep->p->op));
NDBG(ep->p->from, d); NDBG(ep->p->to, d);
SYCEXP(ep->p->synode);
BALCEXP(ep->p->proposal));
if (get_maxnodes(site) > 0) {
pax_msg * np = NULL;
np = pax_msg_new(ep->p->synode, site);
ref_msg(np);
np->op = die_op;
np->to = ep->p->from;
np->from = ep->p->to;
np->delivered_msg = get_delivered_msg();
np->max_synode = get_max_synode();
DBGOUT(FN; STRLIT("sending die_op to node "); NDBG(np->to, d);
SYCEXP(executed_msg); SYCEXP(max_synode); SYCEXP(np->synode));
serialize_msg(np, ep->rfd.x_proto, &ep->buflen, &ep->buf);
if(ep->buflen){
int64_t sent;
TASK_CALL(task_write(&ep->rfd , ep->buf, ep->buflen, &sent));
send_count[ep->p->op]++;
send_bytes[ep->p->op] += ep->buflen;
X_FREE(ep->buf);
}
ep->buf = NULL;
unref_msg(&np);
}
}
```
简单来说,就是某个节点A向其他节点B发送请求某个(已经达成majority的)消息(消息有价值的部分是其中的value,可能是事务数据或MGR的周期性状态广播数据等)时,因为Paxos cache的大小有限,在节点B上,该消息已经从cache中移除(was_removed_from_cache),所以B就给A回复一个die_op消息。如果A向另一个节点C也无法获取该消息时,那么节点A就会打印如下消息并退出。
```
[ERROR] Plugin group_replication reported: 'Node 1 unable to get message, process will now exit. Please ensure that the process is restarted'
```
对应代码逻辑:
```
case die_op:
/* assert("die horribly" == "need coredump"); */
{
GET_GOUT;
FN;
STRLIT("die_op ");
SYCEXP(executed_msg);
SYCEXP(delivered_msg);
SYCEXP(p->synode);
SYCEXP(p->delivered_msg);
SYCEXP(p->max_synode);
PRINT_GOUT;
FREE_GOUT;
}
/*
If the message with the number in the incoming die_op message
already has been executed (delivered), then it means that we
actually got consensus on it, since otherwise we would not have
delivered it.Such a situation could arise if one of the nodes has
expelled the message from its cache, but others have not. So when
sending out a request, we might get two different answers, one
indicating that we are too far behind and should restart, and
another with the actual consensus value. If the value arrives
first, we will deliver it, and then the die_op may arrive later.
But it this case it does not matter, since we got what we needed
anyway. It is only a partial guard against exiting without really
needing it of course, since the die_op may arrive first, and we
do not wait for a die_op from all the other nodes. We could do
that with some extra housekeeping in the pax_machine (a new bit
vector), but I am not convinced that it is worth the effort.
*/
if(!synode_lt(p->synode, executed_msg)){
g_critical("Node %u unable to get message, process will now exit. Please ensure that the process is restarted",
get_nodeno(site));
exit(1);
}
```
从注释中我们可以发现,B分别向A和C发送请求获取对应消息时,如果C节点还保有该消息,A节点上该消息已经被移除,那么B节点的mysqld是否退出取决C和A节点回复B的消息谁先到达。如果C先达到,那么仅打印die_op日志,如果A先到达,则打印ERROR日志,mysqld退出。
无论mysqld是否退出,打印上述日志已经意味着该节点的Paxos日志落后其他节点很多。对于3节点的MGR集群,一个消息要达成majority至少需要2个节点参与,那么会有一个节点存在paxos日志延迟。
##### 问题危害性
MGR在网络不好和大事务场景下性能和稳定性较差是众人皆知的,MySQL官方也是承认这点的。但并没有具体说明是什么原因导致的。而且,就我们的测试场景而言,30MB左右的事务并不能算很大的事务,该问题若不解决的话就需要业务迁就数据库做出妥协,比如限制NDC或sqoop导数据时的并发数或batch大小,要求业务不能进行频繁地在一个事务中进行大批量的数据DML操作。显然这不是搞数据库内核的人希望看到的。但什么模块会大量占用内存呢?结合MGR的模块示意图进行分析:
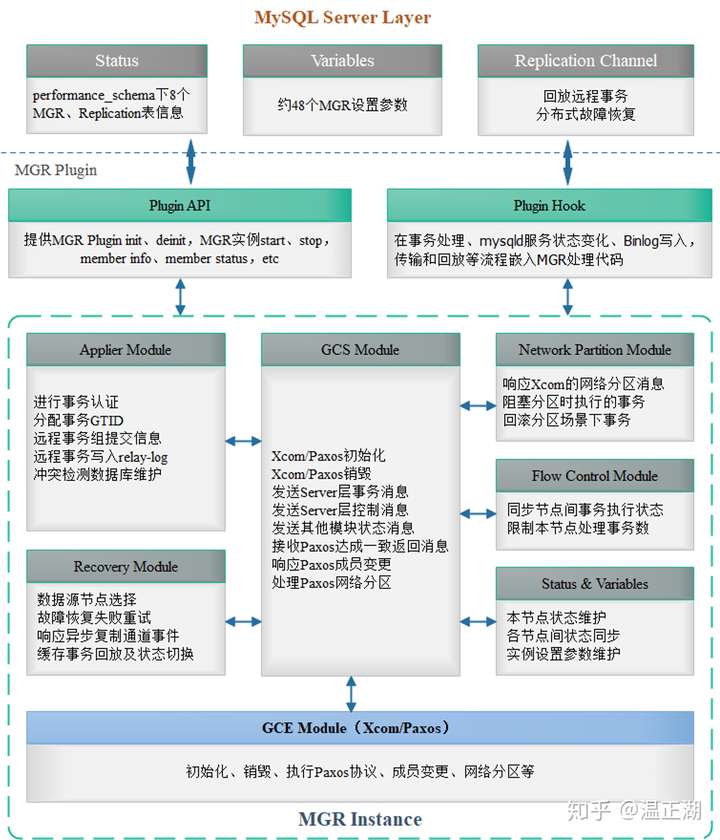
##### 问题分析和定位
在这之前,我们已经对MGR上层的事务认证模块做了比较彻底的优化,可以比较有信心的认为内存增涨不大可能由事务认证模块引起的,况且该模块也不可能直接影响到网络层。所以,先排除了事务认证模块的影响,把目光分别向上和向下看,向上怀疑Plugin Hook层是否存在事务堆积,向下怀疑Xcom/Paxos层占用过多内存和网络资源(由于出现问题时网络已经处于瓶颈状态,这个可能性更大)。下面一一进行分析。
###### Plugin Hook层事务堆积
每个本地事务执行到commit阶段时,都需要通过Hook进入MGR层处理,如果MGR层处理过慢,就可能导致MySQL Server层的事务在MGR入口处堆积,对应的代码处理逻辑是group_replication_trans_before_commit。恰巧,该函数里面有个队列很可疑:
```
/*
Map to store all open unused IO_CACHE.
Each ongoing transaction will have a busy cache, when the cache
is no more needed, it is added to this list for future use by
another transaction.
*/
typedef std::list<IO_CACHE*> IO_CACHE_unused_list;
static IO_CACHE_unused_list io_cache_unused_list;
```
事务commit时会将事务的DML操作和产生的writeset带入MGR,在MGR中使用IO_CACHE对象将writeset格式化为Binlog Event,跟事务的其他Binlog Event一起封装为事务消息传递给Paxos。如下所示:

嫌疑在于:事务完成认证并返回给MySQL Server层后,对应的IO_CACHE对象内存并不会立即释放,而是缓存起来供后续事务复用,如下所示:
```
/*
Save already initialized cache for a future session.
@param[in] cache the cache
*/
void observer_trans_put_io_cache(IO_CACHE *cache)
{
DBUG_ENTER("observer_trans_put_io_cache");
io_cache_unused_list_lock->wrlock();
io_cache_unused_list.push_back(cache);
io_cache_unused_list_lock->unlock();
DBUG_VOID_RETURN;
}
```
如果事务较大,且并发较高,那么就会占用可观的内存。为此,我们加了些debug信息来统计io_cache_unused_list中IO_CACHE个数和总大小,测试结果表明,其并没有占据多少内存空间。这个结果是可以理解的,因为NDC导数据场景,事务并发数是固定的,导入操作时同步的,比如10个并发,那么在当前10个事务未返回前,下一批10个事务是不会执行的。所以不会有事务堆积在MGR层的入口。
###### Xcom层Paxos cache大小超限
既然向上看的模块没有问题。那就再看看Xcom/Paxos层了。对于Paxos层,我们已知其有个Paxos cache,大可以缓存50000个paxos消息(包括正在进行Paxos协议操作的消息和已经达成Paxos协议的消息,后者会通过回调函数返回MGR上层处理,同时其他未参与majority的节点也会请求获取这些已经达成Paxos协议的消息)。
```
/*
We require that the number of elements in the cache is big enough enough that
it is always possible to find instances that are not busy.
Under normal circumstances the number of busy instances will be
less than event_horizon, since the proposers only considers
instances which belong to the local node.
A node may start proposing no_ops for instances belonging
to other nodes, meaning that event_horizon * NSERVERS instances may be
involved. However, for the time being, proposing a no_op for an instance
will not mark it as busy. This may change in the future, so a safe upper
limit on the number of nodes marked as busy is event_horizon * NSERVERS.
*/
#define CACHED 50000
```
如果每个paxos消息的大小为1MB,那么整个cache可能会占用50G的内存空间,所以,在MySQL社区版中,对cache大小硬编码限制为1GB。(在我们InnoSQL中,支持通过参数group_replication_xcom_cache_size_limit动态调整cache的大小阈值。)
```
/* Reasonable initial cache limit */
#define CACHE_LIMIT 1000000000ULL
```
当cache大小超过阈值后,会调用shrink_cache()函数进行清理。
```
/*
Loop through the LRU (protected_lru) and deallocate objects until the size of
the cache is below the limit.
The freshly initialized objects are put into the probation_lru, so we can always start
scanning at the end of protected_lru.
lru_get will always look in probation_lru first.
*/
void shrink_cache()
{
FWD_ITER(&protected_lru, lru_machine,
if ( above_cache_limit() && can_deallocate(link_iter)) {
shrink_cache_count++;
last_removed_cache = link_iter->pax.synode;
hash_out(&link_iter->pax); /* Remove from hash table */
link_into(link_out(&link_iter->lru_link), &probation_lru); /* Put in probation lru */
init_pax_machine(&link_iter->pax, link_iter, null_synode);
} else {
return;
}
);
}
```
但从我们的测试情况看,MySQL社区版并不能对cache大小进行有效限制,极容易出现远超1GB的情况。这有两方面原因导致:
首先,在对cache进行收缩时,不仅仅需要判断cache大小是否超阈值above_cache_limit() ,还需要判断can_deallocate()的返回值,该函数会统计MGR各个节点Xcom/Paxos已经执行并返回给MGR上层的大消息序号msgno。只有序号小于msgno的消息才能被回收;
其次,我们再看看cache分配端的逻辑。
```
/*
Get a machine for (re)use.
The machines are statically allocated, and organized in two lists.
probation_lru is the free list.
protected_lru tracks the machines that are currently in the cache in
lest recently used order.
*/
static lru_machine *lru_get()
{
lru_machine * retval = NULL;
if (!link_empty(&probation_lru)) {
retval = (lru_machine * ) link_first(&probation_lru);
} else {
/* Find the first non-busy instance in the LRU */
FWD_ITER(&protected_lru, lru_machine,
if (!is_busy_machine(&link_iter->pax)) {
retval = link_iter;
/* Since this machine is in in the cache, we need to update
last_removed_cache */
last_removed_cache = retval->pax.synode;
break;
}
)
}
assert(retval && !is_busy_machine(&retval->pax));
return retval;
}
```
仅从lru_get()的函数说明就能发现,在从cache中获取一个Paxos消息时(该消息后续会加入需要进行propose/prepare的具体内容),不论当前cache大小是否超标,都优先从空闲队列probation_lru中获取消息,仅当probation_lru为空时才会从当前的LRU队列protected_lru中替换掉一个旧消息进行复用。
这就意味着,在大事务场景下,如果由于网络延时问题导致节点间出现较大的消息延时,那么cache的大小就可能突破阈值限制并无法快速收缩。对于在云主机这样内存极其有限的环境中运行的MGR集群来说,就更容易导致mysqld OOM。
**显然,这可能是导致我们在测试时出现内存持续升高的一个原因。针对这个问题,在我们的MySQL版本中进行了优化,在lru_get()中先判断当前cache大小是否已经超阈值,若已超,则跳过空闲队列probation_lru队列,直接从LRU队列protected_lru中获取消息。**
优化了cache大小问题后,我们进行了验证性测试。遗憾的是,虽然cache大小被控制住了,但mysqld的内存还是增长了不少。显然,除了paxos cache模块外,还有其他模块也在大量消耗内存。但这会是什么模块,什么代码逻辑的内存消耗呢?、
###### 问题定位插曲
讲到这里,不得不说下debian系统低版本导致的内存泄露。
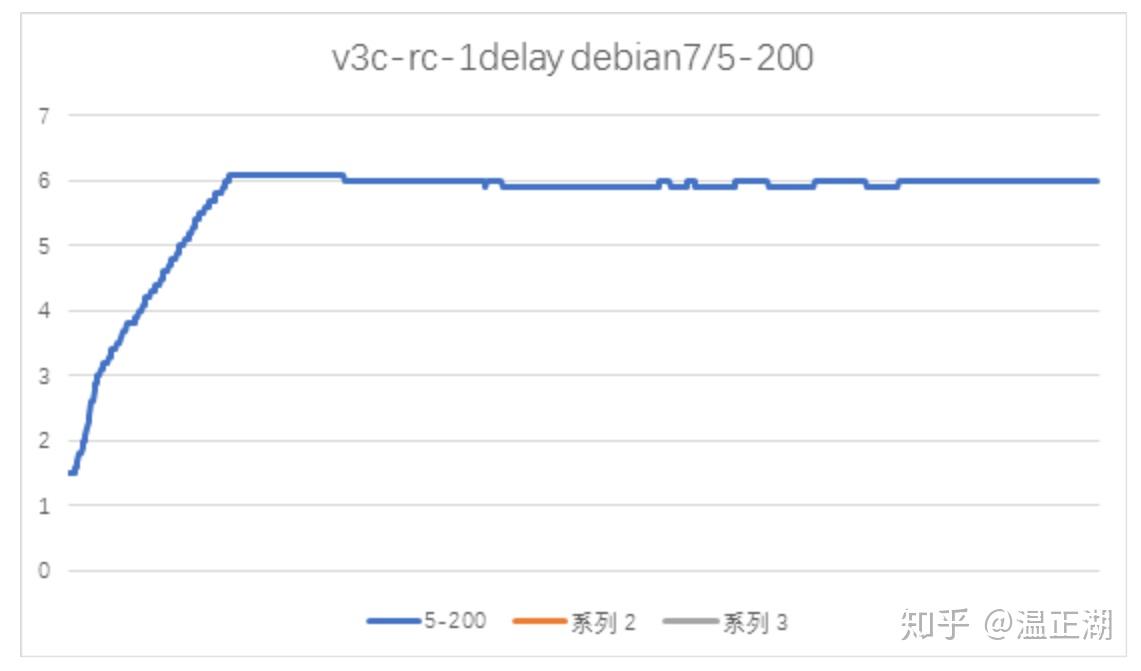
上图是在debian7上测试得到的mysqld内存曲线。对比debian9,可以发现mysqld内存在测试完成后并没有回落,且多次测试后,内存是不断增加的。看起来,在debian7上,该NDC导入场景下MGR存在内存泄露,该问题的定位花费了不少时间,在此略过不表,终定位发现这是由于debian7的XDR lib库导致的内存泄露,bug链接如下:
[memory leak when failing to parse XDR strings/arrays]
XDR是External Data Representation的简写,XDR允许把数据包装在独立于介质的结构中使得数据可以在异构的计算机系统中传输。XDR使用软件来完成变换,所以在不同的操作系统中可以灵活的运用。
MGR的paxos一致性协议的实现就用到了XDR库,该问题在debian9上得到修复。链接如下:
`https://debian.pkgs.org/9/debian-main-amd64/libtirpc1_0.2.5-1.2+deb9u1_amd64.deb.html`
##### Paxos网络通信逻辑
这个问题的发现和解决,让我们知道,测试过程中mysqld增涨的内存是跟Paxos的网络交互有关的。下面先简单介绍下MGR中使用的Paxos变种mencius是如何实现多节点可写的一致性协议的,详细内容可阅读:
“The king is dead, long live the king”: Our Paxos-based consensus
###### mencius/xcom协议简介
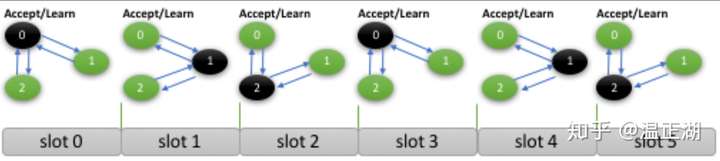
在mencius实现中,每个节点都可以是master节点,可以对某个轮次的消息进行propose操作。下图所示为3个节点组成的mencius组,节点的id分别为0、1和2。每个节点以round robin方式占有对应轮次的消息。如id为0的节点可以对slot 0、3、6、9等轮次的paxos消息propose某个value值,而id为1的节点可以对slot 1、4、7、10等轮次进行propose。
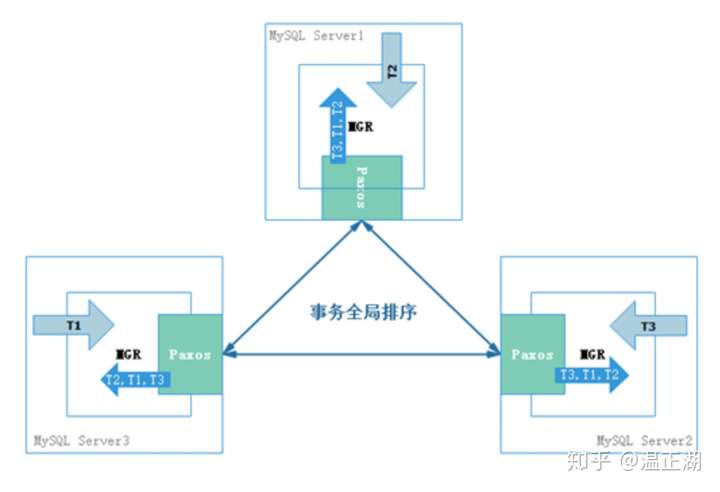
对应到MGR中,就是每个组成MGR的MySQL节点都可以执行事务。事务在提交阶段进入MGR,由mencius确定每个节点事务的执行/认证/回放顺序。对应在下图中,Server1(id 0)上的事务T2占有了slot 0,Server3(id 1)上的事务T1占有了slot 1,Server2(id 2)上的事务T3占有了slot 2。
在这样的机制下,如果每个节点的计算和IO资源相近,负载相似,那么整个MGR集群可以呈现好的性能表现。但一般情况下,MGR集群各节点的负载时不平衡的
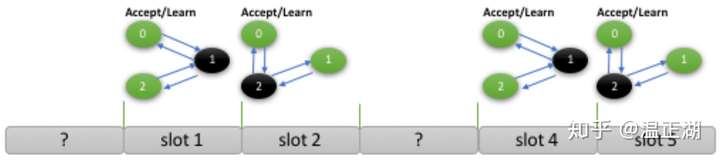
比如只有MySQL节点1和2持续有事务执行和提交,节点0仅回放已经达成majority的事务Binlog日志。这就意味着节点0仅有少数MGR内部产生的周期性地消息需要通过paxos达成majority,没有事务提交操作,在这种情况下节点0大部分轮次需要使用noop消息(表示该消息为空,不携带真实数据)跳过。
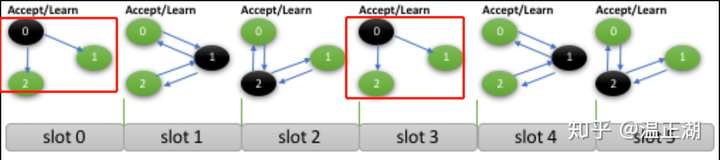
在上图中,节点0通过learn操作向集群广播noop消息,告诉大家跳过对应的slot 0和slot 3这两个轮次。
###### mencius/xcom协议实现
在MGR中Paxos协议是通过C/C++下的协程实现的,Paxos各操作由同一个线程下的不同协程来完成。如PREPARE/PROPOSE操作由proposer_task来完成,READ和EXECUTE操作是有executor_task来完成,ACCEPT和LEARN操作由acceptor_learner_task来完成。
下文会提到多个Paxos操作类型,在此先介绍下:Paxos协议全流程分为PREPARE操作、PROPOSE操作、ACCEPT操作、LEARN操作、READ操作和EXECUTE操作,前三个是Paxos协议达成majority的基本流程,但对于mencius,正常情况下不需要PREPARE操作,因为每个节点有自己的轮次,可以直接进行PROPOSE操作,只有在需要发起PROPOSE重试操作或者其他节点想要通过noop占用该消息轮次时才需要PREPARE操作;ACCEPT操作是其他节点对应PROPOSE操作的回复;LEARN操作是发起PROPOSE的节点向集群广播告诉大家某个消息轮次(序号msgno)已经达成majority,参与majority的节点可以执行EXECUTE操作了,没有参与majority的节点的acceptor_learner_task可以执行READ操作来获取了;某个节点在某个轮次没有收到LEARN操作提示,会认为自己没有参与到majority(可以是多种原因导致),executor_task会发送READ操作去其他节点获取。
在具体的代码实现中,如何知道某个消息轮次是要跳过呢?可以分为几种情况:
种情况:如果节点0发现比slot 0更大的轮次,比如slot 1或slot 2已经完成了majority,到了等待EXECUTE的阶段。那么节点0会发送slot 0的noop;(这种情况经分析不会引发问题,在此简单带过)
第二种情况:由于每个节点都需要按序向MGR上层返回达成majority的消息,所以会等待slot 0达成majority。executor_task先尝试READ操作从其他节点获取slot 0的消息。如果重试多次后仍无法获取,则会发起PREPARE操作。该操作主要是防止节点0网络延迟较大或者网络分区导致阻塞其他Paxos节点从而影响整体性能。
对于MGR单主模式,第二种情况更为普遍,executor_task获取消息的核心代码如下:
```
static void find_value(site_def const *site, unsigned int *wait, int n)
{
DBGOHK(FN; NDBG(*wait, d));
if(get_nodeno(site) == VOID_NODE_NO){
read_missing_values(n);
return;
}
switch (*wait) {
case 0:
case 1:
read_missing_values(n);
(*wait)++;
break;
case 2:
if (iamthegreatest(site))
propose_missing_values(n);
else
read_missing_values(n);
(*wait)++;
break;
case 3:
propose_missing_values(n);
break;
default:
break;
}
}
```
在find_value()函数中,*wait表示重试获取某个消息的次数。0表示次。n表示同时获取多少个消息。可以发现,头两次获取某个消息时,调用的是read_miss_values(),第三次时,如果本节点id是所有节点中小的(leader节点),则采用propose_missing_values()的方式。从第四次开始,所有节点都采用propose_missing_values()方式。从函数名就可以发现,前者通过发送READ操作以round robin方式从其他节点读取对应消息。后者是通过向所有节点发送PROPOSE操作(需要先PREPARE)来尝试跳过该轮次消息。
每次调用find_value()进行重试的时间间隔由函数wakeup_delay():
```
static double wakeup_delay(double old)
{
double retval = 0.0;
if (0.0 == old) {
double m = median_time();
if (m == 0.0 || m > 0.3)
m = 0.1;
retval = 0.1 + 5.0 * m + m * my_drand48();
} else {
retval = old * 1.4142136; /* Exponential backoff */
}
while (retval > 3.0)
retval /= 1.31415926;
/* DBGOUT(FN; NDBG(retval,d)); */
return retval;
}
```
wakeup_delay()会根据上一次重试前等待时间计算出本次需要等待多久才重试获取该消息。下面是我们添加debug日志打印出的函数输入和返回值。
```
2019-05-15T17:44:47.118532+08:00 0 [Note] Plugin group_replication reported: 'wakeup_delay old 0.000000 new 0.102819'
2019-05-15T17:44:47.220782+08:00 0 [Note] Plugin group_replication reported: 'wakeup_delay old 0.102819 new 0.145408'
2019-05-15T17:44:47.366054+08:00 0 [Note] Plugin group_replication reported: 'wakeup_delay old 0.145408 new 0.205638'
2019-05-15T17:44:47.571343+08:00 0 [Note] Plugin group_replication reported: 'wakeup_delay old 0.205638 new 0.290817'
2019-05-15T17:44:47.861715+08:00 0 [Note] Plugin group_replication reported: 'wakeup_delay old 0.290817 new 0.411277'
```
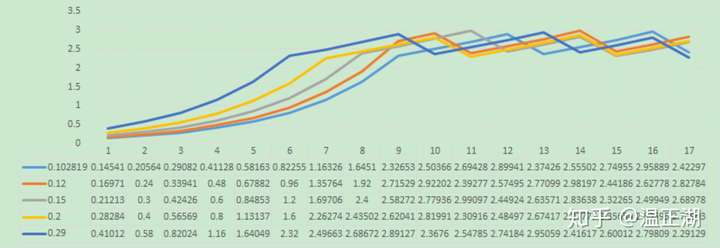
基于该函数,我们不同的初始值描绘出增长曲线,可以发现经过不同次数增长到3.0,达到3.0之后,在约2.3~3.0之前来回摆动。根据我们的观察,wakeup_delay随机产生的初始值基本上都略大于0.1。

###### executor_task实现的缺陷
通过上述代码分析和实验很容易发现,当前的MGR/Paxos实现代码会在1s之内发起4~5次获取指定msgno消息的尝试。而从第3次开始,Paxos集群的leader节点会开始进行该消息PREPARE操作(跳过本节点的轮次),从第4次开始,Paxos集群中所有节点都会进行PREPARE操作。也就是在1s之内,executor_task就会从普通的READ操作变为激进的PREPARE操作。整个过程有至少有2点危害。
**网络和内存开销成倍放大**
在过短的时间内进行多次READ操作,虽然READ本身网络开销很小,但是所需读取的轮次消息中的事务(或事务batch)可能很大,比如上述案例中的30MB,假设每次获取10个,那么1s之内多可能会请求约1GB的数据量,也就是说其他节点回复该READ消息时需要通过网络传输这么多数据量。在3节点MGR中,会有1个节点出现该行为,1GB数据量分摊给另外2个节点,每个节点也需要500MB的网络带宽开销。而网络开销也意味着内存开销,因为在其他节点回复READ操作时,需要拷贝一份数据,copy_app_data()即为数据拷贝函数:
```
/* Handle incoming read */
static void handle_read(site_def const *site, pax_machine *p,
linkage *reply_queue, pax_msg *pm) {
if (finished(p)) { /* We have learned a value */
teach_ignorant_node(site, p, pm, pm->synode, reply_queue);
}
}
static void teach_ignorant_node(site_def const *site, pax_machine *p,
pax_msg *pm, synode_no synode,
linkage *reply_queue) {
CREATE_REPLY(pm);
reply->synode = synode;
reply->proposal = p->learner.msg->proposal;
reply->msg_type = p->learner.msg->msg_type;
copy_app_data(&reply->a, p->learner.msg->a);
set_learn_type(reply);
/* set_unique_id(reply, p->learner.msg->unique_id); */
SEND_REPLY;
}
```
到这里,还有个疑问:从下图各节点的内存变化曲线看,只有Master/Primary节点内存升高。2个Slave节点内存均较为平稳。按照我们刚刚的分析,假定Slave2是不参与majority的节点,那么Slave2会采用round robin的方式向Slave1和Primary节点发送READ操作。为何Slave1的内存不见增涨呢?
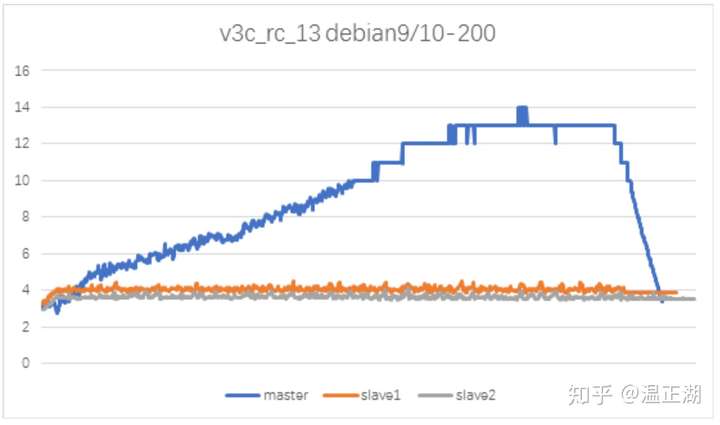
原因是Primary和Slave1的网络流量不均。对于一个消息,Primary需要在PROPOSE阶段将完整的消息发送给所有节点,包括Primary节点自身;还需将达成majority的消息结果再广播给每个节点(MGR在LEARN时做了优化,LEARN操作不会携带消息中的事务数据,如果接收到消息的节点未参与majority,就会发送READ操作)。而Slave1只需要向Primary回复ACCEPT消息(不带事务数据)。Primary相比Slave1有数倍的性能和网络开销,更容易由于网络瓶颈导致网络消息包堆积,进而占据过多的内存空间。
**过早PREPARE降低PROPOSE效率**
由于第4次开始为PREPARE,假设由于事务较大或网络性能较差,一个携带事务数据的Paxos消息从PROPOSE操作到LEARN操作的时间需超过1s,假设Primary节点上的事务A已经基于msgno1进行PROPOSE操作,消息还未成功发给任意Secondary/Slave节点,在目前的executor_task代码实现下Secondary节点可能会发起PREPARE操作,由于PREPARE和后续空的PROPOSE操作消息都很小,传输效率高于事务A,那么2个Secondary节点会先于事务A在msgno1轮次对noop消息达成majority,事务A不得不重新基于下一个轮次的msgno2来重新进行PROPOSE操作。这实际上减低了PROPOSE操作的效率,增大了网络开销。对应代码如下:
```
if (match_my_msg(ep->p->learner.msg, ep->client_msg->p)){
break;
} else {
G_MESSAGE("proposer_task retry new case 3(not match) msg (%lu, %d)",
ep->msgno.msgno, ep->msgno.node);
prepare_retry_count++;
GOTO(retry_new);
}
```
proposer_task在发起PROPOSE操作后,会等待该msgno的消息完成Paxos协议流程,然后判断该消息携带的事务数据是否为其自己的。若不是,就需要就行重试。
###### proposer_task的实现逻辑
下面再看看消息proposer端的逻辑(抽取了核心部分):
```
if (threephase || ep->p->force_delivery) {
push_msg_3p(ep->site, ep->p, ep->prepare_msg, ep->msgno, normal);
} else {
push_msg_2p(ep->site, ep->p);
}
ep->start_push = task_now();
while (!finished(ep->p)) { /* Try to get a value accepted */
/* We will wake up periodically, and whenever a message arrives */
TIMED_TASK_WAIT(&ep->p->rv, ep->delay = wakeup_delay(ep->delay));
if (finished(ep->p)) break;
{
double now = task_now();
if ((ep->start_push + ep->delay) <= now) {
push_msg_3p(ep->site, ep->p, ep->prepare_msg, ep->msgno, normal);
ep->start_push = now;
}
}
}
```
可以发现,proposer_task在调用push_msg_2p()进行PROPOSE操作后,会转入等待该消息完成。若未完成则进入睡眠状态,唤醒后发现该消息还未完成,则会调用push_msg_3p()使用相同的msgno对消息进行PREPARE操作。循环如此,直到对应msgno完成。而睡眠唤醒后进行PREPARE重试的时间间隔也是由前述的wakeup_delay()返回值决定的,这同样意味着,完成一个消息的Paxos流程较慢的话,会进行多次重试,如果每次都携带对应的事务数据,那么也会导致严重的网络带宽开销。(不过针对这点,MGR的paxos实现本身已优化,在PREPARE操作时不携带事务数据。)
##### 代码优化和验证
基于上述分析,我们找到了3个可能导致网络性能退化和内存增涨的问题。其中一个是由于Paxos cache大小未严格限制导致;另外两个问题均出现在Paxos消息的获取环节executor_task代码逻辑上,分别是在短时间内频繁发送READ操作,以及PREPARE消息中断了proposer节点proposer_task正在执行的PROPOSE操作。
这些原因会导致网络情况急剧恶化,内存不受控得增涨,并出现前述提及的mysqld异常日志:
周期性广播消息紊乱:由于Primary节点存在较大网络延时,导致该节点的周期性广播消息无法像其他节点那样按时发送,此外,该广播消息对应的轮次在发送的过程中也可能给其他节点使用noop抢占掉。这也会导致消息无法按时发送。
无法获取Paxos cache消息:Primary节点无法快速回复Secondary节点的READ操作,导致Secondary节点与Primary节点的Paxos消息延迟增大,终由于Primary上对应的Paxos消息从cache中被替换导致Secondary无法通过READ操作获取。
针对上述发现的问题,结合网易实际场景进行针对性优化
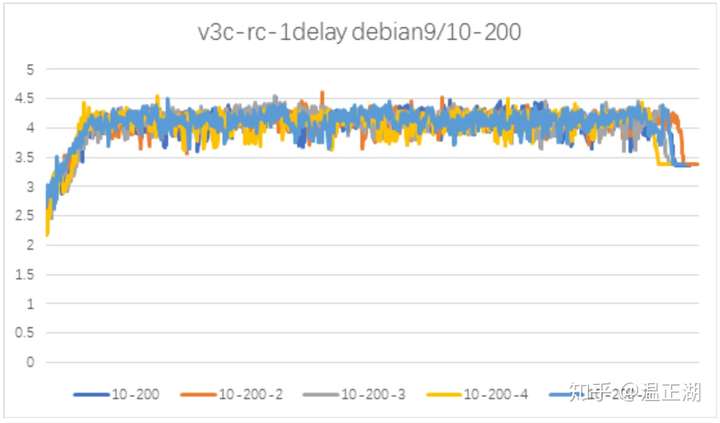
上图所示为基于该优化进行验证性测试结果,发现在事务执行性能没有退化的情况下,内存增涨情况得到了有效遏制。
