HDFS简介
- 机架内部通过高速光纤交换机联结
- 主节点:数据目录
- 从节点:数据存储
- 实现目标:1)廉价设备 2)实现流数据读写、批量数据 3)支持大数据集 4)简单的文件模型、只允许追加数据,不允许修改 5)跨平台,java语言开发
- 局限性:1)不适合低延迟数据访问 (HBase可以)2)无法高效储存大量小文件 3)不允许多用户修改
HDFS相关概念
- 块设计:128MB
- 块设计的好处:①支持大规模文件存储,突破单机存储上限 ②简化系统设计 ③适合数据备份:重要特性,对数据的冗余备份
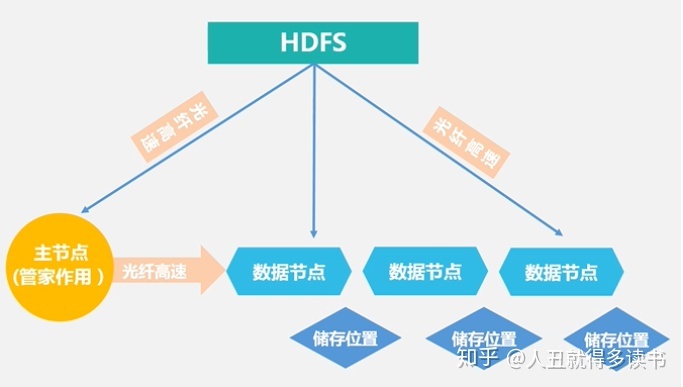
- 名称节点:数据目录--->文件是什么、文件被分为多少块、每个块和文件是怎么映射的、每块存储在哪个服务器上
# 通过nn和dn在运行中不断沟通
# shell命令启动
# 第二名称节点:名称节点的冷备份、缓解editlog的不断增大- 数据节点:存储在本地linux系统中
HDFS体系结构
- 主从结构
- 命名空间管理
# 通信协议:TCP/IP RPC 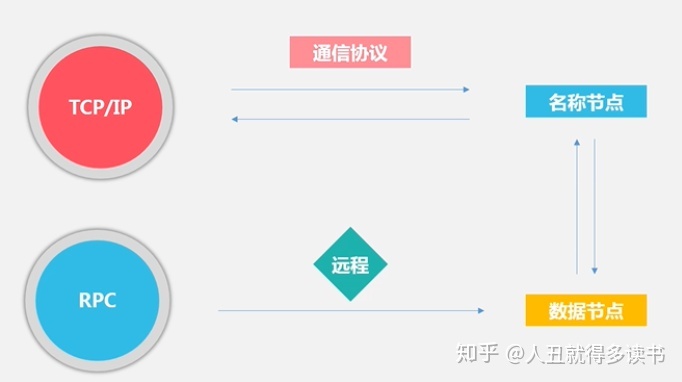
- 命名空间局限性:
# 命名空间限制:名称节点是保存在内存中的,名称节点所能容纳的对象会受到空间大小限制
# 性能瓶颈:也受到单点吞吐量的影响
# 隔离问题
# 集群的可用性:发生故障会导致整个集群不可用HDFS存储原理
- 数据冗余保存优点
# 加快数据传输速度,并行操作
# 容易检查数据错误
# 保证数据可靠性,系统探测到故障,自动恢复- 如何存储
对于一个块block,同时生成3个副本。如果是集群内部服务器节点上传,则将副本1直接上传至该服务器;如果是集群外部上传,则将副本1随机上传至一台磁盘不太慢、CPU不太忙的节点。副本2要放到和个副本不同的机架上面。 副本3放到和副本1相同机架的不同节点上。副本4,5,6...随机放到集群内各个节点上。
- 数据读取
就近读取。网络开销小。HDFS提供了一个API可以确定一个数据节点所属的机架ID,客户端可以调用API获取自己所属于的机架ID。优先去找数据块副本对应的机架ID和客户端对应的机架ID相同的副本,同一个机架内部网络开销少,带宽高。如果没有发现,就随机读取。
数据的错误与恢复
- 名称节点出错
名称节点保存FsImage和Editlog两个核心数据结构,平常使用的时候会进行冷备份。
- 数据节点出错
# 数据节点定期向Namenode发送心跳信息
# 一个数据周期 nn收不到心跳信息 证明该节点发生了故障 此时在nn的数据节点列表中将该故障节点标记为宕机
# 然后把存储在故障机上面的数据 复制存储到别的机器上面
# 另外,负载发生不均衡时,也会调整冗余副本的位置
----数据出现错误----
# 数据存储成数据块时,会产生校验码
# 再次读取时,校验码出错的情况即产生了数据错误HDFS读写原理
- 读数据过程

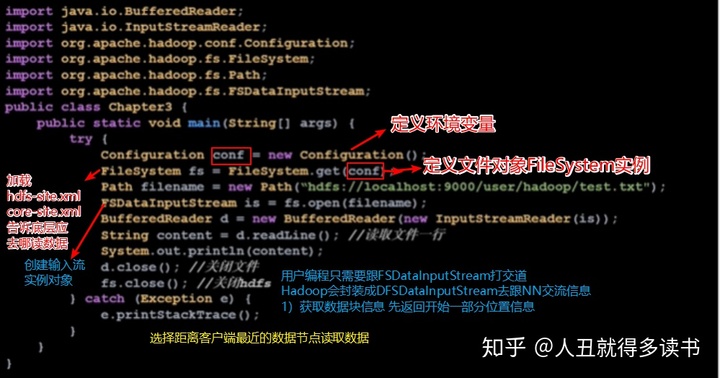
对于较大的文件,HDFS读完一部分数据时,通过ClientProtocal.getBlockLocation()询问寻找下一个数据块的位置。

FileSystem的通用文件系统抽象基类,可以继承FileSystem实现很多具体子类,如FSDataOutputStream和FSDataInputStream等

- 样例代码解析
---20200301更新
