作者 | imgaara
微信公众号 | 神夜月光
题图 | 新买两个键盘,有一个可以给娃当玩具拍拍,加一起我就有5把类似这样的键盘了
连接 | 从HashMap的rehash到分布式KV数据库
有一天,某个群里的Google大神提出一个问题:
来讨论一个问题,如何设计一个可以像STL std::vector 一样自动扩容的hashtable?如何做到在扩容的时候操作速度也不会明显变慢?
我们各种就讨论起来了。对于这个问题我还是略熟悉的,张口就说了Redis的方案。当然其他同学也各自提出了自己的想法。然后我突然意识到这个是一个很好的可扩展议题,所以就写成这一篇,供大家思考和讨论。
谈论的是HashMap(hashtable),所以基本上增删改查的时间效率都应该是O(1)。而TreeMap暂时不在讨论的范围中,因为树形结构天生就是易于做添加,所以没有rehash这样的问题存在。
另外一个是,我们先考虑它只是一个普通的数据结构,并不是一个小运行系统。也就是说先不考虑有多线程支撑,也暂时不包含内部的背景线程的情况,先从简单的结构搞起。
内存中的HashMap一般都是连续内存。
一般扩容的方法都是地址空间加倍,然后在rehash的时候拷贝数据。
这个在小内存中是没有太大问题的。但是在大内存的时候,rehash中重新拷贝数据地址的成本还是很高的。当占用的内存(比如64G以上)的时候,rehash的停顿时间是完全无法忽略的。而这一时间的停顿可能造成服务的短时间不可用,更严重的会造成整个系统的雪崩。
那么我们应该如何来做呢?其实多想了像,rehash可以认为在单机上rehash,可以认为是在local system 上rehash,也可以认为在一个分布式环境下rehash。
那么都有些什么方法呢?仔细整理了一下记忆,其实还有不少可以说的。
渐进式rehash
这个是Redis使用的方案。
顾名思义,rehash的过程不是一次做完,而是慢慢做。这个过程的驱动源是各种增删改查的请求,每来一次请求,则rehash一个已经存在的KV。
h[0] 为原hash表,当h[0]在装载数据到一定程度的时候触发扩容和rehash过程。
有人说会问,如果没有请求了怎么办?
- 可以设计一个定时触发源。这个定时触发源发送一个NO_OP_REHASH的请求到你的HashMap上,HashMap提供maybeRehash()的方法,系统接收到NO_OP_REHASH的请求类型时,则触发一次rehash。
还有人会问,如果请求太快了,还没有rehash完就又要扩容了怎么办?
这是一个trade-off的问题,个人认为没有完美的方案:
- 加速rehash过程:一次可以rehash多个数据,一次bulk的大小可以通过配置定义,也可以通过当前的系统性能动态调整。
- STW(Stop The World):可以直接进入等待状态,让rehash过程走完再做下面的事情。
- 如果是还有比较充足的空间:可以生成h[2], h[3]等,rehash的过程我认为可以类似。但是也是要有限制,这一招只能用来对付一时的快速增长。并且也要设置一个上限,超过上限,依然要STW。
前缀匹配分区
这是群里另外一个百度的大神的想法,主要还是分治思想。我沿着思路继续想了想,觉得也能做。
前面说的都是一整块内存作为hash表。整块的数据是比较大,rehash的重定位会比较慢。那么如果我的hash表不是连续的,是分层的呢?
一般设计为两层。层根据前缀匹配找到对应的SubTable。
然后再到SubTable里面进行hash查找。
以下是一个示意图:

首先认为key是均匀分布的。如果不是均匀分布,请考虑添加一个SaltPrefix到你的key里面,再来存储到HashMap里面来。
每个前缀开辟新的SubTable,可以定死前缀所占Bit的长度。
但是每个前缀后面的table可以从比较小的size生长起来。每个SubTable大小可以单独变化。每个SubTable可以单独生长。
由于key已经是均分分布了,则不会有特殊的情况导致某些table特别大。所以每个SubTable都是比较小的,可以通过一次处理把一个SubTable下所有的key全部rehash一遍,并且这样的耗时不会太长。
如果某个SubTable在比较大的情况下,则需要退化到单个大的Table处理的情况了。但是从整体上来看,总体rehash的停顿时间是比较小的。
一种节省move的操作方法
参考美团的这篇文章:https://tech.meituan.com/java_hashmap.html
一般,每个SubTable在扩容的时候,需要重新计算每个Key的slot index。
如果每次扩容时2倍扩容的时候(table的size始终得是2的次方),可以取个巧使得rehash的过程变得稍微快一点:
- 同样是取模,但是需要修改为后缀计算,而不是前缀
- 对每个key,计算SurfixBit的前一位
- 如果是0,则数据的index不变
- 如果是1,则数据的index=之前的index + 原table的size
- 这样所有的数据就会在新的table中分散开来。而且slot的计算是准确的。
- 要正确计算bit,就需要正确的计算BitMask
- 01的分布,如果数据的hash做得好,也是可以让数据均匀分布到新的SubTable上的,这样可以降低冲突概率
多阶hash列表
这个方法是我在腾讯的时候用到过的。在腾讯,是大量使用这种表,解决高并发的访问问题。如果不出意外的话,我认为直到现今,这个方法还大量在使用中。并且一些Java程序在DirectMemory使用的基础下,在使用这样的结构(好处读者可以思考以下)
hash需要解决冲突的问题。当发生冲突,一般有Open Link法(俗称开链),Open RBTree法(我叫:开树法,开链的变种),或者Open Address法(俗称开放地址)。
但是前人开发出了一种更有效的开放地址方法:多阶再hash法。(其实也可以叫做开Hash法

)
提供一个二维数组(或者是N个hash链到一个hash list里面),每一层数组的大容量是一个质数,然后每一层质数都要比上一层小。
(为什么,专家证明过,这个存储效率高,冲突率小,应该有论文,有兴趣可以自己去找找。)
结构大概如下:

我只是粗略的介绍一下这个结构,有兴趣的可以详细看下面两个链接,它们会告诉你这是个什么玩意,它的性能如何:
https://www.cnblogs.com/glacierh/p/5689418.html
分布式存储系统设计(3)-- 存储结构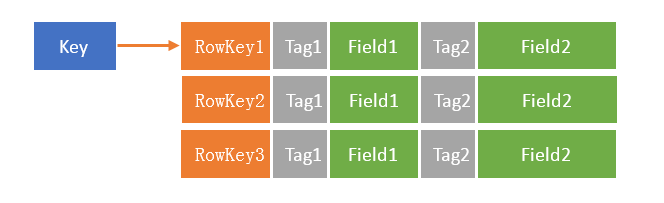
https://www.cnblogs.com/glacierh/p/5689418.html
http://www.codinginet.com/articles/view/201512-high_performance_hash_table?simple=1
主要不是介绍这个结构,我只是说,这个方法也间接的把一个大的HashMap拆成了一个二维结构,那么每一个hash的表都不是那么的大,每个小表都可以独立的进行rehash扩容。而rehash也可以考虑为一次rehash完,或者渐进式rehash。
一种高性能多阶哈希表实现
主要不是介绍这个结构,我只是说,这个方法也间接的把一个大的HashMap拆成了一个二维结构,那么每一个hash的表都不是那么的大,每个小表都可以独立的进行rehash扩容。而rehash也可以考虑为一次rehash完,或者渐进式rehash。
个人觉得这种扩容方式有两种方向,一个是横向,一个是纵向。
-
横向:
从高阶往上扫描,找到个填充因子偏高的子表,进行扩容。
但是需要注意一个问题,每个子表的生长速度可能不一样,也可能一样。并且在向下一阶溢出的时候,需要考虑什么时候要把当前这一层扩容,或者是优先把下一阶扩容,都需要重新权衡。
-
纵向:
从高阶往下扫描,当每一层的填充引子都大于某个值的时候,则动态加入新一阶子表。这个过程应该也有一个上限,一般阶数不超过100层。所以整个内存增长的容量规划需要好好考虑。不然平均访问阶数变高,性能下降不少。
像上面引用的第二篇文章,就介绍一种大小变化方式,使得数据尽量集中在低阶的表上,这样的平均查询速度会更快。不过这样的话,写的时候也会遭遇问题,需要根据读写需求具体场景具体分析。
LSMTree - In Memory Compaction
我们现在放宽条件。
如果,它不是一个单一的数据结构,而是允许有背景线程处理的话,我们是否还有其他的办法?
这个思路来源于LSMTree(leveldb,rocksdb,HBase等等是这个的一种实现),只是将磁盘的文件的操作全部在内存当中来做罢了。
实际上这个方法也已经有了,在HBase 2.0当中已经引入了In Memory Compaction,通过内存的合并减少写放大,加快读。
一篇介绍的文章,有兴趣的话可以在后面在展开阅读以下:
https://blogs.apache.org/hbase/entry/accordion-hbase-breathes-with-in
写的时候,永远只写到一个MutableMemTable。
如果超过一定大小,则“snapshot”为一个Immutable的MemTable,依次标号0,1,2,…… 每个MemTable都有附属的生成时间(或者版本号吧)。
读的时候,按照时间或者版本先后顺序(这里可能会比较复杂,需要对MemTable的时间顺序有了解,并且MemTable之间的时间顺序是不应该有交叠的,如果时间是交叠的怎么做我暂时还没想清楚),检查每个MemTable,如果有数据可以直接返回。
我们可以看到,写是非常快的。但是读就比较慢了,每次要读所有的MemTable(如果不命中的话)。所以为了加速读,需要对MemTable进行合并(Compaction),或者还需要BloomFilter。
可以设定一些阈值:ImmutableMemTable的个数。
当个数超过限度后,背景线程开始运作,慢慢合并小的MemTable为一个整体。整个过程也是可以是渐进式的。由于合并的都是Immutable的数据,整个过程没有一致性问题。合并完成之后,丢弃老的MemTable即可。
并且合并的时候也可以采取一些策略,每次选择某一部分的MemTable进行合并。保证每次合并的资源消耗不是太大(Minor Compaction)。
也可以为了保证更高的读性能,定时的或者人为的触发对所有ImmutableMemTable的合并(Major Compaction)。
以上这些均和HBase的设计一致,由于只需要支持快速的hash查找,不需要支持顺序查找,只是使用的ConcurrentHashMap,并不是SkipListMap(Java的ConcurrentSkipListMap),所以整个写入读取效率仍然可以视为O(1)。
本地数据存储
数据不再完全分布到内存中了。而是要扩展到系统文件中,并且每个Value的Size还可能比较大。
上述的方法我认为是仍然适用的。因为数据分配,数据寻址,数据重新rehash的过程是一样的。
有几种可以考虑的方案:
- LSMTree (参考rocksdb,badgar中,HashIndex部分的实现)
- B+Tree,Fractal Tree(这个实际打破了O(1)查找的,成为了O(K*N),K是树的高度,N是每个节点包含数据的个数)
- Hash Fractal Tree(自创,个人认为可以做成Fractal Tree那样,但是性能已经不是O(1),而是O(K), K是树的高度)
只是作为整个系统需要考虑IO的问题(特别是在普通磁盘的情况下hash查找是比较慢的):
- 直接大块文件的方法肯定是不可取的了,即使是用这个方法也要做内部数据的仔细切分。
- 分块存储,有一级索引,二级索引成为了必须(前缀匹配方法,两层地址查找)
- 或者干脆做成一个树形结构,Hash Tree方法。通过前缀hash
- 数据地址映射区,和数据区域需要分离
- 对于数据做Cache,对于索引区和数据区域需要分别做缓存,并且索引区域应该常驻内存
- 当然对写入更优化的方法,还是采取LSMTree的方法
有一种想法,可以类似Hash Tree,或者Hash List,或者B+Tree:
- 设计一种分层按照Hash来导航的树形结构,树限制一定的大高度
- 每一层包含的字节点数目不超过K(可以设计总空间N,K=N*loadFactor),每一层独立建立hash空间
- 分裂的时即是rehash的时候(或者还有合并操作),因为每个节点并不大,rehash的时候一次完成即可。
- 如果节点数目超过K,则分裂为两个hash表,每个表大小还是N
- 但是由于是hash数据分散写到各个文件,并不适合普通Hard Disk,只能适合SSD。而且每个节点都需要带上各自的buffer,合并写入才会提高效率。同样读取的时候也需要带上buffer。(这里就会比较像分型树/Fractal Tree,请参考TokuDB,但是它只是一个hash版本)

这样做的时候,表热点的部分会裂变出很多表出来,导致Tree的层数变高,读和写的性能都会下降。如何平衡的话,和Fractal Tree一样,感觉会是一个比较艰深的话题。
无论是LSMTree模式,还是Tractal Tree模式,还是我说的这一种,都是有内存数据的,需要WAL来进行崩溃恢复。
不过外来的存储方案都是在进步的,个人觉得3~5年之内,AEP(Inter Apache Pass,一种Persistent Memory)的普及,会让WAL消失,以后的design就可以不用考虑WAL,而设计的更细致灵活了。
到这里,关于单机Map的话题就结束了。现在我们来把这个话题拓展到一个集群。
分布式数据库又如何?
我们就是这样奇怪的创造者,创建了一个又一个庞大的怪物应用。使得我们需要不定期的追加机器,去扩容,去再平衡我们的数据。
当然也缔造了在这个上面生根发芽的怪物用户,他们会创造很多关联(加好友,发文章,转发,你都可以认为是发生了关联)。
怪物用户的数据往往造成了极大的存储消耗,无法对这些数据就行良好的分布的话,你总会发现某些机器,或者某些存储单元(比如HBase里面,这个该鸟叫做Region,或者是Store)容易被撑爆。
所以,这时你的这个Map不会光在一台机器上了,可能在一个Cluster上。
整个Cluster形成了一个巨大的Map。这个时候如果这个Map是个HashMap(可以想象,它是一个Redis集群),那这个rehash的扩容问题怎么解决呢?我们还能保证全局都是O (1)的效率访问到数据么?
整体比较简单,其实如果不考虑一致性问题,高可用性,方案都是比较固定而且是明显的。分层解决问题,划分总是解决分布式下scalability问题的一剂良药。由于每个节点hash的rehash和扩容问题都已经有解决方案。剩下的是需要解决请求对于数据在哪个节点的定位问题。
先说结论:
- 从实用的小规模来说,有O(1)时间效率的方案。稍微浪费点空间
- 更大规模的,还是只能采取O(lg(aK))的方案。K是节点数目,a是一个常数,后面说。且K肯定是远小于整个数据量的大小的。
- 还有一个方案,是固定路由方案,也是O(lg(R))方案。R是Key的空间切分数目,或者也是partition数目。
保证O(1)的方案:
方案的关键在2倍扩容。
而具体如何路由,可以用hash表,可以用数组取模,都不是问题。
- 其实我原来在腾讯,有时就会用简单的方案,就是取模,简单有效。
- 比如Kafka,就会默认用Murmur Hash的partition方法,把数据固定的打到固定partition。虽然Kafka不是数据库,但是它也可以在某种意义上被视为流式存储。可别忘了我刚讲过Kafka Streams的一些东西,Kafka Streams附带Local State Store开启Queryable Interface RPC的时候,那就是一个分布式数据库。
数组的二倍扩容就好说了。二倍扩容的数据不是在前半的老节点上,就是会在新加的一半节点上。所以Mod 2N不会使路由错乱。
Hash的rehash问题我上面已经说了。所以也不是问题。
只是在移动数据的时候,也可以采取渐进式rehash(migrate),或者是一次性完成migrate后再对接新的流量。
另外一个问题就是,由于这种路由是不能容错的。所以一旦节点down机,这个partiton的数据要么是不可用状态,要么需要有Replicate Follower。当然如何做Replicate 保证高可用和一致性,是另外的问题,这回不涉及。
一致性hash方案
这个就是O(log(aK))的方案。
具体做法和基础结构和方法我这里不展开,也比较简单,可以参考下面的链接。
https://zhuanlan.zhihu.com/p/24440059
而在今天的主题上,我们聊点其他的。
为什么是叫一致性hash,它跟普通的hash方法或者取模方案的区别,就是解决了两个问题:
- 实现了N+1扩容,避免了2倍扩容消耗
- 在N+1扩容的同时,保证了数据分布的均匀性,也保证了极少量的数据发生迁移。
这个方案的本质是:以邻为壑
一旦发生节点退出,邻居就要肩负起它的责任。所以默认的实现是有缺陷的,如果节点的load已经超过本身负载上限的50%,则会发生雪崩。
为了防止雪崩,引入了虚拟节点的概念,使得数据空间被随机打的更散。一台机器有a个虚拟空间,所以一台机器的邻居在概率上就变成了a个。
这个a就是那个公式的a,所以本质成为了顺序空间的索引定位问题。它的下限是lgK。但是虚拟节点个数是aK个,那么整体性能就是O(lg(aK))
所以问题就来了,a一般取200个,越多数据空间可以打的约散。K如果大集群下,可以有几千台或者几万台服务器。如果是3000台机器,每次查找次数就大概是20次,并且这个虚拟节点内存的消耗随之会增长也是一个问题,如果节点频繁的进入退出(p2p网络),会造成巨大的消耗。
默认的有名的实现是Ketama算法,是割环算法的一个标准实现,也比较简单。
除了默认的割环算法,还有几个算法可以参考一下,具体我就不展开了,有兴趣可以多了解一下:
- rendezvous hashing: 解决了访问热点的问题。
-
jump hash:来自谷歌研发的算法,可以参考下面的论文链接。几乎0内存消耗,logK的效率解决了(可以认为a=1),数据分布均匀,也热点问题也解决的很好。
参考:
https://en.wikipedia.org/wiki/Rendezvous_hashing
https://colobu.com/2016/03/22/jump-consistent-hash
http://arxiv.org/ftp/arxiv/papers/1406/1406.2294.pdf
固定路由方案
这个方案也叫做空间预分配方案。也是比较多的分布式数据库会使用的方案,如:MongoDB,HBase,Redis 3.0,以及类HBase的其他分布式数据库等等。
和一致性hash一样,是有一个KeySpace的。
一致性hash的KeySpace是0~2^64-1,是整数值域。
但是固定路由的话,KeySpace则不一定。它可以是任意数据的分布空间,所以一般定义的KeySpace=bytes[Start, End]。预分配,则会先创建R个partition(或者叫shard,region,range,都可以)。partition=bytes[Start, End]。
partition分为R个左闭右开区间,将整个KeySpace完整切分。然后R个区间映射到K台机器上。在R个区间里面定位也是O(logR)的性能。从R定位机器是O(1)。
所以这也是一个两层切分的思路。但是两层之间的映射是灵活的,为数据的迁移,HA,以及负载均衡提供了基础,并且可以在上面施加不同灵活程度的控制算法。
partition的分裂,或者partition的迁移,就可以视为一个片段的rehash过程。不过注意的问题不一样:
- 分裂的点在bytes[Start, End]中的选择。需要避开热点问题。一般Start,End都会只用一个KeyPrefix。如果某些数据过于集中(怪物用户)存在,则这个中点的分裂需要考虑增大KeyPrefix长度。不然分裂会失败,热点无法完好消除。
- 分裂之后,partition的迁移,有时候需要根据每个partiton的size分布来决定,有时候需要根据当前访问的load决定。这涉及到一些均衡算法。如何选取是一个权衡过程。这里也不展开了,后面后机会再介绍一下。
到此,大概讲了讲如何做一个可以灵活扩容的Map了,而且这个Map可以做的很大:)
希望会对你有点启发。也欢迎来知乎上讨论。知乎搜索:imgaara 可以找到我。
谢谢你读到这里!

