жқҘжәҗпјҡж°ҙжһңжіЎи…ҫзүҮ
й“ҫжҺҘпјҡhttp://blog.jobbole.com/55086/
еҫҲеӨҡзЁӢеәҸе‘ҳи§Ҷ SQL дёәжҙӘж°ҙзҢӣе…ҪгҖӮSQL жҳҜдёҖз§Қдёәж•°дёҚеӨҡзҡ„еЈ°жҳҺжҖ§иҜӯиЁҖпјҢе®ғзҡ„иҝҗиЎҢж–№ејҸе®Ңе…ЁдёҚеҗҢдәҺжҲ‘们жүҖзҶҹзҹҘзҡ„е‘Ҫд»ӨиЎҢиҜӯиЁҖгҖҒйқўеҗ‘еҜ№иұЎзҡ„зЁӢеәҸиҜӯиЁҖгҖҒз”ҡиҮіжҳҜеҮҪж•°иҜӯиЁҖпјҲе°Ҫз®Ўжңүдәӣдәәи®Өдёә SQL иҜӯиЁҖд№ҹжҳҜдёҖз§ҚеҮҪж•°ејҸиҜӯиЁҖпјүгҖӮ
жҲ‘们жҜҸеӨ©йғҪеңЁеҶҷ SQL 并且еә”з”ЁеңЁејҖжәҗиҪҜ件 jOOQ дёӯгҖӮдәҺжҳҜжҲ‘жғіжҠҠ SQL д№ӢзҫҺд»Ӣз»Қз»ҷйӮЈдәӣд»Қ然еҜ№е®ғеӨҙз–јдёҚе·Ізҡ„жңӢеҸӢпјҢжүҖд»Ҙжң¬ж–ҮжҳҜдёәдәҶд»ҘдёӢиҜ»иҖ…иҖҢзү№ең°зј–еҶҷзҡ„пјҡ
1гҖҒ еңЁе·ҘдҪңдёӯдјҡз”ЁеҲ° SQL дҪҶжҳҜеҜ№е®ғ并дёҚе®Ңе…ЁдәҶи§Јзҡ„дәәгҖӮ
2гҖҒ иғҪеӨҹзҶҹз»ғдҪҝз”Ё SQL дҪҶжҳҜ并дёҚдәҶи§Је…¶иҜӯжі•йҖ»иҫ‘зҡ„дәәгҖӮ
3гҖҒ жғіиҰҒж•ҷеҲ«дәә SQL зҡ„дәәгҖӮ
жң¬ж–ҮзқҖйҮҚд»Ӣз»Қ SELECT еҸҘејҸпјҢе…¶д»–зҡ„ DML пјҲData Manipulation Language ж•°жҚ®ж“ҚзәөиҜӯиЁҖе‘Ҫд»Өпјүе°ҶдјҡеңЁеҲ«зҡ„ж–Үз« дёӯиҝӣиЎҢд»Ӣз»ҚгҖӮ
10дёӘз®ҖеҚ•жӯҘйӘӨпјҢе®Ңе…ЁзҗҶи§ЈSQL
1гҖҒ SQL жҳҜдёҖз§ҚеЈ°жҳҺејҸиҜӯиЁҖ
йҰ–е…ҲиҰҒжҠҠиҝҷдёӘжҰӮеҝөи®°еңЁи„‘дёӯпјҡвҖңеЈ°жҳҺвҖқгҖӮSQL иҜӯиЁҖжҳҜдёәи®Ўз®—жңәеЈ°жҳҺдәҶдёҖдёӘдҪ жғід»ҺеҺҹе§Ӣж•°жҚ®дёӯиҺ·еҫ—д»Җд№Ҳж ·зҡ„з»“жһңзҡ„дёҖдёӘиҢғдҫӢпјҢиҖҢдёҚжҳҜе‘ҠиҜүи®Ўз®—жңәеҰӮдҪ•иғҪеӨҹеҫ—еҲ°з»“жһңгҖӮиҝҷжҳҜдёҚжҳҜеҫҲжЈ’пјҹ
пјҲиҜ‘иҖ…жіЁпјҡз®ҖеҚ•ең°иҜҙпјҢSQL иҜӯиЁҖеЈ°жҳҺзҡ„жҳҜз»“жһңйӣҶзҡ„еұһжҖ§пјҢи®Ўз®—жңәдјҡж №жҚ® SQL жүҖеЈ°жҳҺзҡ„еҶ…е®№жқҘд»Һж•°жҚ®еә“дёӯжҢ‘йҖүеҮәз¬ҰеҗҲеЈ°жҳҺзҡ„ж•°жҚ®пјҢиҖҢдёҚжҳҜеғҸдј з»ҹзј–зЁӢжҖқз»ҙеҺ»жҢҮзӨәи®Ўз®—жңәеҰӮдҪ•ж“ҚдҪңгҖӮпјү
SELECT first_name, last_name FROM employees WHERE salary > 100000дёҠйқўзҡ„дҫӢеӯҗеҫҲе®№жҳ“зҗҶи§ЈпјҢжҲ‘们дёҚе…іеҝғиҝҷдәӣйӣҮе‘ҳи®°еҪ•д»Һе“ӘйҮҢжқҘпјҢжҲ‘们жүҖйңҖиҰҒзҡ„еҸӘжҳҜйӮЈдәӣй«ҳи–ӘиҖ…зҡ„ж•°жҚ®пјҲиҜ‘иҖ…жіЁпјҡsalary>100000 пјүгҖӮ
жҲ‘们д»Һе“Әе„ҝеӯҰд№ еҲ°иҝҷдәӣпјҹ
еҰӮжһң SQL иҜӯиЁҖиҝҷд№Ҳз®ҖеҚ•пјҢйӮЈд№ҲжҳҜд»Җд№Ҳи®©дәә们вҖңй—» SQL иүІеҸҳвҖқпјҹдё»иҰҒзҡ„еҺҹеӣ жҳҜпјҡжҲ‘们жҪңж„ҸиҜҶдёӯзҡ„жҳҜжҢүз…§е‘Ҫд»ӨејҸзј–зЁӢзҡ„жҖқз»ҙж–№ејҸжҖқиҖғй—®йўҳзҡ„гҖӮе°ұеҘҪеғҸиҝҷж ·пјҡвҖңз”өи„‘пјҢе…Ҳжү§иЎҢиҝҷдёҖжӯҘпјҢеҶҚжү§иЎҢйӮЈдёҖжӯҘпјҢдҪҶжҳҜеңЁйӮЈд№ӢеүҚе…ҲжЈҖжҹҘдёҖдёӢжҳҜеҗҰж»Ўи¶іжқЎд»¶ A е’ҢжқЎд»¶ B вҖқгҖӮдҫӢеҰӮпјҢз”ЁеҸҳйҮҸдј еҸӮгҖҒдҪҝз”ЁеҫӘзҺҜиҜӯеҸҘгҖҒиҝӯд»ЈгҖҒи°ғз”ЁеҮҪж•°зӯүзӯүпјҢйғҪжҳҜиҝҷз§Қе‘Ҫд»ӨејҸзј–зЁӢзҡ„жҖқз»ҙжғҜејҸгҖӮ
2гҖҒ SQL зҡ„иҜӯ法并дёҚжҢүз…§иҜӯжі•йЎәеәҸжү§иЎҢ
SQL иҜӯеҸҘжңүдёҖдёӘи®©еӨ§йғЁеҲҶдәәйғҪж„ҹеҲ°еӣ°жғ‘зҡ„зү№жҖ§пјҢе°ұжҳҜпјҡSQL иҜӯеҸҘзҡ„жү§иЎҢйЎәеәҸи·ҹе…¶иҜӯеҸҘзҡ„иҜӯжі•йЎәеәҸ并дёҚдёҖиҮҙгҖӮSQL иҜӯеҸҘзҡ„иҜӯжі•йЎәеәҸжҳҜпјҡ
SELECT[DISTINCT]
FROM
WHERE
GROUP BY
HAVING
UNION
ORDER BY
дёәдәҶж–№дҫҝзҗҶи§ЈпјҢдёҠйқўе№¶жІЎжңүжҠҠжүҖжңүзҡ„ SQL иҜӯжі•з»“жһ„йғҪеҲ—еҮәжқҘпјҢдҪҶжҳҜе·Із»Ҹи¶ід»ҘиҜҙжҳҺ SQL иҜӯеҸҘзҡ„иҜӯжі•йЎәеәҸе’Ңе…¶жү§иЎҢйЎәеәҸе®Ңе…ЁдёҚдёҖж ·пјҢе°ұд»ҘдёҠиҝ°иҜӯеҸҘдёәдҫӢпјҢе…¶жү§иЎҢйЎәеәҸдёәпјҡ
FROM
WHERE
GROUP BY
HAVING
SELECT
DISTINCT
UNION
ORDER BY
е…ідәҺ SQL иҜӯеҸҘзҡ„жү§иЎҢйЎәеәҸпјҢжңүдёүдёӘеҖјеҫ—жҲ‘们注ж„Ҹзҡ„ең°ж–№пјҡ
1гҖҒ FROM жүҚжҳҜ SQL иҜӯеҸҘжү§иЎҢзҡ„жӯҘпјҢ并йқһ SELECT гҖӮж•°жҚ®еә“еңЁжү§иЎҢ SQL иҜӯеҸҘзҡ„жӯҘжҳҜе°Ҷж•°жҚ®д»ҺзЎ¬зӣҳеҠ иҪҪеҲ°ж•°жҚ®зј“еҶІеҢәдёӯпјҢд»ҘдҫҝеҜ№иҝҷдәӣж•°жҚ®иҝӣиЎҢж“ҚдҪңгҖӮпјҲиҜ‘иҖ…жіЁпјҡеҺҹж–ҮдёәвҖңThe first thing that happens is loading data from the disk into memory, in order to operate on such data.вҖқпјҢдҪҶжҳҜ并йқһеҰӮжӯӨпјҢд»Ҙ Oracle зӯүеёёз”Ёж•°жҚ®еә“дёәдҫӢпјҢж•°жҚ®жҳҜд»ҺзЎ¬зӣҳдёӯжҠҪеҸ–еҲ°ж•°жҚ®зј“еҶІеҢәдёӯиҝӣиЎҢж“ҚдҪңгҖӮпјү
2гҖҒ SELECT жҳҜеңЁеӨ§йғЁеҲҶиҜӯеҸҘжү§иЎҢдәҶд№ӢеҗҺжүҚжү§иЎҢзҡ„пјҢдёҘж јзҡ„иҜҙжҳҜеңЁ FROM е’Ң GROUP BY д№ӢеҗҺжү§иЎҢзҡ„гҖӮзҗҶи§ЈиҝҷдёҖзӮ№жҳҜйқһеёёйҮҚиҰҒзҡ„пјҢиҝҷе°ұжҳҜдҪ дёҚиғҪеңЁ WHERE дёӯдҪҝз”ЁеңЁ SELECT дёӯи®ҫе®ҡеҲ«еҗҚзҡ„еӯ—ж®өдҪңдёәеҲӨж–ӯжқЎд»¶зҡ„еҺҹеӣ гҖӮ
SELECT A.x + A.y AS zFROM AWHERE z = 10 -- z еңЁжӯӨеӨ„дёҚеҸҜз”ЁпјҢеӣ дёәSELECTжҳҜеҗҺжү§иЎҢзҡ„иҜӯеҸҘпјҒеҰӮжһңдҪ жғійҮҚз”ЁеҲ«еҗҚzпјҢдҪ жңүдёӨдёӘйҖүжӢ©гҖӮиҰҒд№Ҳе°ұйҮҚж–°еҶҷдёҖйҒҚ z жүҖд»ЈиЎЁзҡ„иЎЁиҫҫејҸпјҡ
SELECT A.x + A.y AS zFROM AWHERE (A.x + A.y) = 10вҖҰжҲ–иҖ…жұӮеҠ©дәҺиЎҚз”ҹиЎЁгҖҒйҖҡз”Ёж•°жҚ®иЎЁиҫҫејҸжҲ–иҖ…и§ҶеӣҫпјҢд»ҘйҒҝе…ҚеҲ«еҗҚйҮҚз”ЁгҖӮиҜ·зңӢдёӢж–Үдёӯзҡ„дҫӢеӯҗгҖӮ
3гҖҒ ж— и®әеңЁиҜӯжі•дёҠиҝҳжҳҜеңЁжү§иЎҢйЎәеәҸдёҠпјҢ UNION жҖ»жҳҜжҺ’еңЁеңЁ ORDER BY д№ӢеүҚгҖӮеҫҲеӨҡдәәи®ӨдёәжҜҸдёӘ UNION ж®өйғҪиғҪдҪҝз”Ё ORDER BY жҺ’еәҸпјҢдҪҶжҳҜж №жҚ® SQL иҜӯиЁҖж ҮеҮҶе’Ңеҗ„дёӘж•°жҚ®еә“ SQL зҡ„жү§иЎҢе·®ејӮжқҘзңӢпјҢиҝҷ并дёҚжҳҜзңҹзҡ„гҖӮе°Ҫз®Ўжҹҗдәӣж•°жҚ®еә“е…Ғи®ё SQL иҜӯеҸҘеҜ№еӯҗжҹҘиҜўпјҲsubqueriesпјүжҲ–иҖ…жҙҫз”ҹиЎЁпјҲderived tablesпјүиҝӣиЎҢжҺ’еәҸпјҢдҪҶжҳҜиҝҷ并дёҚиҜҙжҳҺиҝҷдёӘжҺ’еәҸеңЁ UNION ж“ҚдҪңиҝҮеҗҺд»ҚдҝқжҢҒжҺ’еәҸеҗҺзҡ„йЎәеәҸгҖӮ
жіЁж„Ҹпјҡ并йқһжүҖжңүзҡ„ж•°жҚ®еә“еҜ№ SQL иҜӯеҸҘдҪҝз”ЁзӣёеҗҢзҡ„и§Јжһҗж–№ејҸгҖӮеҰӮ MySQLгҖҒPostgreSQLе’Ң SQLite дёӯе°ұдёҚдјҡжҢүз…§дёҠйқўз¬¬дәҢзӮ№дёӯжүҖиҜҙзҡ„ж–№ејҸжү§иЎҢгҖӮ
жҲ‘们еӯҰеҲ°дәҶд»Җд№Ҳпјҹ
既然并дёҚжҳҜжүҖжңүзҡ„ж•°жҚ®еә“йғҪжҢүз…§дёҠиҝ°ж–№ејҸжү§иЎҢ SQL йў„и®ЎпјҢйӮЈжҲ‘们зҡ„收иҺ·жҳҜд»Җд№ҲпјҹжҲ‘们зҡ„收иҺ·жҳҜж°ёиҝңиҰҒи®°еҫ—пјҡSQL иҜӯеҸҘзҡ„иҜӯжі•йЎәеәҸе’Ңе…¶жү§иЎҢйЎәеәҸ并дёҚдёҖиҮҙпјҢиҝҷж ·жҲ‘们е°ұиғҪйҒҝе…ҚдёҖиҲ¬жҖ§зҡ„й”ҷиҜҜгҖӮеҰӮжһңдҪ иғҪи®°дҪҸ SQL иҜӯеҸҘиҜӯжі•йЎәеәҸе’Ңжү§иЎҢйЎәеәҸзҡ„е·®ејӮпјҢдҪ е°ұиғҪеҫҲе®№жҳ“зҡ„зҗҶи§ЈдёҖдәӣеҫҲеёёи§Ғзҡ„ SQL й—®йўҳгҖӮ
еҪ“然пјҢеҰӮжһңдёҖз§ҚиҜӯиЁҖиў«и®ҫи®ЎжҲҗиҜӯжі•йЎәеәҸзӣҙжҺҘеҸҚеә”е…¶иҜӯеҸҘзҡ„жү§иЎҢйЎәеәҸпјҢйӮЈд№Ҳиҝҷз§ҚиҜӯиЁҖеҜ№зЁӢеәҸе‘ҳжҳҜеҚҒеҲҶеҸӢеҘҪзҡ„пјҢиҝҷз§Қзј–зЁӢиҜӯиЁҖеұӮйқўзҡ„и®ҫи®ЎзҗҶеҝөе·Із»Ҹиў«еҫ®иҪҜеә”з”ЁеҲ°дәҶ LINQ иҜӯиЁҖдёӯгҖӮ
3гҖҒ SQL иҜӯиЁҖзҡ„ж ёеҝғжҳҜеҜ№иЎЁзҡ„еј•з”ЁпјҲtable referencesпјү
з”ұдәҺ SQL иҜӯеҸҘиҜӯжі•йЎәеәҸе’Ңжү§иЎҢйЎәеәҸзҡ„дёҚеҗҢпјҢеҫҲеӨҡеҗҢеӯҰдјҡи®ӨдёәSELECT дёӯзҡ„еӯ—ж®өдҝЎжҒҜжҳҜ SQL иҜӯеҸҘзҡ„ж ёеҝғгҖӮе…¶е®һзңҹжӯЈзҡ„ж ёеҝғеңЁдәҺеҜ№иЎЁзҡ„еј•з”ЁгҖӮ
ж №жҚ® SQL ж ҮеҮҶпјҢFROM иҜӯеҸҘиў«е®ҡд№үдёәпјҡ
<from clause> ::= FROM <table reference> [ { <comma> <table reference> }... ]FROM иҜӯеҸҘзҡ„вҖңиҫ“еҮәвҖқжҳҜдёҖеј иҒ”еҗҲиЎЁпјҢжқҘиҮӘдәҺжүҖжңүеј•з”Ёзҡ„иЎЁеңЁжҹҗдёҖз»ҙеәҰдёҠзҡ„иҒ”еҗҲгҖӮжҲ‘们们慢慢жқҘеҲҶжһҗпјҡ
FROM a, bдёҠйқўиҝҷеҸҘ FROM иҜӯеҸҘзҡ„иҫ“еҮәжҳҜдёҖеј иҒ”еҗҲиЎЁпјҢиҒ”еҗҲдәҶиЎЁ a е’ҢиЎЁ b гҖӮеҰӮжһң a иЎЁжңүдёүдёӘеӯ—ж®өпјҢ b иЎЁжңү 5 дёӘеӯ—ж®өпјҢйӮЈд№ҲиҝҷдёӘвҖңиҫ“еҮәиЎЁвҖқе°ұжңү 8 пјҲ =5+3пјүдёӘеӯ—ж®өгҖӮ
иҝҷдёӘиҒ”еҗҲиЎЁйҮҢзҡ„ж•°жҚ®жҳҜ a*bпјҢеҚі a е’Ң b зҡ„з¬ӣеҚЎе°”з§ҜгҖӮжҚўеҸҘиҜқиҜҙпјҢд№ҹе°ұжҳҜ a иЎЁдёӯзҡ„жҜҸдёҖжқЎж•°жҚ®йғҪиҰҒи·ҹ b иЎЁдёӯзҡ„жҜҸдёҖжқЎж•°жҚ®й…ҚеҜ№гҖӮеҰӮжһң a иЎЁжңү3 жқЎж•°жҚ®пјҢ b иЎЁжңү 5 жқЎж•°жҚ®пјҢйӮЈд№ҲиҒ”еҗҲиЎЁе°ұдјҡжңү 15 пјҲ =5*3пјүжқЎж•°жҚ®гҖӮ
FROM иҫ“еҮәзҡ„з»“жһңиў« WHERE иҜӯеҸҘзӯӣйҖүеҗҺиҰҒз»ҸиҝҮ GROUP BY иҜӯеҸҘеӨ„зҗҶпјҢд»ҺиҖҢеҪўжҲҗж–°зҡ„иҫ“еҮәз»“жһңгҖӮжҲ‘们еҗҺйқўиҝҳдјҡеҶҚи®Ёи®әиҝҷж–№йқўй—®йўҳгҖӮ
еҰӮжһңжҲ‘们д»ҺйӣҶеҗҲи®әпјҲе…ізі»д»Јж•°пјүзҡ„и§’еәҰжқҘзңӢпјҢдёҖеј ж•°жҚ®еә“зҡ„иЎЁе°ұжҳҜдёҖз»„ж•°жҚ®е…ғзҡ„е…ізі»пјҢиҖҢжҜҸдёӘ SQL иҜӯеҸҘдјҡж”№еҸҳдёҖз§ҚжҲ–ж•°з§Қе…ізі»пјҢд»ҺиҖҢдә§з”ҹеҮәж–°зҡ„ж•°жҚ®е…ғзҡ„е…ізі»пјҲеҚідә§з”ҹж–°зҡ„иЎЁпјүгҖӮ
жҲ‘们еӯҰеҲ°дәҶд»Җд№Ҳпјҹ
жҖқиҖғй—®йўҳзҡ„ж—¶еҖҷд»ҺиЎЁзҡ„и§’еәҰжқҘжҖқиҖғй—®йўҳжҸҗпјҢиҝҷж ·еҫҲе®№жҳ“зҗҶи§Јж•°жҚ®еҰӮдҪ•еңЁ SQL иҜӯеҸҘзҡ„вҖңжөҒж°ҙзәҝвҖқдёҠиҝӣиЎҢдәҶд»Җд№Ҳж ·зҡ„еҸҳеҠЁгҖӮ
4гҖҒ зҒөжҙ»еј•з”ЁиЎЁиғҪдҪҝ SQL иҜӯеҸҘеҸҳеҫ—жӣҙејәеӨ§
зҒөжҙ»еј•з”ЁиЎЁиғҪдҪҝ SQL иҜӯеҸҘеҸҳеҫ—жӣҙејәеӨ§гҖӮдёҖдёӘз®ҖеҚ•зҡ„дҫӢеӯҗе°ұжҳҜ JOIN зҡ„дҪҝз”ЁгҖӮдёҘж јзҡ„иҜҙ JOIN иҜӯеҸҘ并йқһжҳҜ SELECT дёӯзҡ„дёҖйғЁеҲҶпјҢиҖҢжҳҜдёҖз§Қзү№ж®Ҡзҡ„иЎЁеј•з”ЁиҜӯеҸҘгҖӮSQL иҜӯиЁҖж ҮеҮҶдёӯиЎЁзҡ„иҝһжҺҘе®ҡд№үеҰӮдёӢпјҡ
<table reference> ::= <table name> | <derived table> | <joined table>е°ұжӢҝд№ӢеүҚзҡ„дҫӢеӯҗжқҘиҜҙпјҡ
FROM a, ba еҸҜиғҪиҫ“е…ҘдёӢиЎЁзҡ„иҝһжҺҘпјҡ
a1 JOIN a2 ON a1.id = a2.idе°Ҷе®ғж”ҫеҲ°д№ӢеүҚзҡ„дҫӢеӯҗдёӯе°ұеҸҳжҲҗдәҶпјҡ
FROM a1 JOIN a2 ON a1.id = a2.id, bе°Ҫз®Ўе°ҶдёҖдёӘиҝһжҺҘиЎЁз”ЁйҖ—еҸ·и·ҹеҸҰдёҖеј иЎЁиҒ”еҗҲеңЁдёҖиө·е№¶дёҚжҳҜеёёз”ЁдҪңжі•пјҢдҪҶжҳҜдҪ зҡ„зЎ®еҸҜд»Ҙиҝҷд№ҲеҒҡгҖӮз»“жһңе°ұжҳҜпјҢз»Ҳиҫ“еҮәзҡ„иЎЁе°ұжңүдәҶ a1+a2+b дёӘеӯ—ж®өдәҶгҖӮ
пјҲиҜ‘иҖ…жіЁпјҡеҺҹж–ҮиҝҷйҮҢз”ЁиҜҚдёә degree пјҢиҜ‘дёәз»ҙеәҰгҖӮеҰӮжһңжҠҠдёҖеј иЎЁи§ҶеӣҫеҢ–пјҢжҲ‘们еҸҜд»ҘжғіиұЎжҜҸдёҖеј иЎЁйғҪжҳҜз”ұжЁӘзәөдёӨдёӘз»ҙеәҰз»„жҲҗзҡ„пјҢжЁӘеҗ‘з»ҙеәҰеҚіжҲ‘们жүҖиҜҙзҡ„еӯ—ж®өжҲ–иҖ…еҲ—пјҢиӢұж–Үдёәcolumnsпјӣзәөеҗ‘з»ҙеәҰеҚід»ЈиЎЁдәҶжҜҸжқЎж•°жҚ®пјҢиӢұж–Үдёә record пјҢж №жҚ®дёҠдёӢж–ҮпјҢдҪңиҖ…иҝҷйҮҢжүҖжҢҮзҡ„еә”иҜҘжҳҜеӯ—ж®өж•°гҖӮпјү
еңЁ SQL иҜӯеҸҘдёӯжҙҫз”ҹиЎЁзҡ„еј•з”Ёз”ҡиҮіжҜ”иЎЁиҝһжҺҘжӣҙеҠ ејәеӨ§пјҢдёӢйқўжҲ‘们е°ұиҰҒи®ІеҲ°иЎЁиҝһжҺҘгҖӮ
жҲ‘们еӯҰеҲ°дәҶд»Җд№Ҳпјҹ
жҖқиҖғй—®йўҳж—¶пјҢиҰҒд»ҺиЎЁеј•з”Ёзҡ„и§’еәҰеҮәеҸ‘пјҢиҝҷж ·е°ұеҫҲе®№жҳ“зҗҶи§Јж•°жҚ®жҳҜжҖҺж ·иў« SQL иҜӯеҸҘеӨ„зҗҶзҡ„пјҢ并且иғҪеӨҹеё®еҠ©дҪ зҗҶи§ЈйӮЈдәӣеӨҚжқӮзҡ„иЎЁеј•з”ЁжҳҜеҒҡд»Җд№Ҳзҡ„гҖӮ
жӣҙйҮҚиҰҒзҡ„жҳҜпјҢиҰҒзҗҶи§Ј JOIN жҳҜжһ„е»әиҝһжҺҘиЎЁзҡ„е…ій”®иҜҚпјҢ并дёҚжҳҜ SELECT иҜӯеҸҘзҡ„дёҖйғЁеҲҶгҖӮжңүдёҖдәӣж•°жҚ®еә“е…Ғи®ёеңЁ INSERT гҖҒ UPDATE гҖҒ DELETE дёӯдҪҝз”Ё JOIN гҖӮ
5гҖҒ SQL иҜӯеҸҘдёӯжҺЁиҚҗдҪҝз”ЁиЎЁиҝһжҺҘ
жҲ‘们е…ҲзңӢзңӢеҲҡеҲҡиҝҷеҸҘпјҡ
FROM a, bSQL зЁӢеәҸе‘ҳд№ҹи®ёеӯҰдјҡз»ҷдҪ еҝ е‘Ҡпјҡе°ҪйҮҸдёҚиҰҒдҪҝз”ЁйҖ—еҸ·жқҘд»Јжӣҝ JOIN иҝӣиЎҢиЎЁзҡ„иҝһжҺҘпјҢиҝҷж ·дјҡжҸҗй«ҳдҪ зҡ„ SQL иҜӯеҸҘзҡ„еҸҜиҜ»жҖ§пјҢ并且еҸҜд»ҘйҒҝе…ҚдёҖдәӣй”ҷиҜҜгҖӮ
еҲ©з”ЁйҖ—еҸ·жқҘз®ҖеҢ– SQL иҜӯеҸҘжңүж—¶еҖҷдјҡйҖ жҲҗжҖқз»ҙдёҠзҡ„ж··д№ұпјҢжғідёҖдёӢдёӢйқўзҡ„иҜӯеҸҘпјҡ
FROM a, b, c, d, e, f, g, hWHERE a.a1 = b.bxAND a.a2 = c.c1AND d.d1 = b.bc-- etc...жҲ‘们дёҚйҡҫзңӢеҮәдҪҝз”Ё JOIN иҜӯеҸҘзҡ„еҘҪеӨ„еңЁдәҺпјҡ
е®үе…ЁгҖӮJOIN е’ҢиҰҒиҝһжҺҘзҡ„иЎЁзҰ»еҫ—йқһеёёиҝ‘пјҢиҝҷж ·е°ұиғҪйҒҝе…Қй”ҷиҜҜгҖӮ
жӣҙеӨҡиҝһжҺҘзҡ„ж–№ејҸпјҢJOIN иҜӯеҸҘиғҪеҺ»еҢәеҲҶеҮәжқҘеӨ–иҝһжҺҘе’ҢеҶ…иҝһжҺҘзӯүгҖӮ
жҲ‘们еӯҰеҲ°дәҶд»Җд№Ҳпјҹ
и®°зқҖиҰҒе°ҪйҮҸдҪҝз”Ё JOIN иҝӣиЎҢиЎЁзҡ„иҝһжҺҘпјҢж°ёиҝңдёҚиҰҒеңЁ FROM еҗҺйқўдҪҝз”ЁйҖ—еҸ·иҝһжҺҘиЎЁгҖӮ
6гҖҒ SQL иҜӯеҸҘдёӯдёҚеҗҢзҡ„иҝһжҺҘж“ҚдҪң
SQL иҜӯеҸҘдёӯпјҢиЎЁиҝһжҺҘзҡ„ж–№ејҸд»Һж №жң¬дёҠеҲҶдёәдә”з§Қпјҡ
EQUI JOIN
SEMI JOIN
ANTI JOIN
CROSS JOIN
DIVISION
EQUI JOIN
иҝҷжҳҜдёҖз§Қжҷ®йҖҡзҡ„ JOIN ж“ҚдҪңпјҢе®ғеҢ…еҗ«дёӨз§ҚиҝһжҺҘж–№ејҸпјҡ
INNER JOINпјҲжҲ–иҖ…жҳҜ JOIN пјү
OUTER JOINпјҲеҢ…жӢ¬пјҡLEFT гҖҒ RIGHTгҖҒ FULL OUTER JOINпјү
з”ЁдҫӢеӯҗе®№жҳ“иҜҙжҳҺе…¶дёӯеҢәеҲ«пјҡ

иҝҷз§ҚиҝһжҺҘе…ізі»еңЁ SQL дёӯжңүдёӨз§ҚиЎЁзҺ°ж–№ејҸпјҡдҪҝз”Ё INпјҢжҲ–иҖ…дҪҝз”Ё EXISTSгҖӮвҖң SEMI вҖқеңЁжӢүдёҒж–ҮдёӯжҳҜвҖңеҚҠвҖқзҡ„ж„ҸжҖқгҖӮиҝҷз§ҚиҝһжҺҘж–№ејҸжҳҜеҸӘиҝһжҺҘзӣ®ж ҮиЎЁзҡ„дёҖйғЁеҲҶгҖӮиҝҷжҳҜд»Җд№Ҳж„ҸжҖқе‘ўпјҹеҶҚжғідёҖдёӢдёҠйқўе…ідәҺдҪңиҖ…е’Ңд№ҰеҗҚзҡ„иҝһжҺҘгҖӮжҲ‘们жғіиұЎдёҖдёӢиҝҷж ·зҡ„жғ…еҶөпјҡжҲ‘们дёҚйңҖиҰҒдҪңиҖ… / д№ҰеҗҚиҝҷж ·зҡ„з»„еҗҲпјҢеҸӘжҳҜйңҖиҰҒйӮЈдәӣеңЁд№ҰеҗҚиЎЁдёӯзҡ„д№Ұзҡ„дҪңиҖ…дҝЎжҒҜгҖӮйӮЈжҲ‘们е°ұиғҪиҝҷд№ҲеҶҷпјҡ

е°Ҫз®ЎжІЎжңүдёҘж јзҡ„规е®ҡиҜҙжҳҺдҪ дҪ•ж—¶еә”иҜҘдҪҝз”Ё IN пјҢдҪ•ж—¶еә”иҜҘдҪҝз”Ё EXISTS пјҢдҪҶжҳҜиҝҷдәӣдәӢжғ…дҪ иҝҳжҳҜеә”иҜҘзҹҘйҒ“зҡ„пјҡ
INжҜ” EXISTS зҡ„еҸҜиҜ»жҖ§жӣҙеҘҪ
EXISTS жҜ”IN зҡ„иЎЁиҫҫжҖ§жӣҙеҘҪпјҲжӣҙйҖӮеҗҲеӨҚжқӮзҡ„иҜӯеҸҘпјү
дәҢиҖ…д№Ӣй—ҙжҖ§иғҪжІЎжңүе·®ејӮпјҲдҪҶеҜ№дәҺжҹҗдәӣж•°жҚ®еә“жқҘиҜҙжҖ§иғҪе·®ејӮдјҡйқһеёёеӨ§пјү
еӣ дёәдҪҝз”Ё INNER JOIN д№ҹиғҪеҫ—еҲ°д№ҰеҗҚиЎЁдёӯд№ҰжүҖеҜ№еә”зҡ„дҪңиҖ…дҝЎжҒҜпјҢжүҖд»ҘеҫҲеӨҡеҲқеӯҰиҖ…жңәдјҡи®ӨдёәеҸҜд»ҘйҖҡиҝҮ DISTINCT иҝӣиЎҢеҺ»йҮҚпјҢ然еҗҺе°Ҷ SEMI JOIN иҜӯеҸҘеҶҷжҲҗиҝҷж ·пјҡ
-- Find only those authors who also have booksSELECT DISTINCT first_name, last_nameFROM authorJOIN book ON author.id = book.author_idиҝҷжҳҜдёҖз§ҚеҫҲзіҹзі•зҡ„еҶҷжі•пјҢеҺҹеӣ еҰӮдёӢпјҡ
SQL иҜӯеҸҘжҖ§иғҪдҪҺдёӢпјҡеӣ дёәеҺ»йҮҚж“ҚдҪңпјҲ DISTINCT пјүйңҖиҰҒж•°жҚ®еә“йҮҚеӨҚд»ҺзЎ¬зӣҳдёӯиҜ»еҸ–ж•°жҚ®еҲ°еҶ…еӯҳдёӯгҖӮпјҲиҜ‘иҖ…жіЁпјҡDISTINCT зҡ„зЎ®жҳҜдёҖз§ҚеҫҲиҖ—иҙ№иө„жәҗзҡ„ж“ҚдҪңпјҢдҪҶжҳҜжҜҸз§Қж•°жҚ®еә“еҜ№дәҺ DISTINCT зҡ„ж“ҚдҪңж–№ејҸеҸҜиғҪдёҚеҗҢпјүгҖӮ
иҝҷд№ҲеҶҷ并йқһе®Ңе…ЁжӯЈзЎ®пјҡе°Ҫз®Ўд№ҹи®ёзҺ°еңЁиҝҷд№ҲеҶҷдёҚдјҡеҮәзҺ°й—®йўҳпјҢдҪҶжҳҜйҡҸзқҖ SQL иҜӯеҸҘеҸҳеҫ—и¶ҠжқҘи¶ҠеӨҚжқӮпјҢдҪ жғіиҰҒеҺ»йҮҚеҫ—еҲ°жӯЈзЎ®зҡ„з»“жһңе°ұеҸҳеҫ—еҚҒеҲҶеӣ°йҡҫгҖӮ
жӣҙеӨҡзҡ„е…ідәҺж»Ҙз”Ё DISTINCT зҡ„еҚұе®іеҸҜд»ҘеҸӮиҖғиҝҷзҜҮеҚҡж–Ү
пјҲhttp://blog.jooq.org/2013/07/30/10-common-mistakes-java-developers-make-when-writing-sql/пјүгҖӮ
ANTI JOIN
иҝҷз§ҚиҝһжҺҘзҡ„е…ізі»и·ҹ SEMI JOIN еҲҡеҘҪзӣёеҸҚгҖӮеңЁ IN жҲ–иҖ… EXISTS еүҚеҠ дёҖдёӘ NOT е…ій”®еӯ—е°ұиғҪдҪҝз”Ёиҝҷз§ҚиҝһжҺҘгҖӮдёҫдёӘдҫӢеӯҗжқҘиҜҙпјҢжҲ‘们еҲ—еҮәд№ҰеҗҚиЎЁйҮҢжІЎжңүд№Ұзҡ„дҪңиҖ…пјҡ
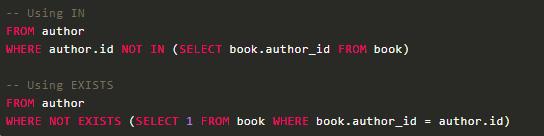
е…ідәҺжҖ§иғҪгҖҒеҸҜиҜ»жҖ§гҖҒиЎЁиҫҫжҖ§зӯүзү№жҖ§д№ҹе®Ңе…ЁеҸҜд»ҘеҸӮиҖғ SEMI JOINгҖӮ
иҝҷзҜҮеҚҡж–Үд»Ӣз»ҚдәҶеңЁдҪҝз”Ё NOT IN ж—¶йҒҮеҲ° NULL еә”иҜҘжҖҺд№ҲеҠһпјҢеӣ дёәжңүдёҖзӮ№иғҢзҰ»жң¬зҜҮдё»йўҳпјҢе°ұдёҚиҜҰз»Ҷд»Ӣз»ҚпјҢжңүе…ҙи¶Јзҡ„еҗҢеӯҰеҸҜд»ҘиҜ»дёҖдёӢ
пјҲhttp://blog.jooq.org/2012/01/27/sql-incompatibilities-not-in-and-null-values/пјүгҖӮ
CROSS JOIN
иҝҷдёӘиҝһжҺҘиҝҮзЁӢе°ұжҳҜдёӨдёӘиҝһжҺҘзҡ„иЎЁзҡ„д№ҳз§ҜпјҡеҚіе°Ҷеј иЎЁзҡ„жҜҸдёҖжқЎж•°жҚ®еҲҶеҲ«еҜ№еә”第дәҢеј иЎЁзҡ„жҜҸжқЎж•°жҚ®гҖӮжҲ‘们д№ӢеүҚи§ҒиҝҮпјҢиҝҷе°ұжҳҜйҖ—еҸ·еңЁ FROM иҜӯеҸҘдёӯзҡ„з”Ёжі•гҖӮеңЁе®һйҷ…зҡ„еә”з”ЁдёӯпјҢеҫҲе°‘жңүең°ж–№иғҪз”ЁеҲ° CROSS JOINпјҢдҪҶжҳҜдёҖж—Ұз”ЁдёҠдәҶпјҢдҪ е°ұеҸҜд»Ҙз”Ёиҝҷж ·зҡ„ SQLиҜӯеҸҘиЎЁиҫҫпјҡ
-- Combine every author with every bookauthor CROSS JOIN book
DIVISION
DIVISION зҡ„зЎ®жҳҜдёҖдёӘжҖӘиғҺгҖӮз®ҖиҖҢиЁҖд№ӢпјҢеҰӮжһң JOIN жҳҜдёҖдёӘд№ҳжі•иҝҗз®—пјҢйӮЈд№Ҳ DIVISION е°ұжҳҜ JOIN зҡ„йҖҶиҝҮзЁӢгҖӮDIVISION зҡ„е…ізі»еҫҲйҡҫз”Ё SQL иЎЁиҫҫеҮәжқҘпјҢд»ӢдәҺиҝҷжҳҜдёҖдёӘж–°жүӢжҢҮеҚ—пјҢи§ЈйҮҠ DIVISION е·Із»Ҹи¶…еҮәдәҶжҲ‘们зҡ„зӣ®зҡ„гҖӮдҪҶжҳҜжңүе…ҙи¶Јзҡ„еҗҢеӯҰиҝҳжҳҜеҸҜд»ҘжқҘзңӢзңӢиҝҷдёүзҜҮж–Үз«
пјҲhttp://blog.jooq.org/2012/03/30/advanced-sql-relational-division-in-jooq/пјү
пјҲhttp://en.wikipedia.org/wiki/Relational_algebra#Divisionпјү
пјҲhttps://www.simple-talk.com/sql/t-sql-programming/divided-we-stand-the-sql-of-relational-division/пјүгҖӮ
жҲ‘们еӯҰеҲ°дәҶд»Җд№Ҳпјҹ
еӯҰеҲ°дәҶеҫҲеӨҡпјҒи®©жҲ‘们еңЁи„‘жө·дёӯеҶҚеӣһжғідёҖдёӢгҖӮSQL жҳҜеҜ№иЎЁзҡ„еј•з”ЁпјҢ JOIN еҲҷжҳҜдёҖз§Қеј•з”ЁиЎЁзҡ„еӨҚжқӮж–№ејҸгҖӮдҪҶжҳҜ SQL иҜӯиЁҖзҡ„иЎЁиҫҫж–№ејҸе’Ңе®һйҷ…жҲ‘们жүҖйңҖиҰҒзҡ„йҖ»иҫ‘е…ізі»д№Ӣй—ҙжҳҜжңүеҢәеҲ«зҡ„пјҢ并йқһжүҖжңүзҡ„йҖ»иҫ‘е…ізі»йғҪиғҪжүҫеҲ°еҜ№еә”зҡ„ JOIN ж“ҚдҪңпјҢжүҖд»Ҙиҝҷе°ұиҰҒжҲ‘们еңЁе№іж—¶еӨҡз§ҜзҙҜе’ҢеӯҰд№ е…ізі»йҖ»иҫ‘пјҢиҝҷж ·дҪ е°ұиғҪеңЁд»ҘеҗҺзј–еҶҷ SQL иҜӯеҸҘдёӯйҖүжӢ©йҖӮеҪ“зҡ„ JOIN ж“ҚдҪңдәҶгҖӮ
7гҖҒ SQL дёӯеҰӮеҗҢеҸҳйҮҸзҡ„жҙҫз”ҹиЎЁ
еңЁиҝҷд№ӢеүҚпјҢжҲ‘们еӯҰд№ еҲ°иҝҮ SQL жҳҜдёҖз§ҚеЈ°жҳҺжҖ§зҡ„иҜӯиЁҖпјҢ并且 SQL иҜӯеҸҘдёӯдёҚиғҪеҢ…еҗ«еҸҳйҮҸгҖӮдҪҶжҳҜдҪ иғҪеҶҷеҮәзұ»дјјдәҺеҸҳйҮҸзҡ„иҜӯеҸҘпјҢиҝҷдәӣе°ұеҸ«еҒҡжҙҫз”ҹиЎЁпјҡ
иҜҙзҷҪдәҶпјҢжүҖи°“зҡ„жҙҫз”ҹиЎЁе°ұжҳҜеңЁжӢ¬еҸ·д№Ӣдёӯзҡ„еӯҗжҹҘиҜўпјҡ
-- A derived tableFROM (SELECT * FROM author)
йңҖиҰҒжіЁж„Ҹзҡ„жҳҜжңүдәӣж—¶еҖҷжҲ‘们еҸҜд»Ҙз»ҷжҙҫз”ҹиЎЁе®ҡд№үдёҖдёӘзӣёе…іеҗҚпјҲеҚіжҲ‘们жүҖиҜҙзҡ„еҲ«еҗҚпјүгҖӮ
-- A derived table with an aliasFROM (SELECT * FROM author) a
жҙҫз”ҹиЎЁеҸҜд»Ҙжңүж•Ҳзҡ„йҒҝе…Қз”ұдәҺ SQL йҖ»иҫ‘иҖҢдә§з”ҹзҡ„й—®йўҳгҖӮдёҫдҫӢжқҘиҜҙпјҡеҰӮжһңдҪ жғійҮҚз”ЁдёҖдёӘз”Ё SELECT е’Ң WHERE иҜӯеҸҘжҹҘиҜўеҮәзҡ„з»“жһңпјҢиҝҷж ·еҶҷе°ұеҸҜд»ҘпјҲд»Ҙ Oracle дёәдҫӢпјүпјҡ

еҪ“然дәҶпјҢдҪ д№ҹеҸҜд»Ҙз»ҷвҖң a вҖқеҲӣе»әдёҖдёӘеҚ•зӢ¬зҡ„и§ҶеӣҫпјҢиҝҷж ·дҪ е°ұеҸҜд»ҘеңЁжӣҙе№ҝжіӣзҡ„иҢғеӣҙеҶ…йҮҚз”ЁиҝҷдёӘжҙҫз”ҹиЎЁдәҶгҖӮжӣҙеӨҡдҝЎжҒҜеҸҜд»Ҙйҳ…иҜ»дёӢйқўзҡ„ж–Үз« пјҲhttp://en.wikipedia.org/wiki/View_%28SQL%29пјүгҖӮ
жҲ‘们еӯҰеҲ°дәҶд»Җд№Ҳпјҹ
жҲ‘们еҸҚеӨҚејәи°ғпјҢеӨ§дҪ“дёҠжқҘиҜҙ SQL иҜӯеҸҘе°ұжҳҜеҜ№иЎЁзҡ„еј•з”ЁпјҢиҖҢ并йқһеҜ№еӯ—ж®өзҡ„еј•з”ЁгҖӮиҰҒеҘҪеҘҪеҲ©з”ЁиҝҷдёҖзӮ№пјҢдёҚиҰҒе®іжҖ•дҪҝз”Ёжҙҫз”ҹиЎЁжҲ–иҖ…е…¶д»–жӣҙеӨҚжқӮзҡ„иҜӯеҸҘгҖӮ
8гҖҒ SQL иҜӯеҸҘдёӯ GROUP BY жҳҜеҜ№иЎЁзҡ„еј•з”ЁиҝӣиЎҢзҡ„ж“ҚдҪң
и®©жҲ‘们еҶҚеӣһжғідёҖдёӢд№ӢеүҚзҡ„ FROM иҜӯеҸҘпјҡ
FROM a, b
зҺ°еңЁпјҢжҲ‘们е°Ҷ GROUP BY еә”з”ЁеҲ°дёҠйқўзҡ„иҜӯеҸҘдёӯпјҡ
GROUP BY A.x, A.y, B.z
дёҠйқўиҜӯеҸҘзҡ„з»“жһңе°ұжҳҜдә§з”ҹеҮәдәҶдёҖдёӘеҢ…еҗ«дёүдёӘеӯ—ж®өзҡ„ж–°зҡ„иЎЁзҡ„еј•з”ЁгҖӮжҲ‘们жқҘд»”з»ҶзҗҶи§ЈдёҖдёӢиҝҷеҸҘиҜқпјҡеҪ“дҪ еә”з”Ё GROUP BY зҡ„ж—¶еҖҷпјҢ SELECT еҗҺжІЎжңүдҪҝз”ЁиҒҡеҗҲеҮҪж•°зҡ„еҲ—пјҢйғҪиҰҒеҮәзҺ°еңЁ GROUP BY еҗҺйқўгҖӮпјҲиҜ‘иҖ…жіЁпјҡеҺҹж–ҮеӨ§ж„ҸдёәвҖңеҪ“дҪ жҳҜз”Ё GROUP BY зҡ„ж—¶еҖҷпјҢдҪ иғҪеӨҹеҜ№е…¶иҝӣиЎҢдёӢдёҖзә§йҖ»иҫ‘ж“ҚдҪңзҡ„еҲ—дјҡеҮҸе°‘пјҢеҢ…жӢ¬еңЁ SELECT дёӯзҡ„еҲ—вҖқпјүгҖӮ
йңҖиҰҒжіЁж„Ҹзҡ„жҳҜпјҡе…¶д»–еӯ—ж®өиғҪеӨҹдҪҝз”ЁиҒҡеҗҲеҮҪж•°пјҡ
SELECT A.x, A.y, SUM(A.z)FROM AGROUP BY A.x, A.y
иҝҳжңүдёҖзӮ№еҖјеҫ—з•ҷж„Ҹзҡ„жҳҜпјҡMySQL 并дёҚеқҡжҢҒиҝҷдёӘж ҮеҮҶпјҢиҝҷзҡ„зЎ®жҳҜд»ӨдәәеҫҲеӣ°жғ‘зҡ„ең°ж–№гҖӮпјҲиҜ‘иҖ…жіЁпјҡиҝҷ并дёҚжҳҜиҜҙ MySQL жІЎжңү GROUP BY зҡ„еҠҹиғҪпјүдҪҶжҳҜдёҚиҰҒиў« MySQL жүҖиҝ·жғ‘гҖӮGROUP BY ж”№еҸҳдәҶеҜ№иЎЁеј•з”Ёзҡ„ж–№ејҸгҖӮдҪ еҸҜд»ҘеғҸиҝҷж ·ж—ўеңЁ SELECT дёӯеј•з”ЁжҹҗдёҖеӯ—ж®өпјҢд№ҹеңЁ GROUP BY дёӯеҜ№е…¶иҝӣиЎҢеҲҶз»„гҖӮ
жҲ‘们еӯҰеҲ°дәҶд»Җд№Ҳпјҹ
GROUP BYпјҢеҶҚж¬Ўејәи°ғдёҖж¬ЎпјҢжҳҜеңЁиЎЁзҡ„еј•з”ЁдёҠиҝӣиЎҢдәҶж“ҚдҪңпјҢе°Ҷе…¶иҪ¬жҚўдёәдёҖз§Қж–°зҡ„еј•з”Ёж–№ејҸгҖӮ
9гҖҒ SQL иҜӯеҸҘдёӯзҡ„ SELECT е®һиҙЁдёҠжҳҜеҜ№е…ізі»зҡ„жҳ е°„
жҲ‘дёӘдәәжҜ”иҫғе–ңж¬ўвҖңжҳ е°„вҖқиҝҷдёӘиҜҚпјҢе°Өе…¶жҳҜжҠҠе®ғз”ЁеңЁе…ізі»д»Јж•°дёҠгҖӮпјҲиҜ‘иҖ…жіЁпјҡеҺҹж–Үз”ЁиҜҚдёә projection пјҢиҜҘиҜҚжңүдёӨеұӮеҗ«д№үпјҢз§Қеҗ«д№үжҳҜйў„жөӢгҖҒ规еҲ’гҖҒи®ҫи®ЎпјҢ第дәҢз§Қж„ҸжҖқжҳҜжҠ•е°„гҖҒжҳ е°„пјҢз»ҸиҝҮеҸҚеӨҚжҺЁж•ІпјҢжҲ‘и§үеҫ—иҝҷйҮҢз”Ёжҳ е°„иғҪеӨҹжӣҙзӣҙи§Ӯзҡ„иЎЁиҫҫеҮә SELECT зҡ„дҪңз”ЁпјүгҖӮдёҖж—ҰдҪ е»әз«Ӣиө·жқҘдәҶиЎЁзҡ„еј•з”ЁпјҢз»ҸиҝҮдҝ®ж”№гҖҒеҸҳеҪўпјҢдҪ иғҪеӨҹдёҖжӯҘдёҖжӯҘзҡ„е°Ҷе…¶жҳ е°„еҲ°еҸҰдёҖдёӘжЁЎеһӢдёӯгҖӮSELECT иҜӯеҸҘе°ұеғҸдёҖдёӘвҖңжҠ•еҪұд»ӘвҖқпјҢжҲ‘们еҸҜд»Ҙе°Ҷе…¶зҗҶи§ЈжҲҗдёҖдёӘе°ҶжәҗиЎЁдёӯзҡ„ж•°жҚ®жҢүз…§дёҖе®ҡзҡ„йҖ»иҫ‘иҪ¬жҚўжҲҗзӣ®ж ҮиЎЁж•°жҚ®зҡ„еҮҪж•°гҖӮ
йҖҡиҝҮ SELECTиҜӯеҸҘпјҢдҪ иғҪеҜ№жҜҸдёҖдёӘеӯ—ж®өиҝӣиЎҢж“ҚдҪңпјҢйҖҡиҝҮеӨҚжқӮзҡ„иЎЁиҫҫејҸз”ҹжҲҗжүҖйңҖиҰҒзҡ„ж•°жҚ®гҖӮ
SELECT иҜӯеҸҘжңүеҫҲеӨҡзү№ж®Ҡзҡ„规еҲҷпјҢиҮіе°‘дҪ еә”иҜҘзҶҹжӮүд»ҘдёӢеҮ жқЎпјҡ
дҪ д»…иғҪеӨҹдҪҝз”ЁйӮЈдәӣиғҪйҖҡиҝҮиЎЁеј•з”ЁиҖҢеҫ—жқҘзҡ„еӯ—ж®өпјӣ
еҰӮжһңдҪ жңү GROUP BY иҜӯеҸҘпјҢдҪ еҸӘиғҪеӨҹдҪҝз”Ё GROUP BY иҜӯеҸҘеҗҺйқўзҡ„еӯ—ж®өжҲ–иҖ…иҒҡеҗҲеҮҪж•°пјӣ
еҪ“дҪ зҡ„иҜӯеҸҘдёӯжІЎжңү GROUP BY зҡ„ж—¶еҖҷпјҢеҸҜд»ҘдҪҝз”ЁејҖзӘ—еҮҪж•°д»ЈжӣҝиҒҡеҗҲеҮҪж•°пјӣ
еҪ“дҪ зҡ„иҜӯеҸҘдёӯжІЎжңү GROUP BY зҡ„ж—¶еҖҷпјҢдҪ дёҚиғҪеҗҢж—¶дҪҝз”ЁиҒҡеҗҲеҮҪж•°е’Ңе…¶е®ғеҮҪж•°пјӣ
жңүдёҖдәӣж–№жі•еҸҜд»Ҙе°Ҷжҷ®йҖҡеҮҪж•°е°ҒиЈ…еңЁиҒҡеҗҲеҮҪж•°дёӯпјӣ
вҖҰвҖҰ
дёҖдәӣжӣҙеӨҚжқӮзҡ„规еҲҷеӨҡеҲ°и¶іеӨҹеҶҷеҮәеҸҰдёҖзҜҮж–Үз« дәҶгҖӮжҜ”еҰӮпјҡдёәдҪ•дҪ дёҚиғҪеңЁдёҖдёӘжІЎжңү GROUP BY зҡ„ SELECT иҜӯеҸҘдёӯеҗҢж—¶дҪҝз”Ёжҷ®йҖҡеҮҪж•°е’ҢиҒҡеҗҲеҮҪж•°пјҹпјҲдёҠйқўзҡ„第 4 жқЎпјү
еҺҹеӣ еҰӮдёӢпјҡ
еҮӯзӣҙи§үпјҢиҝҷз§ҚеҒҡжі•д»ҺйҖ»иҫ‘дёҠе°ұи®ІдёҚйҖҡгҖӮ
еҰӮжһңзӣҙи§үдёҚиғҪеӨҹиҜҙжңҚдҪ пјҢйӮЈд№ҲиҜӯжі•иӮҜе®ҡиғҪгҖӮSQL : 1999 ж ҮеҮҶеј•е…ҘдәҶ GROUPING SETSпјҢSQLпјҡ2003 ж ҮеҮҶеј•е…ҘдәҶ group sets : GROUP BY() гҖӮж— и®әд»Җд№Ҳж—¶еҖҷпјҢеҸӘиҰҒдҪ зҡ„иҜӯеҸҘдёӯеҮәзҺ°дәҶиҒҡеҗҲеҮҪж•°пјҢиҖҢ且并没жңүжҳҺзЎ®зҡ„ GROUP BY иҜӯеҸҘпјҢиҝҷж—¶дёҖдёӘдёҚжҳҺзЎ®зҡ„гҖҒз©әзҡ„ GROUPING SET е°ұдјҡиў«еә”з”ЁеҲ°иҝҷж®ө SQL дёӯгҖӮеӣ жӯӨпјҢеҺҹе§Ӣзҡ„йҖ»иҫ‘йЎәеәҸзҡ„规еҲҷе°ұиў«жү“з ҙдәҶпјҢжҳ е°„пјҲеҚі SELECT пјүе…ізі»йҰ–е…ҲдјҡеҪұе“ҚеҲ°йҖ»иҫ‘е…ізі»пјҢе…¶ж¬Ўе°ұжҳҜиҜӯжі•е…ізі»гҖӮпјҲиҜ‘иҖ…жіЁпјҡиҝҷж®өиҜқеҺҹж–Үе°ұжҜ”иҫғиү°ж¶©пјҢеҸҜд»Ҙз®ҖеҚ•зҗҶи§ЈеҰӮдёӢпјҡеңЁж—ўжңүиҒҡеҗҲеҮҪж•°еҸҲжңүжҷ®йҖҡеҮҪж•°зҡ„ SQL иҜӯеҸҘдёӯпјҢеҰӮжһңжІЎжңү GROUP BY иҝӣиЎҢеҲҶз»„пјҢSQL иҜӯеҸҘй»ҳи®Өи§Ҷж•ҙеј иЎЁдёәдёҖдёӘеҲҶз»„пјҢеҪ“иҒҡеҗҲеҮҪж•°еҜ№жҹҗдёҖеӯ—ж®өиҝӣиЎҢиҒҡеҗҲз»ҹи®Ўзҡ„ж—¶еҖҷпјҢеј•з”Ёзҡ„иЎЁдёӯзҡ„жҜҸдёҖжқЎ record е°ұеӨұеҺ»дәҶж„Ҹд№үпјҢе…ЁйғЁзҡ„ж•°жҚ®йғҪиҒҡеҗҲдёәдёҖдёӘз»ҹи®ЎеҖјпјҢдҪ жӯӨж—¶еҜ№жҜҸдёҖжқЎ record дҪҝз”Ёе…¶е®ғеҮҪж•°жҳҜжІЎжңүж„Ҹд№үзҡ„пјүгҖӮ
зіҠж¶ӮдәҶпјҹжҳҜзҡ„пјҢжҲ‘д№ҹжҳҜгҖӮжҲ‘们еҶҚеӣһиҝҮеӨҙжқҘзңӢзӮ№жө…жҳҫзҡ„дёңиҘҝеҗ§гҖӮ
жҲ‘们еӯҰеҲ°дәҶд»Җд№Ҳпјҹ
SELECT иҜӯеҸҘеҸҜиғҪжҳҜ SQL иҜӯеҸҘдёӯйҡҫзҡ„йғЁеҲҶдәҶпјҢе°Ҫз®Ўд»–зңӢдёҠеҺ»еҫҲз®ҖеҚ•гҖӮе…¶д»–иҜӯеҸҘзҡ„дҪңз”Ёе…¶е®һе°ұжҳҜеҜ№иЎЁзҡ„дёҚеҗҢеҪўејҸзҡ„еј•з”ЁгҖӮиҖҢ SELECT иҜӯеҸҘеҲҷжҠҠиҝҷдәӣеј•з”Ёж•ҙеҗҲеңЁдәҶдёҖиө·пјҢйҖҡиҝҮйҖ»иҫ‘规еҲҷе°ҶжәҗиЎЁжҳ е°„еҲ°зӣ®ж ҮиЎЁпјҢиҖҢдё”иҝҷдёӘиҝҮзЁӢжҳҜеҸҜйҖҶзҡ„пјҢжҲ‘们еҸҜд»Ҙжё…жҘҡзҡ„зҹҘйҒ“зӣ®ж ҮиЎЁзҡ„ж•°жҚ®жҳҜжҖҺд№ҲжқҘзҡ„гҖӮ
жғіиҰҒеӯҰд№ еҘҪ SQL иҜӯиЁҖпјҢе°ұиҰҒеңЁдҪҝз”Ё SELECT иҜӯеҸҘд№ӢеүҚеј„жҮӮе…¶д»–зҡ„иҜӯеҸҘпјҢиҷҪ然 SELECT жҳҜиҜӯжі•з»“жһ„дёӯзҡ„дёӘе…ій”®иҜҚпјҢдҪҶе®ғеә”иҜҘжҳҜжҲ‘们еҗҺдёҖдёӘжҺҢжҸЎзҡ„гҖӮ
10гҖҒ SQL иҜӯеҸҘдёӯзҡ„еҮ дёӘз®ҖеҚ•зҡ„е…ій”®иҜҚпјҡDISTINCT пјҢ UNION пјҢ ORDER BY е’Ң OFFSET
еңЁеӯҰд№ е®ҢеӨҚжқӮзҡ„ SELECT иұ«еү§д№ӢеҗҺпјҢжҲ‘们еҶҚжқҘзңӢзӮ№з®ҖеҚ•зҡ„дёңиҘҝпјҡ
йӣҶеҗҲиҝҗз®—пјҲ DISTINCT е’Ң UNION пјү
жҺ’еәҸиҝҗз®—пјҲ ORDER BYпјҢOFFSETвҖҰFETCHпјү
йӣҶеҗҲиҝҗз®—пјҲ set operationпјүпјҡ
йӣҶеҗҲиҝҗз®—дё»иҰҒж“ҚдҪңеңЁдәҺйӣҶеҗҲдёҠпјҢдәӢе®һдёҠжҢҮзҡ„е°ұжҳҜеҜ№иЎЁзҡ„дёҖз§Қж“ҚдҪңгҖӮд»ҺжҰӮеҝөдёҠжқҘиҜҙпјҢ他们еҫҲеҘҪзҗҶи§Јпјҡ
DISTINCT еңЁжҳ е°„д№ӢеҗҺеҜ№ж•°жҚ®иҝӣиЎҢеҺ»йҮҚ
UNION е°ҶдёӨдёӘеӯҗжҹҘиҜўжӢјжҺҘиө·жқҘ并еҺ»йҮҚ
UNION ALL е°ҶдёӨдёӘеӯҗжҹҘиҜўжӢјжҺҘиө·жқҘдҪҶдёҚеҺ»йҮҚ
EXCEPT е°Ҷ第дәҢдёӘеӯ—жҹҘиҜўдёӯзҡ„з»“жһңд»ҺдёӘеӯҗжҹҘиҜўдёӯеҺ»жҺү
INTERSECT дҝқз•ҷдёӨдёӘеӯҗжҹҘиҜўдёӯйғҪжңүзҡ„з»“жһң并еҺ»йҮҚ
жҺ’еәҸиҝҗз®—пјҲ ordering operationпјүпјҡ
жҺ’еәҸиҝҗз®—и·ҹйҖ»иҫ‘е…ізі»ж— е…ігҖӮиҝҷжҳҜдёҖдёӘ SQL зү№жңүзҡ„еҠҹиғҪгҖӮжҺ’еәҸиҝҗз®—дёҚд»…еңЁ SQL иҜӯеҸҘзҡ„еҗҺпјҢиҖҢдё”еңЁ SQL иҜӯеҸҘиҝҗиЎҢзҡ„иҝҮзЁӢдёӯд№ҹжҳҜеҗҺжү§иЎҢзҡ„гҖӮдҪҝз”Ё ORDER BY е’Ң OFFSETвҖҰFETCH жҳҜдҝқиҜҒж•°жҚ®иғҪеӨҹжҢүз…§йЎәеәҸжҺ’еҲ—зҡ„жңүж•Ҳзҡ„ж–№ејҸгҖӮе…¶д»–жүҖжңүзҡ„жҺ’еәҸж–№ејҸйғҪжңүдёҖе®ҡйҡҸжңәжҖ§пјҢе°Ҫз®Ўе®ғ们еҫ—еҲ°зҡ„жҺ’еәҸз»“жһңжҳҜеҸҜйҮҚзҺ°зҡ„гҖӮ
OFFSETвҖҰSETжҳҜдёҖдёӘжІЎжңүз»ҹдёҖзЎ®е®ҡиҜӯжі•зҡ„иҜӯеҸҘпјҢдёҚеҗҢзҡ„ж•°жҚ®еә“жңүдёҚеҗҢзҡ„иЎЁиҫҫж–№ејҸпјҢеҰӮ MySQL е’Ң PostgreSQL зҡ„ LIMITвҖҰOFFSETгҖҒSQL Server е’Ң Sybase зҡ„ TOPвҖҰSTART AT зӯүгҖӮе…·дҪ“е…ідәҺ OFFSET..FETCH зҡ„дёҚеҗҢиҜӯжі•еҸҜд»ҘеҸӮиҖғиҝҷзҜҮж–Үз«
пјҲhttp://www.jooq.org/doc/3.1/manual/sql-building/sql-statements/select-statement/limit-clause/пјүгҖӮ
и®©жҲ‘们еңЁе·ҘдҪңдёӯе°Ҫжғ…зҡ„дҪҝз”Ё SQLпјҒ
жӯЈеҰӮе…¶д»–иҜӯиЁҖдёҖж ·пјҢжғіиҰҒеӯҰеҘҪ SQL иҜӯиЁҖе°ұиҰҒеӨ§йҮҸзҡ„з»ғд№ гҖӮдёҠйқўзҡ„ 10 дёӘз®ҖеҚ•зҡ„жӯҘйӘӨиғҪеӨҹеё®еҠ©дҪ еҜ№дҪ жҜҸеӨ©жүҖеҶҷзҡ„ SQL иҜӯеҸҘжңүжӣҙеҘҪзҡ„зҗҶи§ЈгҖӮеҸҰдёҖж–№йқўжқҘи®ІпјҢд»Һе№іж—¶еёёи§Ғзҡ„й”ҷиҜҜдёӯд№ҹиғҪз§ҜзҙҜеҲ°еҫҲеӨҡз»ҸйӘҢгҖӮ
