本文是 2022/7/29 在DOIT和华科计算机学院联合举办的2022全球闪存峰会SSD 固态存储技术论坛上的分享内容的文字总结,主要是介绍可计算存储在SSD和数据库领域的创新实践原理,适合数据库运维、研发领域人员。线上分享由于时间有限,有些原理没有多说。这里文章会稍微多说一些。
可计算存储背景
近十年来,数据的产生和使用出现了爆发式的增长,全球的数据规模远远超出存储产能。而随着摩尔定律的失效,CPU性能提升速度也减缓,面对日益增长的海量数据,算力紧张已经是一些客户迫在眉睫的问题。当传统的计算和存储的处理方式很难满足数据增长的需求时,的办法就是通过创新来提升计算和存储的效率。具体做法就是让计算分流。比如说把AI的运算分流到GPU、TPC和FPGA等高效的计算引擎里,把网络相关的繁重运算分流到智能网卡芯片里。在存储领域,SSD的容量和性能都得到很大的提升,给服务器的CPU带来更大的挑战。这时候我们可以把部分“计算”功能下推到存储层面。这就是可计算存储的诞生背景。对于互联网大企业和云厂商而言,可计算存储也是企业存储降本增效的有力方案。

可计算存储的目标就是大幅提升应用及基础设施的附加值。具体亮点有:·提升SSD的可用容量和读写性能,提升单机的存储容量和处理性能。
·降低企业存储的TCO。这个是很多大中型客户的主要诉求。
·使用对上层应用完全透明,不需要应用改造。
可计算存储,英文称呼是Computational Storage Drives,后面简称CSD,本质上也是SSD。只不过是在SSD里引入了一个计算引擎。可计算存储重新定义了存储和计算的软硬件边界。可计算存储究竟如何,在实践时要回答下面几个问题:·CSD 存储设备内的计算能力如何?
·CSD能带来的空间和性能收益多大?
·上层应用跟CSD存储层协同设计复杂度如何?
SSD 使用特点
由于CSD主要场景是数据库,为方便数据库研发和运维人员了解CSD,这里先回顾一下标准的SSD的一些使用特点。这里主要是详细介绍一些设计原理,不会涉及太多硬件电路原理,所以也不会枯燥。
首先SSD跟机械盘不同,存储介质是闪存颗粒(又称NAND 颗粒)。先看看NAND的特性。
NAND 特性
NAND的小管理单位是Page,大小一般是4KB,没有扇区(Sector)概念。NAND跟机械盘扇区一个大的不同就是不支持原地更新。NAND 颗粒的操作主要是三种类型:读(Read)、编程(Program)、擦除(Erase),后两者对应常说的写操作。Program就是写入实际数据,但是只能在一个空的Page上写,所以一个Page被Program一次后就不能做第二次,除非这个Page被Erase为空Page。后面这个操作又叫空间回收。如果同一份数据要修改,SSD的做法是将新数据写到新的Page里。如果应用反复更新同一笔数据,那SSD内部就会不断的写到新Page,并且产生了很多老版本的数据。从应用角度,老版本数据是的,但在SSD内部,还占用着NAND 资源。所以老数据也需要回收机制。有些朋友可能会看出,SSD这个写特点跟LSM Tree的写很像。
SSD的这种更新我们也称为异地更新(out-of-place-update)。但是上层应用(文件系统或数据库)从未感知到这一点,这要归功于SSD架构里一个重要模块:闪存转换层(Flash
Translation Layer,简称FTL)。这个后面再单独介绍。
NAND颗粒第二个特性是Read和Program的小单位是Page,Erase的小单位是Block。这是SSD的硬件设计特性决定的。Page大小一般是4KB,Block由很多Page组成,具体数量每个品牌的NAND可能有些不同,一般大小在几MB左右。由此带来的影响是在时延上,Read时延会小于Program(小一个数量级,10倍以上差异),Program时延小于Erase(大概有几倍的差异)。再引申一点说,NAND的读性能很容易受写影响,尤其是Erase操作。当然在SSD层面,可能会看到写时延比读时延要低,那是因为SSD内有DRAM缓存,SSD的写只要写到内部DRAM缓存就会返回(注:DRAM有电容保护,不用担心SSD掉电丢数据。)。当SSD读写压力很高的时候,后端NAND读写压力也会上去,前面分析的读受写影响的这个结论还是成立的。

NAND颗粒第三个特性是有使用寿命,具体就是Erase的次数有限。如TLC SSD NAND颗粒可反复擦写次数大概几千次,QLC则是几百次。这是NAND颗粒的特性决定的(QLC容量更大),SSD内部的主控模块还会有自己的设计去全局统筹NAND 颗粒的使用,从而大化SSD的使用寿命。其中一个统筹策略就是垃圾回收(Garbage Collection,又称GC),GC 就涉及到块擦除。这个主要是决定回收哪些NAND块。第二个统筹策略是磨损均衡(Wear Leveling,又称WL)。这个主要是将一些热数据块(擦除次数很多)上数据搬迁到一些冷数据块(擦除次数很少)上,以尽可能拉平不同NAND块的使用寿命。GC和WL 都是主控的逻辑,跟FTL也有关系。GC和WL活动会占用NAND里带宽资源,所以对应用的读写活动会有一些负面影响。这就是为什么SSD 使用一段时间进入稳态后性能会下降一些。
FTL
FTL有很多功能,这里分享对其中一个功能的理解。由于SSD 后端NAND颗粒不支持原地更新,只支持异地更新。而以前的文件系统和上层应用习惯了机械盘的原地更新机制。所以FTL就负责起应用IO的目标地址的转换,具体就是Logical Block Address(简称LBA)到Physical Block Address(简称PBA)。当应用更新同一笔数据(同一个LBA地址),后端NAND颗粒的PBA地址会不断变化,FTL会不断更新后端的PBA地址,上层应用就感知不到这个。FTL 在做LBA到PBA的映射时,映射的长度通常也是一样的,即等长映射,是1:1映射。
不过随着SSD技术的发展,上面这些也不是一成不变的。如在可计算存储里,应用IO写入的数据在经SSD主控写入到后端NAND之前会被压缩,所以实际存储空间会比数据原始大小要小很多。也就是LBA到PBA的映射是变长映射,是N:1映射(N>1)。这个变化讲起来简单,却给SSD和上层应用带来很大变化。后面会继续深入的展开。FTL要做的映射对于SSD是必须的,但FTL模块不一定非要在SSD内部,虽然大部分SSD是这么做的,但是大部分SSD也都也为此付出代价,就是SSD的写放大和NAND颗粒寿命问题。NAND颗粒的Erase是以Block为单位,大部分时候Block上可能同时包含有效数据和数据。Erase之前需要将有效数据读出再写入到新的Block里新的Page(这就是数据搬迁),然后才能将整个老的Block擦除,老的Block里所有Page都变成空的状态。有效数据搬迁后,FTL也会更新对应的PBA地址。GC和WL活动都会触发Erase动作,也就是会触发有效数据的搬迁。这个成本会算在写入上。SSD会统计LBA写入的数据量以及后端PBA写入的数据量,后者除以前者就是SSD的写放大指标(Write Amplification Factor,又称WAF)。SSD寿命跟可Erase的次数有关,所以我们通过不同的WAF可以粗略比较寿命的状况(是好还是坏)。实际寿命是通过在SSD生命周期内每天可以全盘写入的次数(Drive
Write Per Day)来衡量的,DWPD的测量计算会用到WAF。近几年流行的ZNS SSD 技术从Open
Channel SSD发展过来,实现将FTL从SSD内部上移到主机端,实现应用自己控制SSD后端NAND的读写,从而大程度的规避SSD的写放大和寿命问题。当然它的代价就是应用软件要重新设计,适合研发实力很强的大型企业。这个产品理念还不错,目前业界还在探索中。这个以后再探讨。
写放大
再聊聊写放大。上面说的写放大,具体是指SSD的写放大,通俗的说实际产生的IO比应用原始的IO数据量的比值。SSD的写放大通常是很高的,在5以上。写放大的负面影响一方面是寿命,另外一方面也就是性能了。因为Erase时延大,且占用NAND内部带宽。
写放大不光是在SSD内部有,在数据库内部也多处存在。比如说BTree数据库,数据库存储都是定长块,有8KB、16KB等等。当应用想修改块内部分数据时,数据库需要读入完整的块,然后在内存中修改,再后面刷写到存储上。如为了修改1个KB 的数据,实际落盘时写了8KB,那这个写放大就是8。这里还没有统计数据库的WAL Logging带来的写。实际上传统关系型数据库多是BTree模型,其写放大都是很厉害的。这些数据库的瓶颈大多是在IO,跟写放大也有点关系。LSM Tree数据库的写放大则小很多。以Rocksdb为例,应用每次写请求都是顺序写,会以追加模式写到数据文件中。每次IO 修改多少数据,实际产生的写IO数据也基本差不多。这就是LSM Tree在写放大方面比BTree 要好很多的地方。所以LSM Tree类数据库产品,都会声称对SSD友好。跑LSM
Tree数据库时,SSD的性能和寿命会更好。当然凡事不会只有好处没有代价。LSM
Tree的追加写模式导致读请求的时候额外IO会很多,为了减少读IO,LSM Tree数据存储会分层存储,每一层会合并下一层相同数据的多次IO。Rocksdb默认分7层,OceanBase默认分三层。同样的数据依然可能会存在写多次。TiDB就对Rocksdb做了个优化,当短时间内写入大量数据时,可以绕过下面几层直接写入到高层,也是为了降低数据库层面的写放大。一般来说,数据库层面降低写放大,SSD层面的写放大也会得到极大的改善。对于传统的BTree类数据库,这个确实会是一个缺点。在学术界也有很多弥补方法。其中一个思路就是在数据库数据落盘之前,使用一块缓存,将BTree的随机写转化为顺序写,也能达到降低SSD写放大的目的。这个需要对数据库改造。
OP 空间
还有一个影响写放大因子的因素就是NAND剩余空间。NAND的更新是异地更新,所以不断的需要新的Page来容纳写入。而老版本数据的回收是有延迟的,这个就让空间利用率看起来很低,容易被用户吐槽。SSD 的解决方案是会保留一定比例的NAND容量不对用户可见,但是应用写入的时候是能用上这部分空间。这部分空间叫Over Provision,简称OP空间。通常OP的比例有 7%和 22% 两种。比如说一个4TB的SSD盘(这里1 TB=109 Byte),通常实际可用容量是 3.84 TB 或 3.2 TB两种。
需要注意的是,实际查看块设备大小,3.84TB 的SSD可用容量显示为 3.5 T。后面这个T严格写应该是 TiB (1 TiB=210 Byte))
通常SSD 也提供了命令取调整实际可用容量,从而间接改为OP空间的比例。一般是往大了调整。更大的OP空间是可以降低写放大因子。其原因是OP空间都是空Page,是可以写入的。OP空间越大,触发Erase的次数就越少。或者GC和WL 活动就可以在低峰期去执行,且数据搬迁的数量也相对要少很多。所以以前如果为了追求SSD读写性能的稳定性(即抖动比例很小,调大SSD
OP空间是一种做法。代价就是牺牲一部分可用容量(因为部分容量转为对应用不可见)。随着SSD技术的发展,这个问题也有两个解决方案。一是在ZNS
SSD里,应用直接读写NAND,直接控制整块Erase,不用SSD做数据搬迁。那么OP空间也就没有意义了。那么SSD可以相对提供更大的可用容量。成本和风险就是主机端应用或者文件系统要自己管理SSD NAND的容量。这里面也会有很多挑战。目前业界也在探索。第二个解决方案就是可计算存储,由于压缩了写入到NAND里的数据量,使得NAND的消耗速度相对标盘下降很多,间接的效果就是剩余空间(包括OP空间)看起来相比标盘要更大一些(总容量大小一样,只是CSD的NAND消耗速度更低,所以有这种错觉)。OP大,读写性能就更低更稳定。
CSD 使用特点
CSD 本质上也是一个SSD,上面说的SSD使用特点也适用于CSD。只不过会有一些变化。CSD的不同之处是在SSD内部引入的计算引擎功能,主要功能包括:压缩和解压缩、加密和解密。这里只说压缩和解压缩,具体会在主控将数据写到后端NAND颗粒之前对要写入的数据进行压缩;反过来读取的时候从NAND颗粒读出的数据再进行解压缩。
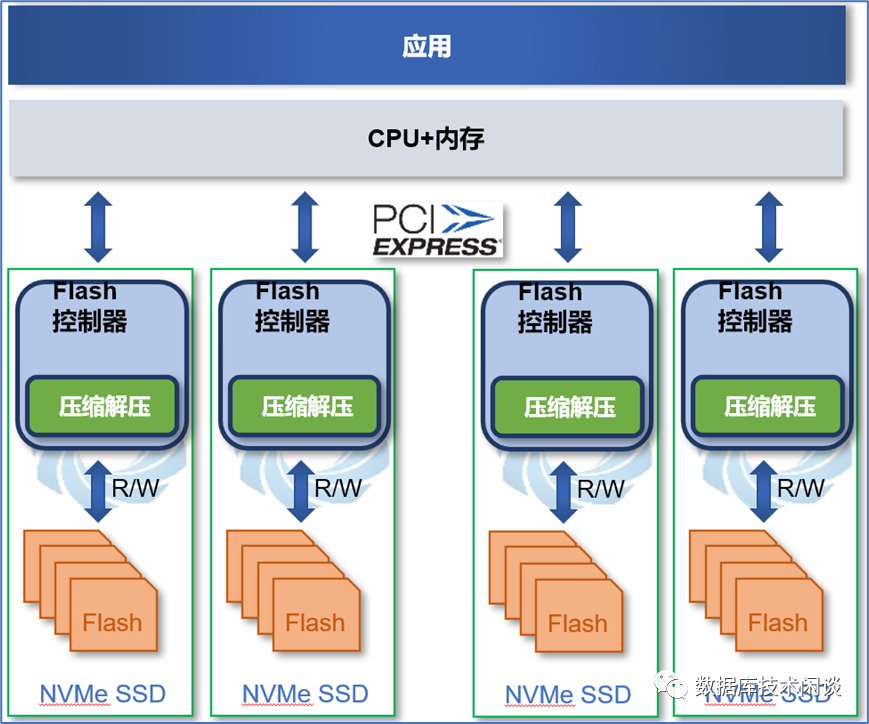
透明压缩
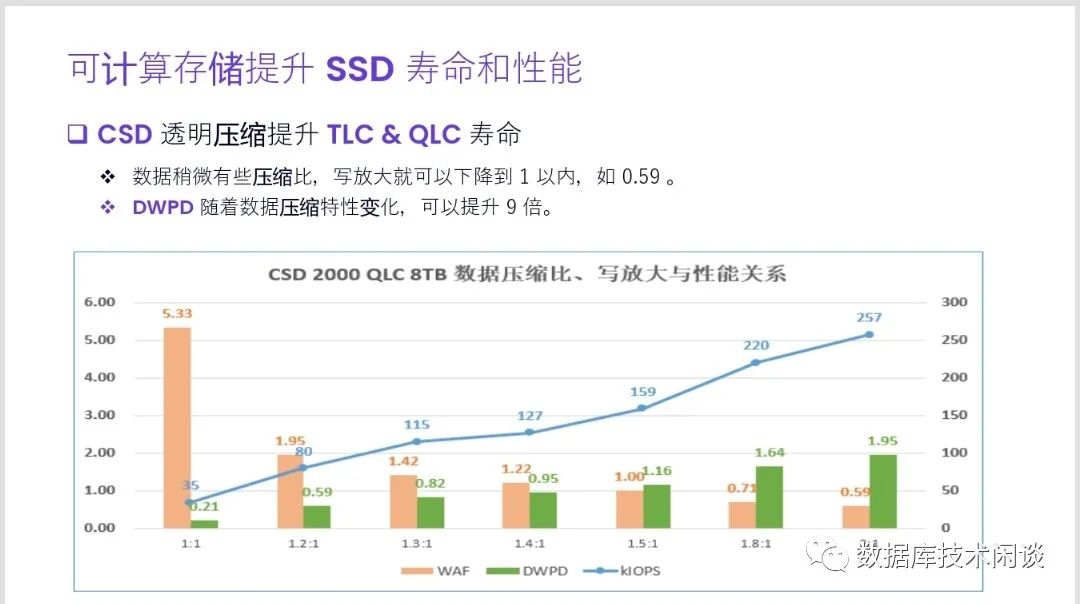
CSD的压缩是在SSD内部的,是实时的压缩。因为对上层应用不可见,所以也可以称为透明压缩。说到压缩,通常容易想到两点。一是压缩能省存储空间,二是数据库或者压缩卡也可以做压缩。这里分别展开描述。
前面在介绍SSD OP空间也介绍了,CSD的容量规格跟标盘一样。如 CSD 2000 TLC有4TB和8TB 两种。4TB 的 CSD格式化后操作系统看到的容量也会是 3.5 TiB。这个代表的是 3.5
TiB的LBA地址容量,在文件系统或者SSD格式化的那一刻就确定了,后期也不会改变。所以CSD的透明压缩时能够压缩存储空间,但不会改变操作系统里看到的盘的总空间和已使用空间。CSD压缩的是后端NAND物理容量,是有效数据占用的PBA地址的容量。PBA地址容量通常对操作系统是不可见的(因为在标盘里 PBA地址容量跟LBA地址容量是等长映射,所以以前都不关注NAND物理容量)。所以,在CSD里,一个100GiB的数据文件,看起来还是100GiB。上层应用看到的存储接口以及返回的数据跟SSD标盘都是一样的(所以称之为透明压缩)。不一样的是在CSD内部,这个数据文件实际占用的NAND空间可能只有20GiB。我们把操作系统里看到的数据文件大小称为逻辑大小,SSD内部NAND占用的容量称为物理大小。逻辑大小跟物理大小的比值就是数据文件的压缩比。在SSD标盘里,所有文件的压缩比都是1,。在CSD里,压缩比一定大于1。有关压缩比的分析后面再展开。CSD内部的物理大小需要单独的命令查看。CSD的物理使用容量、剩余容量也需要命令查看。因为SSD标盘没有这部分,所以这部分命令自然也不是通用的。通常应用也不需要关注数据文件的实际压缩比,或者CSD的实际物理容量使用情况。因为默认情况下NAND的物理容量是不可能用完的,这是SSD标盘的特性决定。但是CSD的透明压缩还带来了一个额外的用法,就是可以超额提供可用容量使用。这是一种扩容的用法,后面再单独介绍。
我们再接着分析透明压缩的另外一个疑问,就是跟应用压缩或者压缩卡(如FPGA)有什么区别。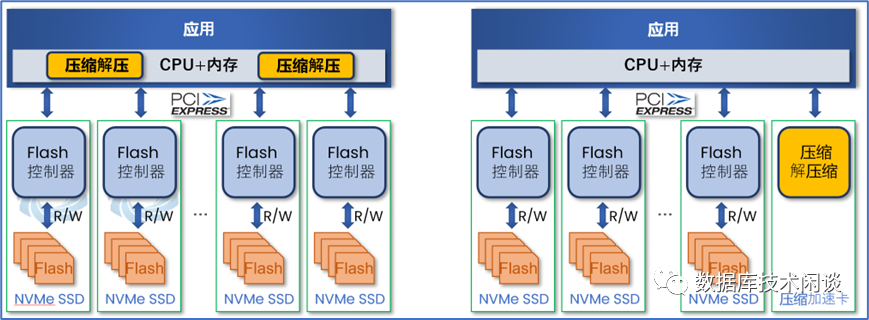
首先是压缩发生的位置。如果是应用自己压缩,需要占用主机的CPU资源。影响的大小取决于压缩算法。应用常用的压缩算法有lz4、snappy、zlib、zstd。Lz4和snappy的压缩比(压缩前大小除以压缩后大小)差不多,zlib和zstd的压缩比差不多,前两者的压缩比又比后两者压缩比小,对CPU的消耗也要小。生产环境传统关系数据库一般不开压缩,怕压缩影响性能。LSM Tree数据库大多开压缩,但是在前面几层也只敢用lz4 压缩,在后面两层才用 zstd算法。因为后面几层的合并时被触发的时间不多,不会对在线交易实时影响。此外还有就是后面几层合并本身就是很影响性能,也就不在乎多占一点CPU资源了。还有一种压缩方案是使用FPGA卡压缩,需要应用修改代码指定。这个不怎么占用主机的CPU资源,不过要额外占用IO带宽。并且加速卡需要额外占用一个PCIe插槽。单个卡的处理能力也是有上限,所以不一定能扩展使用。随着单机存储容量的提升,应用压缩方案和FPGA卡压缩方案可能会面临一个算力瓶颈问题。而CSD的透明压缩能力是以盘为单位的,当数据存储需求增长时,只需要插入更多的CSD即可。此外透明压缩也不额外占用主机的IO带宽等。
关于应用开压缩的原因还有一个推测是以前PCIe 的带宽不高,应用的读IO的带宽很可能受PCIe 限制。如果随着Gen4 服务器的逐步普及,Gen5 也在路上。未来PCIe的带宽将会极大提升。PCIe 4.0 x4 预计7.8GB/s,PCIe 5.0 x8 预计24.6GB/s 。所以从这个角度使用主机CPU去压缩读写IO的带宽不是那么的有必要。不过当PCIe通道带宽不是瓶颈的时候,SSD的吞吐瓶颈可能会在后端NAND读写带宽上。从这个角度来说,对于普通的SSD,应用压缩又有点意义。但是对于CSD,由于后端NAND实际写入带宽会被压缩,所以后端NAND带宽使用率更高,理论上可以让SSD前端实际带宽跑到更高(接近PCIe的限制)。
读写性能
再说说透明压缩对性能的影响。理论上在链路上似乎多了一个压缩和解压缩环节,会增加时延。实际上由于SSD的写入都是写到内部DRAM就返回,此后CSD会批量读取DRAM数据再压缩写到后端NAND。低并发的时候,这个压缩不会直接影响应用的写时延。高并发的时候这个影响还是有一点,不过由于SSD标盘在高并发写入的时候,由于GC和WL的影响,写的时延会变大且不稳定,而CSD却由于透明压缩隐性增大了OP(或者叫剩余空间更合适),减少了GC和WL活动,所以CSD写时延的变化相对SSD标盘而言反而很小,整体时延更低且更稳定。读方面延时本来就很低,加上有一定预取机制,解压缩环节对读性能影响也不大。

图中粗的线条是CSD,细的线条是SSD标盘。随着写比例的增长,读写总的吞吐(IOPS)会出现下降,但是CSD下降的比例比SSD标盘要小很多,相对而言性能就更好更稳定一些。上图还再次说明应用写的比例会影响读写总的性能。
前面多是理论分析,关于CSD的读写性能特点我们来看更多测试数据。CSD奇妙的地方就在于性能还会随着数据压缩特性变化而变化。眼见为实。
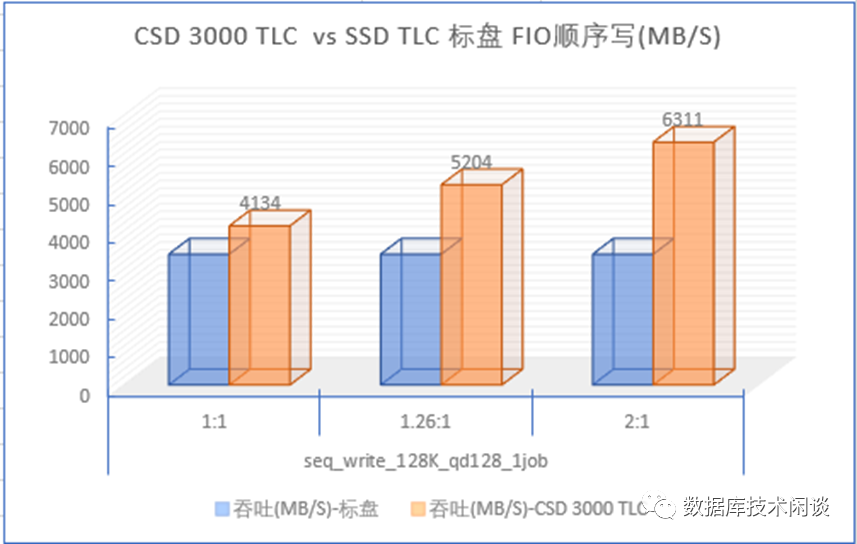
首先看顺序写。图中横坐标是FIO测试数据的压缩比,有三类:不能压缩(压缩比是1:1),可压缩性一般(压缩比1.26:1),可压缩性很好(压缩比 2:1)。蓝色的是SSD标盘的顺序写吞吐,黄色的是CSD 3000 的顺序写吞吐。当数据压缩比为1:1的时候,CSD跟SSD标盘的写吞吐相差不大,但是当数据有一定压缩比后,CSD的写吞吐就有很大提升(增加1-2个GiB)。而SSD标盘对数据压缩比的变化没有一点反应。所以CSD 在数据可压缩的时候写入吞吐是远高于SSD标盘。这个原因主要是CSD后端NAND带宽每个IO实际带宽更低从而整体上能支持更大的前端写入带宽。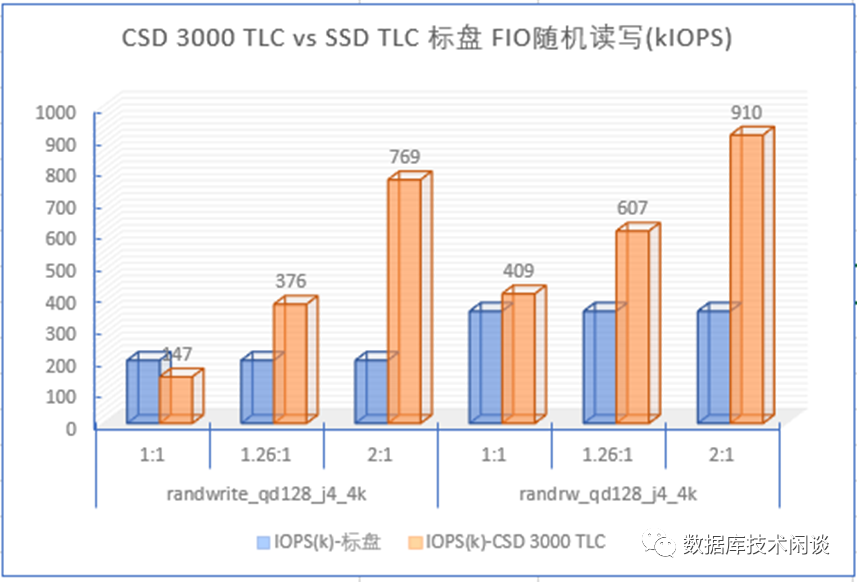
再看随机读和写。左边是随机写,右边是随机读写混合(读:写=7:3)。当数据没有压缩比的时候,CSD随机写IOPS略低于SSD标盘,但是当数据稍微有点压缩比后,CSD随机写的IOPS会提升2-5倍。随机读写也受益于随机写,有1-2倍的提升。这个原因就是前面提到的,CSD有透明压缩,GC和WL更少,对应用读写性能影响更低。在CSD里不需要刻意调大OP空间来保证性能更好更稳定。
CSD的随机读写性能优势在OLTP数据库高并发场景下,也有很大的优势。后面还会详细分析。
容量扩容
前面提到CSD的透明压缩极大的节省了后端NAND物理容量。当数据压缩比在3:1以上时,能节省2/3的NAND容量。有些企业客户会觉得有点浪费,如果能利用这部分容量,哪怕是部分容量,也能换取整体成本的降低。前面介绍FTL的时候提到应用能看到的是CSD 的LBA地址容量。这部分在CSD格式化时就确定了。用户想利用的是后端PBA地址容量,这部分又对用户不可见。如果想用到更大的PBA地址容量,只有一个办法就是将LBA地址容量扩大。
所以,当CSD扩容2倍后原本是3.2TB 可用容量的SSD,实际能存储6.4T的数据。在操作系统里查看这个SSD看到的也是6.4TB的容量。这里需要理解的如果确定数据压缩比是2:1以上,这个CSD就确定理论上能写入6.4TB容量的数据,但是只有等到对盘扩容后,应用才能真的写入6.4TB容量的数据。不扩容,应用依旧只能写入3.2TB容量的数据,跟SSD标盘一样。容量扩容大的好处就是降低数据每GB的成本。通俗一点花相同的价钱可以存储更多的数据,应用也不需要改造。对数据压缩有过思考的朋友可能就会提问,如果CSD扩容后但是数据却不可压缩,那还能写入6.4TB 吗? 答案是不能。极端情况少能写入3.2TB,此后还能写一会,可能写着就会报错。此时CSD后端NAND容量(包括OP空间)已经用尽。理论上当CSD的实际压缩比低于扩容比都有这种风险。所以,CSD扩容使用时,需要先评估业务数据压缩比。然后再设置扩容比。后者要低于前者,以防意外。实际运维的时候还需要监控CSD内部NAND使用空间。CSD也提供了命令用于查看实际的压缩比、剩余物理容量等信息。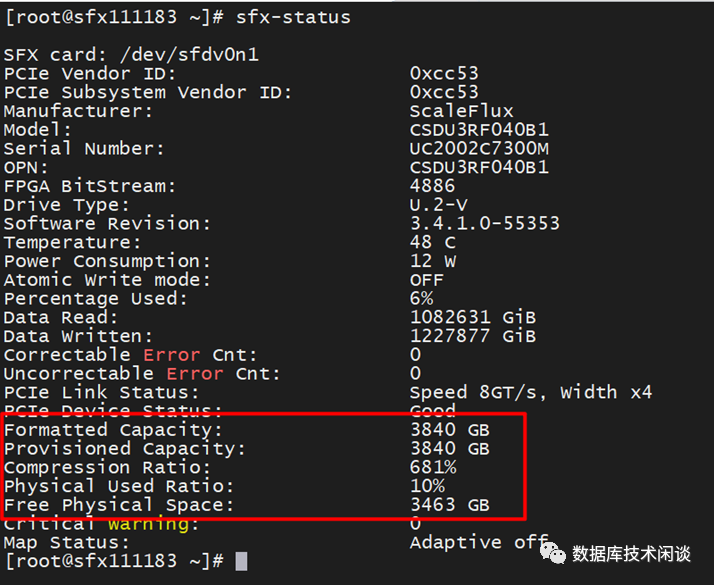
有些用户初次接触CSD对这种物理容量监控不太适应。其实这只是空间管理的一个动作,并不是只有CSD才这样。通常大家习惯的是文件系统管理空间。有些应用如MySQL、TiDB数据库就依赖文件系统去管理空间。而有些数据库如ORACLE、OceanBase却是自己管理空间。那么后者也就需要一个数据库空间的实际使用率的监控。这里更有趣的地方就是当数据库自己管理空间的时候,就喜欢预分配空间、以及复用空间,但是不会如实告诉下面的文件系统这部分空间的实际使用情况。在文件系统看来,所有的数据都是有效的。弊端就是在文件系统层面看数据库这种用法可能会浪费空间。文件系统也同理。当文件系统里删除一个文件后,文件系统也不会马上通知底层存储某一段LBA地址空间数据是的。在存储层面看文件系统这用法,也觉得可能会浪费存储空间。文件系统的设计者考虑到这种情况,提供一个接口用于实时通知。比如说在文件系统mount的时候,增加选项discard。这样文件系统里删除文件的时候,文件系统能够立即发TRIM通知底层存储。当存储是SSD的时候,这个通知还是很有必要的。SSD知道一段LBA地址后就能在后面的GC活动中释放其对应的PBA地址对应的空间,这个对SSD的性能会有提升效果。当然TRIM操作太频繁也会让存储性能下降。有个权衡的过程。CSD的使用都建议mount带discard选项。相比读写文件,删除文件的操作还是很少的。只有在类似Rocksdb这类LSM Tree数据库里,高并发写入的时候,频繁的合并会导致频繁的删除小文件。除了mount时带上discard选项方法外,也可以主动用命令 fstrim 来释放一个目录里被删除的文件空间。
数据压缩比
后再来聊一下数据压缩比。前面提到CSD透明压缩能提升随机读写性能、对容量扩容。其前提都是书具有很好的压缩比。那么真实的业务数据压缩比到底多少呢。这里先说一下CSD使用的压缩算法是zlib(近似level 6)。CSD3000相比CSD2000的压缩比还会高一些,取决于数据自身压缩特性。Sysbench 在mysql里生成的随机数据,在MySQL数据库里同时MySQL数据目录在CSD2000上时,这份数据压缩比大概是 1.9左右。同样方法生成的数据,据我们测算在PostgreSQL里压缩比会比在MySQL里还要高一些。测试数据还不够有说服力,再看客户生产业务数据压缩比。

不同行业的数据压缩比还不一样,低的也有2.4;高的有4.13 。结合很多客户OLTP业务数据库在CSD 2000 上的压缩比看,我们相信客户的业务数据压缩比大于2的概率非常高。当然图片、视频类文件的压缩比估计就没有这么高了。
另外一方面,如果数据库使用了lz4压缩的话,在CSD
2000上还可能有1.56左右的压缩比。如果数据库使用了zstd压缩,在CSD 2000 上的压缩比可能就1.1不到。评估传统数据库如MySQL、PostgreSQL的数据压缩比会相对容易一些,评估ORACLE数据库的压缩比会稍微麻烦一些,因为它的表空间设计使得存储拿不到真实的数据空间使用情况。评估Rocksdb/TiDB数据库压缩比会更复杂一些,因为它的数据是分层存储(多7层),0和1层不开压缩,2,3,4层默认使用lz4压缩,5,6层使用zstd压缩。所以整体的数据压缩比取决于不同层数据量的比例。其数据库自身大小也在不断合并过程中大起大落。难评估数据压缩比的是OceanBase数据库,因为它既自己管理空间又对数据存储分层压缩(多3层)(详情参考《OB 空间分配分析》)。
后再总结一下数据压缩比的经验。数据压缩比高的时候,对读写性能、容量扩容都有很好的加成作用。数据压缩比不高的时候,对性能提升不大,但是对SSD的写放大抑制、寿命提升还是有很明显的作用。在容量更大成本更低的QLC SSD里,性能和寿命正是短板,CSD跟QLC技术结合,正好弥补了这个缺陷。介绍完了CSD对SSD使用特点的改变,后面再继续介绍CSD对数据库使用特点的改变。考虑到篇幅很大了,留到下篇分享。