FAST2020这周在美帝召开,主办单位也时间将Full Proceedings PDFs分享出来,当然不能闲着,抓紧时间大概浏览了下,挑几篇自己感兴趣且看得懂的在这里分享给大家(题外话,今年Alibaba填了些坑),4篇文章的内容概述:
- (1)An Empirical Guide to the Behavior and Use of Scalable Persistent Memor 新硬件:介绍关于Intel Optane Persistent Memory性能特点和Best Practices
- (2)MAPX: Controlled Data Migration in the Expansion of Decentralized Object-Based Storage Systems 数据分布:优化Ceph crush分配算法保证扩容的数据迁移可控
- (3)HotRing: A Hotspot-Aware In-Memory Key-Value Store In-memory key-value:优化基于hash的In-memory key-value stores的 hotspot data访问
- (4)Strong and Efficient Consistency with Consistency-Aware Durability (Best paper) 一致性协议:设计了一种实现cross-client monotonic reads的协议
(一)、An Empirical Guide to the Behavior and Use of Scalable Persistent Memory
过去数十年,学术界对非易失性内存DIMM有大量的研究,但是在这期间,并没有真的DIMM设备,大家都是采用一些emulation techniques,基于对DIMM的特性,仿真出来的;有的通过软件模拟,有的直接通过对DRAM做限速来仿真,等等。但是随着Intel 3D XPoint技术的成熟,Intel正式发布非易失性内存商业产品Intel’s Optane DC Persistent Memory。不幸的是,现实的DIMM设备和过去模拟的设备似乎在各种性能特性上相差很大。基于错误前提,得出来的结论自然也会存在偏差。所以这篇文章基于Intel Optane设备做了大量的测试,详细分析了基于Intel 3D Xpoint技术的Optane设备在各种场景下的性能特点,并总结了关于Optane的Best Practices供大家参考;如果你正准备尝试Optane设备的测试,那么非常推荐你阅读,想必会有所帮助。这里简单描述文章给出的四条Best pracitices:
- (1)Avoid random accesses smaller than < 256 B
或许你还不知道(不才,鄙人今天才知道的 :( ),对于具有byte-address能力的Intel Optane DC PM设备,其小物理介质更新单元是256B,所以,对于较小的request,将会采用read-modify-write技术来更新,会存在一定的放大,那么大量的小request,自然会影响整个3D Xpoint的有效带宽。
- (2)Use non-temporal stores when possible for large transfers, and control of cache evictions.
为了便于解释,首先介绍下intel cpu给PM设备编程提供了多种控制store order的指令,分别是:
- cflush(Cache Line Flush):能将Cache line刷到main memory中
- cflushopt(Optimized CLFLUSH):对cflush的优化,可以实现并发的对不同的Cache Line做flush
- clwb( cache line write back):它和cflushopt类似,只会将Cache Line flush到main memory之后,Cache Line中的仍会保存
- ntstore( non-temporal store):绕过缓存,直接写入main memory
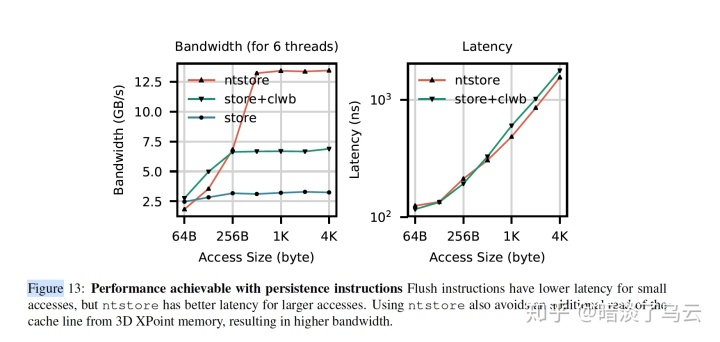
一般还需要结合sfence(store屏障)来保证写入main memory的顺序。所谓的non-temporal store,就是上文中提到的ntstore指令。对于大写来说,直接绕过缓存性能是更好的。如下图,不难发现ntstore在大写的情况下,带宽明显有优势,且没有损失latency。
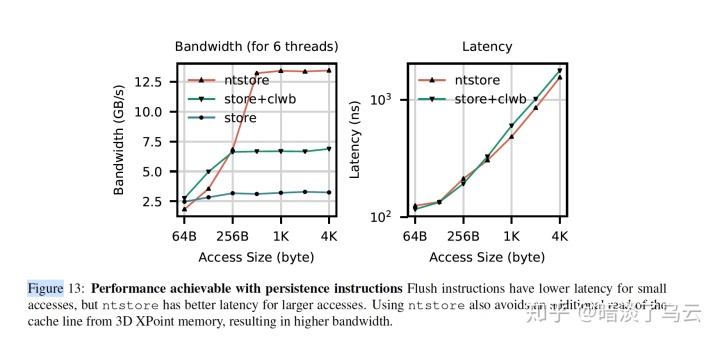

此外,sfence对ststore指令的影响也小,如下图。

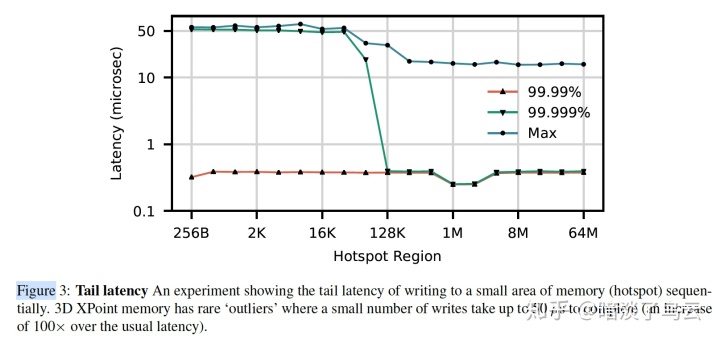
- (3)Limit the number of concurrent threads accessing a 3D XPoint DIMM
需要尽量控制对单个DIMM设备的并发访问,因为可能会造成两个方面的竞争:
(a):Contention in the XPBuffer
如下图,在对hotspot region访问的时候,会由于对XPBuffer的竞争造成长尾。
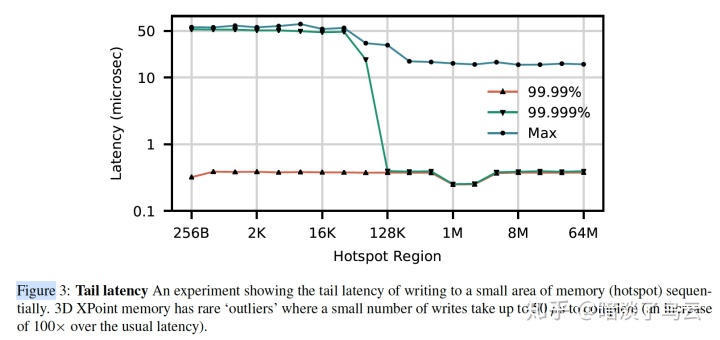

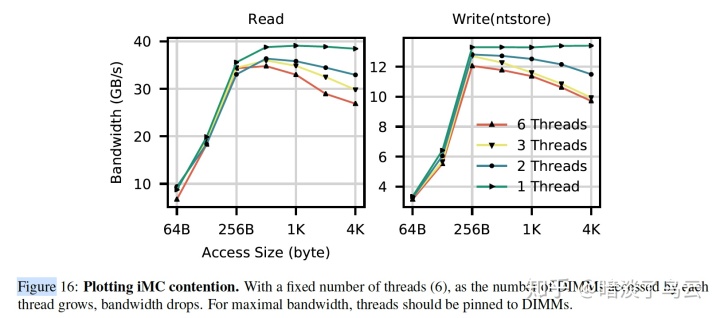
(b)Contention in the iMC(integrate memory controller)
如下图展示了随着线程的变多,bw反而有下降的趋势。
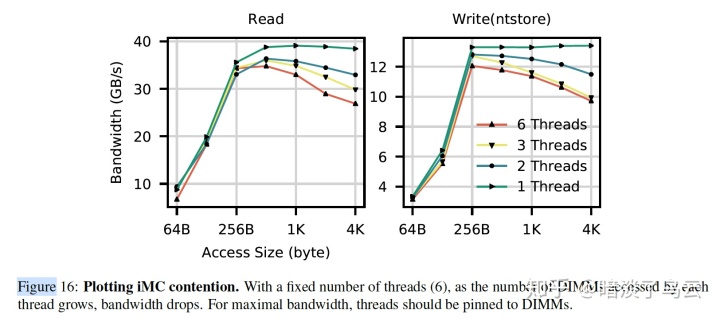

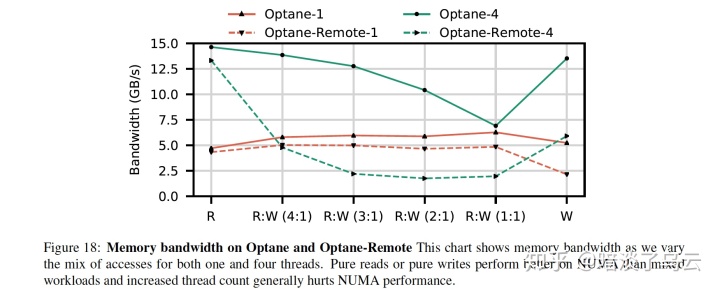
- (4)Avoid mixed or multi-threaded accesses to remote NUMA nodes
相比DRAM,3D Xpoint跨NUMA节点访问性能下降非常明显:
For writes, remote 3D XPoint memory’s latency is 2.53 (ntstore) and 1.68 higher compared to local. For bandwidth, remote 3D XPoint can achieve 59.2% and 61.7% of local read and write bandwidth at optimal thread count

如上图,显示了不同rw-mixed情况下,访问local和remote node的bw差异。更多的数据和分析可以参考原文或者我的博文:An Empirical Guide to the Behavior and Use of Scalable Persistent Memory
(二)、MAPX: Controlled Data Migration in the Expansion of Decentralized Object-Based Storage Systems
Data placement主要分两个方向,(1)中心化,例如hdfs,gfs等基于中心化meta进行分;(2)去中心化,例如Ceph crush等,其数据的位置信息是通过计算获取的,Ceph crush通过升级版的一致性hash算法,使得副本放置可以实现故障域隔离。MAPX这篇文章主要就是优化Ceph crush,其基本的motivation就是ceph crush存在如下毛病:
- uncontrolled data migration when expanding the clusters which will cause significant performance degradation
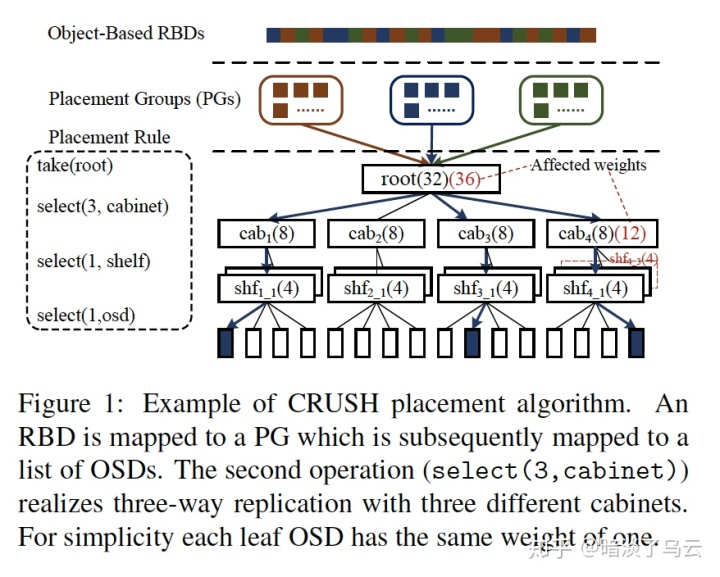
我们都知道,在集群扩容缩容的时候,都会存在一定的数据迁移,关键是如何控制迁移的量和速度,保证数据副本的可靠性并且不影响当前的性能。为了描述ceph crush的问题,这里简单介绍下crush算法,在ceph中,任何东西都会被拆成一个一个object,大小默认是4MB,并且有一个的object id,然后为了便于object管理,又会有object到PG的映射,一个PG相当于一个Replicate Group,一般PG的数量是集群创建的时候设置好的,假设是N个PG,那么object's PG id = hash(object id) % N,data placement就是要将PG放置到物理盘上,Ceph中一块盘一个OSD,并且会通过logical cluster map来描述集群的物理拓扑结构,方便描述故障域,如下图,就是一个cluster map,其中root是根节点,下面4个cab,可以理解为rack,rack下面是shf,可以理解为物理机,shf下面就是osd,也就是物理盘。


一个PG的placement一般分为3步:
- take(root):找到一个cluster
- select(3, cabinet):找到3个满足故障域的rack,因为3个副本,一个副本一个rack
- select(1, shelf):从cab中找到一个shelf,
- select(1, osd):从shf中找到一个osd
上面的步骤是依次递归执行的,每次select都是根据对各item的weight通过随机算法抽签得到的,为了便于介绍,这里以从shf中选osd为例子,也就是shf select(1, osd):
假设shf有3个OSD,每个OSD有一个weight,用wi表示,代表osdi的weight值,PG如何选择一个OSD放置?
其处理过程如下:
- 每个osd,带入osd id和pg id
crush_hash(osd id, pg id)计算得到一个随机值r,ri表示osdi计算得到的随机值r - 用公式
ri * wi计算出osdi的straw值,strawi表示osdi的straw值 - 然后取straw值大的osd放置pg
通过wi和随机值ri可以实现按照那OSD上的PG数量大致按照如下比例来分布。
w1:w2:w3
数据分布均衡性解决了,那如何实现扩缩容对迁移尽量少的数据呢?以扩容为例,假设增加一个OSD 4,且此OSD的weight值是w4,这个时候,OSD1,OSD2,OSD3之间的关系没有变,所有他们之间没有数据迁移,因为任何一个PG从新计算之后,其strawi值都和以前是一样的,假设之前某个PG计算出来straw值分别为:straw1,straw2,straw3,那么增加osd4之后计算,仍然是straw1,straw2,straw3,因此这个计算值只跟osd id,pg id和weight值有关,而这几个值是不变的,一种情况就是straw4 > max(straw1, straw2, straw3),这种情况需要将pg数据迁移到osd4上。但由于上面的均衡性分析可知,终osd上面的pg数量会成如下比例:
w1:w2:w3:w4那么会有w4/(w1+w2+w3+w4)的PG移动到osd4上面。这里是从osd这一层来看,实际上由于shf增加了OSD4,那么此shf的weight也会增加w4,那么从shf这一层来看,也将会有w4/(w + w4)的PG迁移到此shf来(w为此rack系下原先所有shf的weigh的总和),同理,对于cab层,也有是如此,承载新增OSD4的cab的weght值也增加了w4,所以也会有w4/(w+w4)的PG从其他cab迁移过来(w为所有cap原先总的weight值)。更多关于一致性hash和ceph crush算法可以参考之前的一篇博文:从一致性hash到ceph crush
不难发现Crush的数据迁移单层看,尽管是优的,但是在全局来看,集群的logical结构层次越多,对应的迁移数据也将成倍的增加。
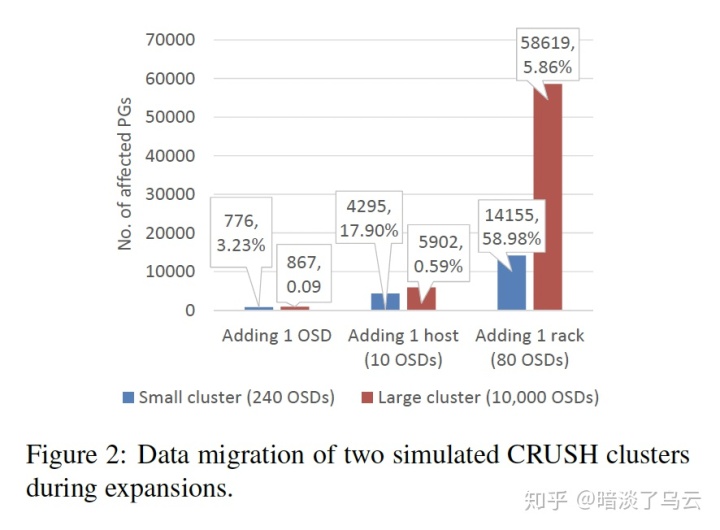
如上图是大小集群上扩容的时候影响到PG的数量的一个统计,其中在小集群的情况下,adding 1 rack将影响到将近60%的PG。
MAPX主要就是要解决扩容中数据迁移不可控的问题,那它是怎么做呢?
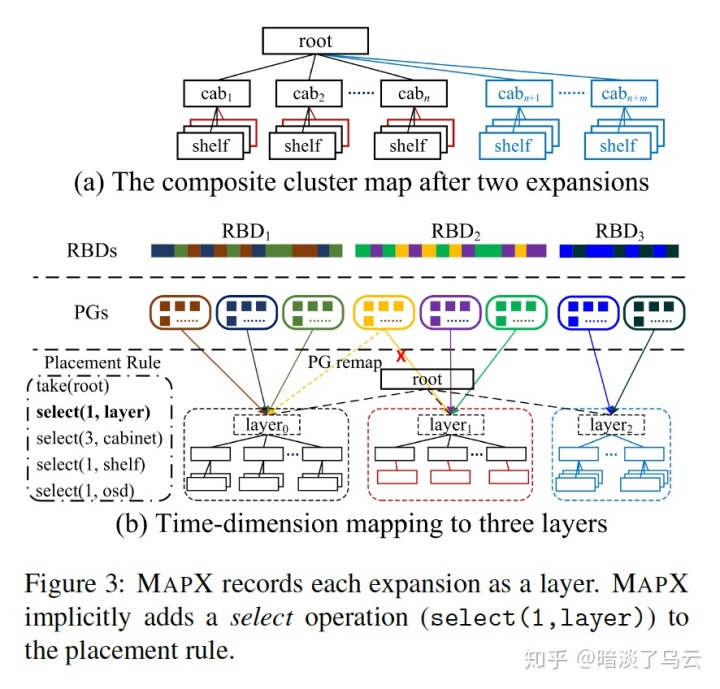
首先限定你的扩容方式,通常的扩容方式如上图(a),一种是如红色在cab里面增加shf,或者是如蓝色部分增加多个cab;但是对于MAPX来说,只能使用上图(b),也就是每次扩容都是新增一个new layer,而且这个new layer,必须按照整个层次结构分布,为了避免扩容的迁移,会为每次新增的new layer创建一批PG,且PG会有一个时间戳属性static timestamp,用tpgs表示,它等于扩容的时间tl,且所有object创建时间t0>tl的只能映射到新创建的PG上。显然这样的方法有还有一些问题:
- 这样做有一个明显的问题就是,如果新增的layer不满足故障域隔离怎么办 ?如上图(a)蓝色扩容,如果只增加了两个cap,那么只能选出PG的2个副本位置,第三个会选择失败;MAPX会select失败的从原先的root去继续选;
- 如果由于删除等原因,出现数据imbalance怎么办 ?MAPX给出了一个PG remapping方案,为此增加了一个adynamic timestamp (tpgd),它可以设置为任意一次扩容layer的扩容时间戳,和object到PG映射使用tpgs不同,PG到layer的映射则是根据PG的tpgd,其映射必须和layer的创建时间一致。同理缩容(Cluster shrinking)和集群合并(Layer merging)都可以通过类似的方法实现。
MAPX通过两个时间戳来控制数据分布和PG的迁移,但是感觉这里难点是如何做PG remapping来保持PG在集群的均匀分布,但是文章并没有描述;除此之外,new data放到new layer PG上,或许是不会有数据迁移,但是数据热点的问题如何解决呢?
其实对于ceph crush来说,其实是大规模的扩容带来的数据迁移会很大,如果能够合理的做好集群规划,那么每次按照cluster/pool级别来扩容,那么自然也不会有大量数据迁移。而一些简单坏盘等交给crush本身,做好流控,理论上也应该是可控的。
(三)、HotRing: A Hotspot-Aware In-Memory Key-Value Store
In-memory key-value stores是一个很火的问题,应用场景也非常广泛,通常会用作cache,那么首要面对的问题就是hotspot数据访问,很多场景可能是90%的访问都是10%的数据。hash作为In-memory key-value中应用为广泛的数据结构,确存在一些问题:
- (1)不能充分利用CPU Cache
如下图,以链式hash冲突解决方案为例,通常其冲突的item会形成一个collision chains,那么如果hot item在collision chains的尾巴,那么需要访问多次才能访问,而CPU cache通常比较小(例如32MB),尾部的hot item访问将大大降低性能

- (2)rehash可以解决上面的问题,但是rehash会大大增大内存的使用量
如果有热点,首先想到的是在增加一层Cache来缓存hotpot数据,并将数据放在更快的存储介质上,但是现在,In-memory key-value stores已经在内存里面了,CPU Cache也只有几十MB的大小,而且不受控;而且考虑到hotspot shift,想想似乎在加一层能够自动识别Hotspot的cache是不可能 ?
这也是本文HotRing巧妙之处,简单的说,就是HotRing通过特殊的设计可以自动识别出hotitem,并且将其放在collision chains的head,从而大大提升了访问hotspot data的性能。

其做法非常巧妙,其将原本的是单链表的collision chains替换成了,双向链表的一个环(ring),如上图,这样有一个非常大的好处,可以快速移动head到collision chains任意一个item,且不影响整个collision chains数据的访问,这样就可以实现简单快速的将head指向collision chains的hotspot item。那如何识别出hotspot item呢?这里介绍一种Random Movement Strategy,每个线程维护一个thread local的计数器,每当处理R个request后,会判断当前的访问的item是不是在collision chains head上,如果在,那么不做任何处理,如果不在,那么让head指向当前访问的item,也就相当于当前命中的item转变成了hotspot item。当然还有效果更好的但也更复杂的strategy:Statistical Sampling,以及更多为了提升Concurrent Access而做的lock-free设计,这里就不展开介绍,感兴趣的可以详细阅读论文获取。
(四)、Strong and Efficient Consistency with Consistency-Aware Durability
这篇文章介绍了一种实现cross-client monotonic reads consistency方案,尽管是一种强的consistency,但是在吞吐和latency上有很不凡的表现,而且支持从大多数的副本read,非常有利于多数据中心部署。
- 那什么是 cross-client monotonic reads ?
Cross-client monotonic reads guarantees that a read from a client will return a state that is at least as up-to-date as the state returned to a previous read from any client, irrespective of failures and across sessions.
注意和linearizable的区别,其不保证never see stale data。
- 如何实现呢 ?
大家应该都对linearizable比较了解,例如raft、paxos等一致性协议都是线性一致性,一般为了保证数据的可靠性和read的一致性,通过request发送给leader,且在返回给用户之前都是在大多数副本上持久化成功,且read都只能发送给leader处理。linearizable是一种很强的一致性,也因此性能上会稍微查一些。而对于cross-client monotonic reads的实现就可以不用实时的落盘,其基本的思路就是把durability延迟到read返回时才做(通常实现可以在后台开启定期flush的线程,read返回前会确认是否已经刷盘,如果没有刷盘了再返回)
(1)整体结构
还是leader-based系统,write发送给leader,read可以发送给follower
(2)Write
write请求发送给leader,leader更新eopch和index信息,并将其发送给follower,都不需要持久化,当大多数返回之后,就可以返回client端了。leader和follower都定期的持久化,为了描述持久化的进度,leader和follower都会维护一个persisted-index,表示自己当前持久化的进度;而leader还要额外维护一个durable-index,表示大多数副本都持久化的进度。leader并且会通过heartbeat将durable-index同步给follower。
(3)Read
发送给leader和follower处理方式不一样:
Leader:假设read item i,且后一个update的item i的index为update-index,那么如果update-index小于等于durable-index,那么可以直接read返回;反之则需要通过follower们落盘,推荐durable-index,直到update-index小于等于durable-index之后再返回
Follower:如果update-index小于等于durable-index,那么直接返回;否则redirect给leader。
(4)Scalable Reads with Active Set
细心的读者可能已经发送了刚才从follower read是有问题的,例如一个被网络分区的follower。那么该如和解决Follower read的问题呢 ?
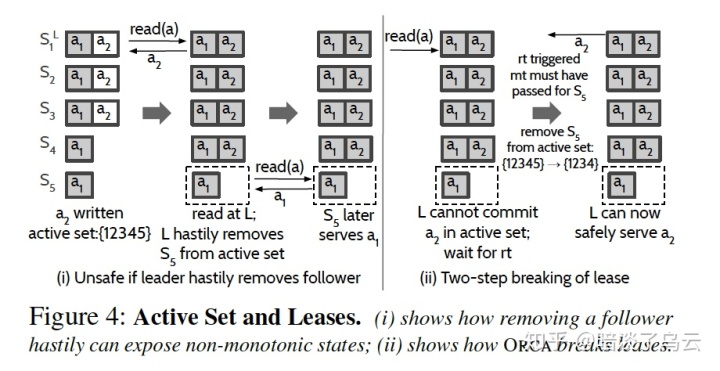
为了解决这个问题,作者引入了Active Set和lease;read可以从active set上的任意副本read,而且leader每次必须再返回read之前保证所有的active set的成员都持久化了。那如何维护active set成员呢?,follower是否在active set中是通过lease来维护的,为了更好的说明,举例来说:如上图(i),假设刚开始active set是S1、S2、S3、S4、S5,接着write a2,然后来read(a),此时S5网络分区了,要返回a2:(a)要么将a2持久化到当前S1、S2、S3、S4、S5上;(b)显然S5已经网络分区,那么在返回read a之前,必须等到S5 lease timeout,此时,active set就变成了S1、S2、S3、S4,也就是上图(ii)。
- 有什么问题呢 ?
(1)因为数据没有落盘,所以再所有节点宕机的情况下,会有data loss的可能。
(2)这种cross-client monotonic reads的应用场景有待思考,尽管论文中给出了几种方式,但是觉得还是比较不实用。
虽然存在一些问题,但是对于follower read的处理,思路还是比较新颖的,当然这种方法受限lease的缺点,但可能在某些场景中可以借鉴和使用。FAST上还有一篇关于一致性协议的,描述的是将Raft应用到Erasure-coding的复制,感兴趣的可以看看 CRaft: An Erasure-coding-supported Version of Raft for Reducing Storage Cost and Network Cost。
Notes
限于作者水平,难免在理解和描述上有疏漏或者错误的地方,欢迎共同交流;部分参考已经在正文和参考文献列表中注明,但仍有可能有疏漏的地方,有任何侵权或者不明确的地方,欢迎指出,必定及时更正或者删除;文章供于学习交流,转载注明出处
参考文献
[1]. Persistent Memory Programming. "https://www.usenix.org/system/files/login/articles/login_summer17_07_rudoff.pdf"
