0.前言
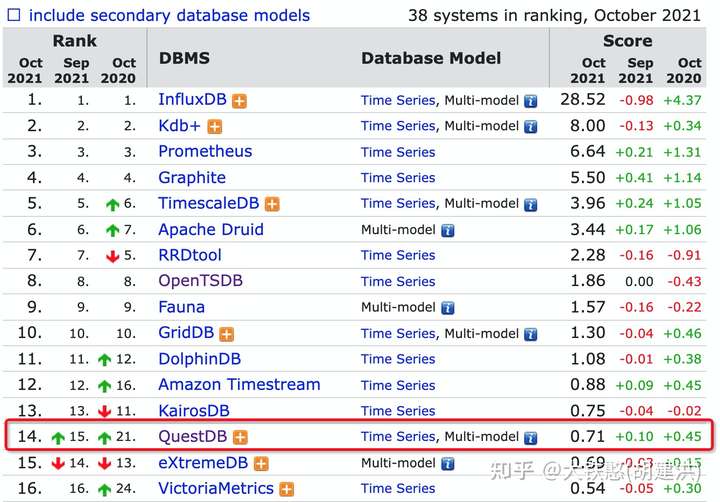
QuestDB是在2014年开源的一个面向列的关系型时序数据库,专为时间序列和事件数据而设计。开发语言为Java和C++, 外部依赖较少,源码仓库地址为:https://github.com/questdb/questdb。QuestDB在db-engines 上的排名目前在慢慢上升,目前(2021年10月)的排名为14,如下所示。本文结合QuestDB v6.0.9的源码和相关资料对QuestDB的存储机制进行浅析, 如有不对的地方,欢迎批评指正。
1.整体架构
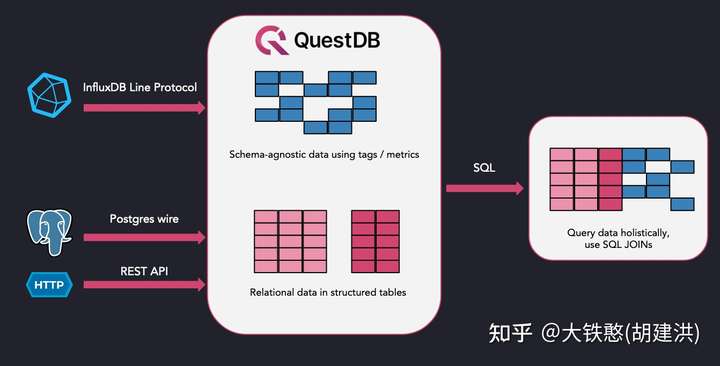
QuestDB 是一个高性能、开源的 SQL 数据库,适用于金融服务、物联网、机器学习 、DevOps 和可观测性应用,整体架构如下图所示。目前QuestDB是一个单机的基于本地磁盘的数据库,支持使用InfluxDB 行协议、PostgreSQL协议以及用于查询、批量导入和导出的 REST API。另外, QuestDB使用带有时间序列扩展的 SQL来协助实时分析, 易用性非常高。QuestDB采用的是面向列的存储模型,专为时间序列和事件数据而设计, 从存储模型上对于分析查询非常友好。
2.上手体验
这里为提高效率,直接使用QuestDB提供的docker镜像运行QuestDB实例,只需运行如下命令即可将QuestDB运行起来。其中,9000端口对应REST API,9009端口对应InfluxDB的行协议,8812端口对应Postgres协议。
docker run -d -p 9000:9000 -p 9009:9009 -p 8812:8812 questdb/questdb
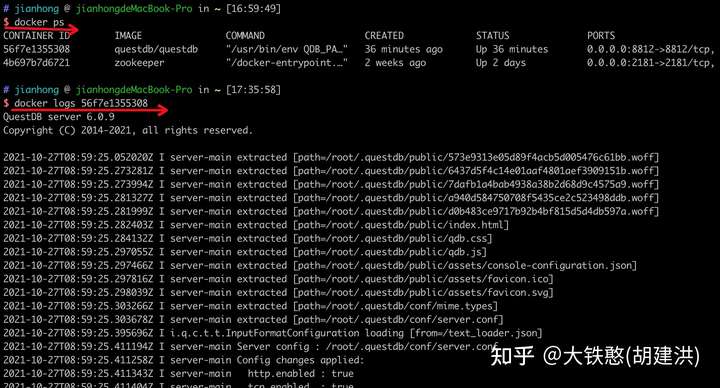
结合docker ps和docker logs,即可看到QuestDB的启动日志,如下所示。
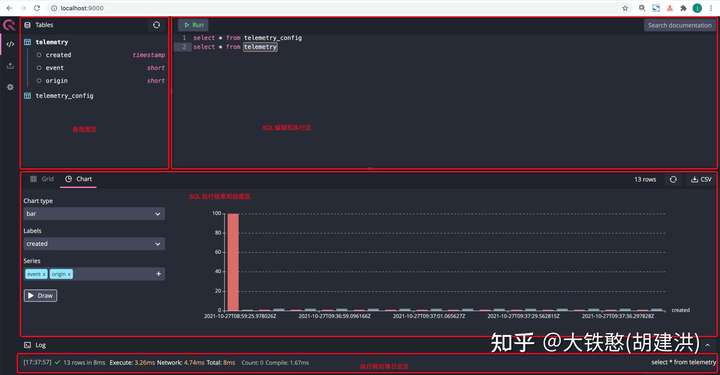
QuestDB提供给了可视化的UI,通过http://localhost:9000/即可访问,如下图所示,包含表视图区,SQL输入和执行区,绘图区等部分。QuestDB默认创建了telemetry和telemetry_config两张表。
对于InfluxDB行协议的支持,QuestDB使用的是TCP协议进行数据传输的,而非InfluxDB使用的HTTP协议。下面是采用netcat工具进行数据写入的示例,共计写入了4条数据,其中1条数据是重复的。QuestDB会自动创建InfluxDB行协议中写入的table,并自动推导数据类型。
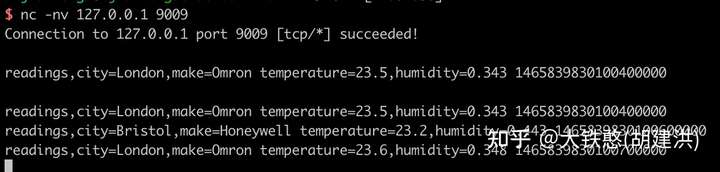
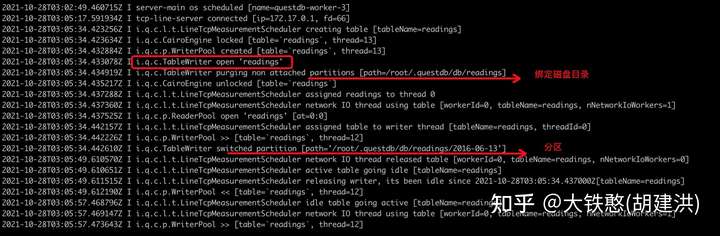
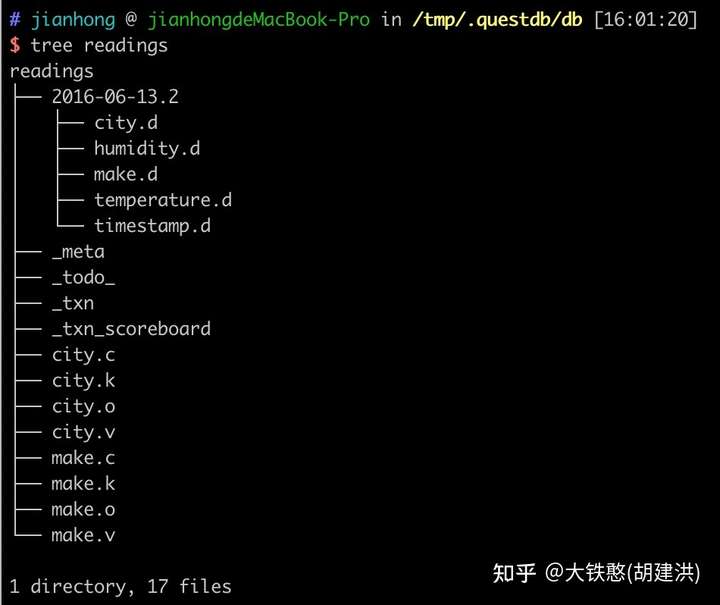
从QuestDB的运行日志中,我们可以看出,QuestDB为新写入的readings表打开了一个新的TableWriter,并使用表名作为表数据的根目录,并且根据时间戳创建了分区目录。
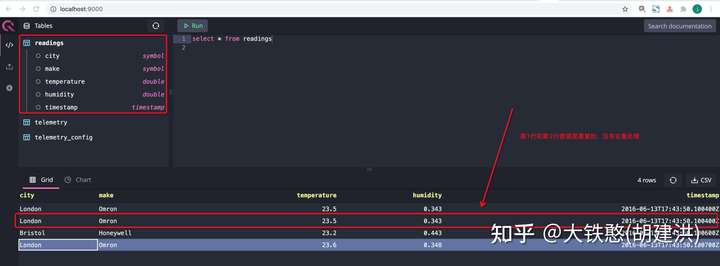
写入数据后,就可以在QuestDB的WebUI上看到刚刚写入的readings表,并且可以查询到数据,如下所示。从查询结果中,可以看出QuestDB应该是Append的方式写入的数据,没有对写入的数据进行去重处理。
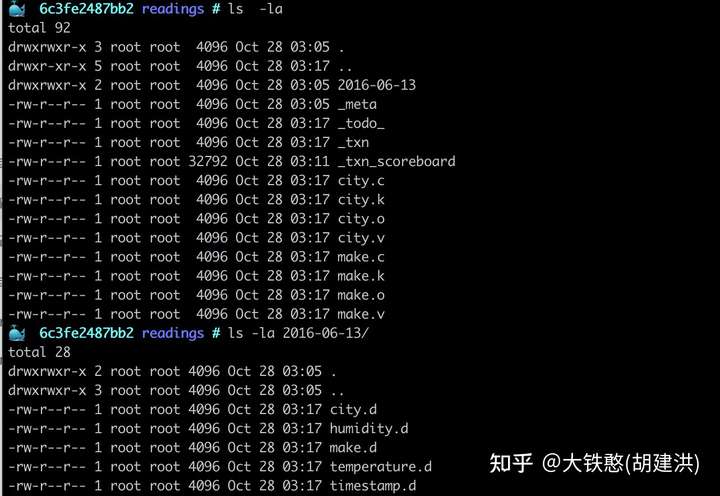
进入docker容器后,切换到/root/.questdb/db/readings目录下, 就可以看到QuestDB关于表的磁盘目录布局情况,如下所示。
另外,需要注意的是,QuestDB提供了一个带有时间序列扩展的 SQL实现,使得数据的读写变得简单,易于上手,这里就不再赘述了,详情参考官网SQL文档:https://questdb.io/docs/introduction/#sql
3.存储机制
QuestDB采用的是面向列的存储格式,每列各自存储在单独文件中,数据基于时间进行分区存储。数据写入方式采用的是内存映射文件(mmap)的追加方法,即新写入的数据佳在列文件的末尾。对于数据文件,QuestDB采用一写多读的方式读写文件,提供了多个不同类型的reader实现。 另外QuestDB支持通过事务文件(tx file)原子地应用表更新来确保表级隔离和一致性, 保证未提交的数据不会在查询结果中显示。
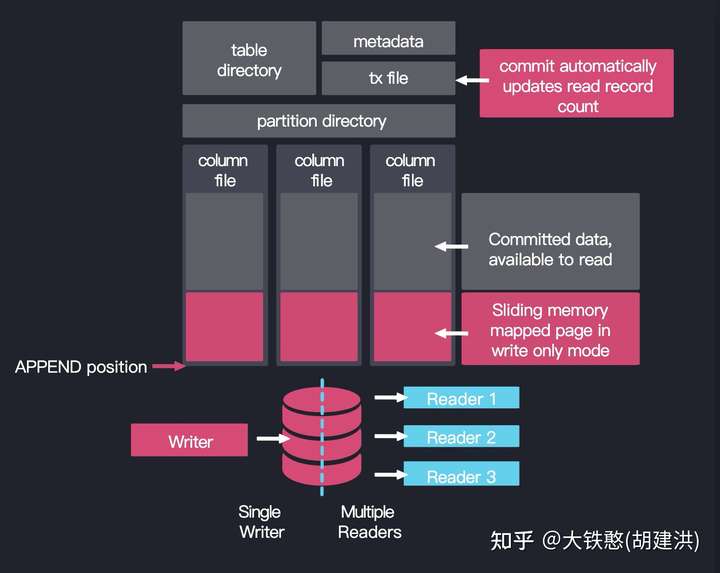
3.1 磁盘目录
3.1.1 根目录
QuestDB的磁盘根目录下有配置文件目录conf、数据目录db、WebUI资源目录public、日志目log录等4个目录。

3.1.2 conf目录
conf目录下主要包含date.formats、mine.*、server.conf等3个文件。其中,date.formats是文本格式的日期格式列表;mime.*是HTTP服务器在用户下载文件时,映射对应文件的响应类型列表;server.conf服务器的配置文件。

3.1.3 db目录
该目录包含与数据库表相关的所有文件,它的组织如下:
- 每张表在根目录下都有自己的表目录table_directory, 即root_directory/db/table_name
- 在表目录table_directory下,每个分区都有自己的分区目录partition_directory
- 在分区目录partition directory中,每一列都有自己的列文件column_file,例如mycolumn.d
- 如果给定的列有一个索引,那么也会有一个index_file,例如mycolumn.k和mycolumb.v
另外,表还将元数据存储在_meta文件中。设置了分区的表磁盘目录结构如下所示。

如果表未分区,则数据存储在名为default的目录下,如下所示。
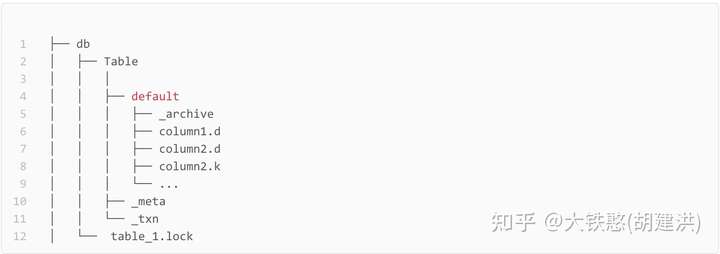
当使用InfluxDB行协议写入"readings,city=London,make=Omron temperature=23.5,humidity=0.343 1465839830100400000"后,表目录readings下的文件布局如下所示。
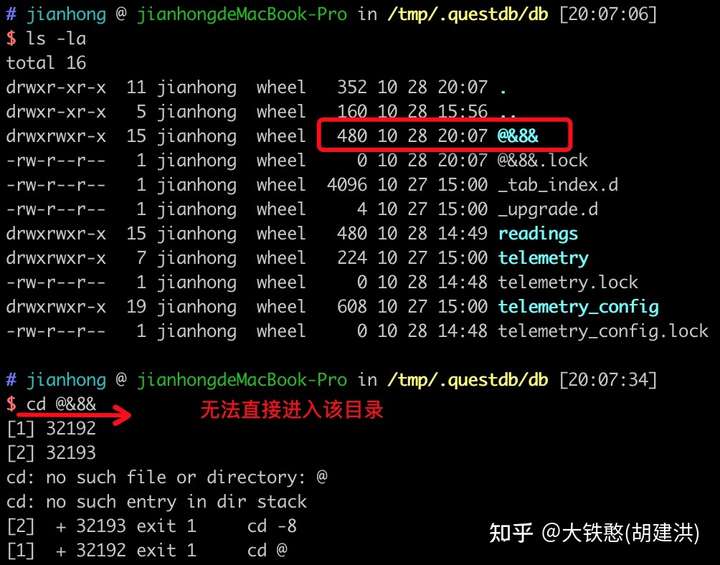
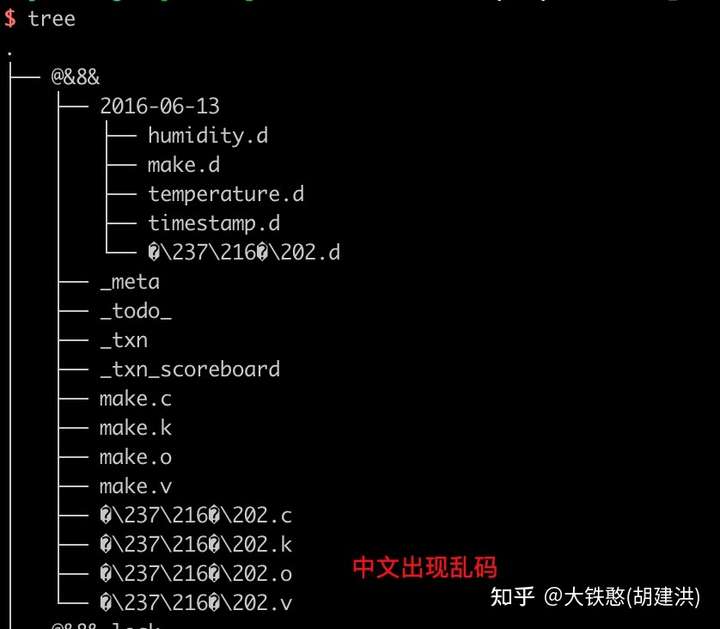
可以看到表名和列名都直接映射到了磁盘目录上面,如果列名为中文或者特殊字符,可能会出现意想不到的情况,比如写入"@&8&,城市=伦敦,make=Omron temperature=23.5,humidity=0.343 1465839830100400000" 后,磁盘目录布局如下所示,会出现无法进入目录和中文乱码等问题。
3.2 乱序数据提交
在现实时间中,写入的数据很难保证一直按照时间单调递增的方式到达服务端,因此QuestDB从6.0 版本开始,增加了对乱序 (O3) 数据摄取的支持。
大多数实时乱序数据模式是由传递机制和硬件抖动引起的,因此时间戳分布会被某些边界所包含,如下图所示。
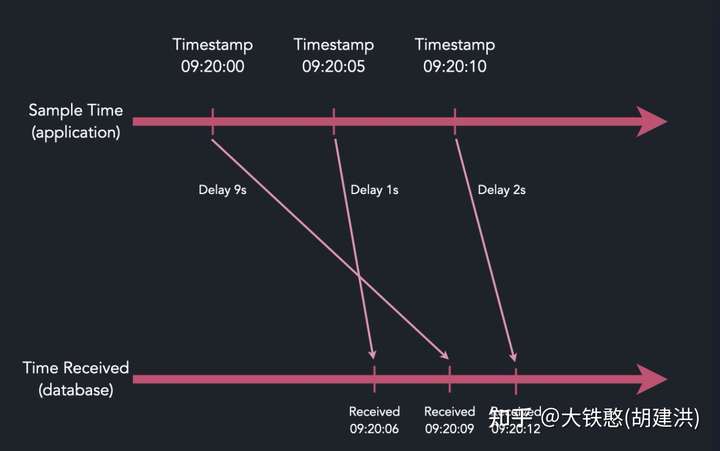
针对这种情况,QuestDB提供了maxUncommittedRows和commitLag两个参数用于处理乱序到达的数据,其中commitLag表示允许数据到达的延迟窗口,在窗口内的数据将在内存中等待排序,当延迟窗口移动或者内存中暂存的行数到达大未提交的行数maxUncommittedRows, 内存中未提交的数据将提交写入磁盘。
需要注意的是,这个乱序提交目前仅用于influxDB行协议写入方式,详情参考官网文档:https://questdb.io/docs/guides/out-of-order-commit-lag/
3.3 数据分区
时序数据天然带时间戳,同时查询条件也通常带时间范围,因此在存储数据时按照时间范围对数据分区,将极大的提交数据的检索效率,同时使得按照时间范围进行文件保留策略实现变得容易。因此,QuestDB 提供了按时间间隔对表进行分区的选项,每个间隔的数据存储在单独的文件集中,如下图所示。
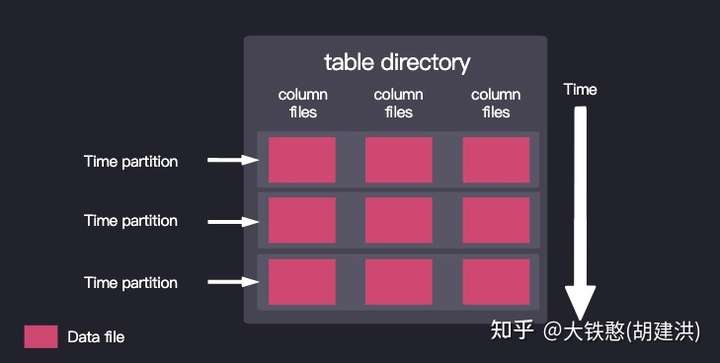
QuestDB的时间时间分区的可用分区间隔是NONE,DAY,MONTH和YEAR,默认行为是PARTITION BY NONE。
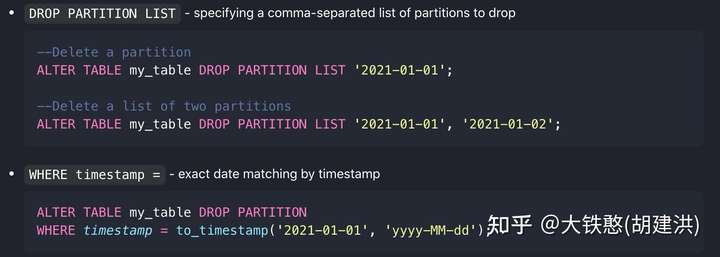
数据分区可以通过SQL语句进行删除,示例如下图所示,官方文档可以参考:https://questdb.io/docs/operations/>
3.4 文件格式
QuestDB的存储引擎实现在包io.questdb.cairo中,入口类为CairoEngine,其中文件格式相关的实现大部分可以在io.questdb.cairo.TableUtils#createTable方法中找到,下面就QuestDB的文件格式进行简单分析。
3.4.1 元数据文件
元数据文件_meta的文件格式如下所示,主要记录了表的参数和列名、版本等信息,按照内容整体上可以分成metaHeader和columnMeta两个部分(源码中没有metaHeader和columnMeta定义,这里只是方便画图和理解), 如下图所示。
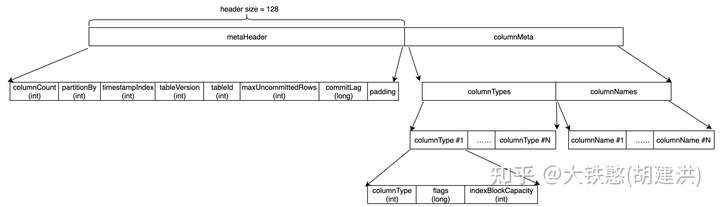
元数据头metaHeader中记录表的列数columnCount、时间分区粒度partitionBy、时间戳列在所有列中的位置timestampIndex、表的版本tableVersion、表的编号tableId、乱序写入相关的大不提交的行数maxUncommittedRows和时间窗口commitLag。虽然metaHeader部分目前只使用了32个字节,但是实际上QuestDB做了冗余处理,让metaHeader固定长度为128字节。
列元数据columnMeta包含列的数据类型column*和列名columnNames两个部分。其中对于列数据类型部分,标识flags记录了列是否支持索引和值是否是顺序的,即flags的第1个bit位表示是否被索引,第2个bit位表示值是否是顺序的,比特位为1表示支持,为0表示不支持,如下所示。索引块大小indexBlockCapacity表示创建索引时该分配多大的数据块。

元数据文件记录的数据基本在创建后就不会被修改,当然也可以使用SQL语句修改表的参数和列信息,具体可以参考官网文档:https://questdb.io/docs/reference/sql/create-table/
3.4.2 事务数据文件
事务数据文件_txn的读写实现代码在io.questdb.cairo.TxWriter和TxReader类中。事务数据文件主要记录了表的数据的统计信息,以及事务编号等信息,文件内容整体上可以划分为事务元数据txnMeta、符号元数据symbolMeta、分区元数据partitionMeta等3个部分。

事务元数据txnMeta记录了整张表的统计信息,主要包括以下内容,这些内容在表进行commit时会持久到磁盘上,源码在io.questdb.cairo.TxWriter的171行到194行。
- 事务编号txn: 用于支持读写的隔离性,即保证不会读到未提交的写入数据;
- 瞬时行数transientRowCount:记录活跃时间分区partition已经写入的行数;当切换分区时,该字段会重置为0;
- 固定行数fixedRowCount: 记录表已经提交的行的总数;
- 小时间戳minTimestamp: 记录表已经写入数据的小时间;
- 大时间戳maxTimestamp: 记录表已经写入数据的大时间;
- 结构版本structureVersion: 表结构版本号,目前为0;
- 数据版本dataVersion: 数据结构版本号,目前为0;
- 分区版本partitionTableVersion: 分区表版本号,目前为0;
- 事务编号txnCheck: 使用磁盘双写机制保证事务在磁盘上原子提交;
符号元数symbolMeta,记录了表的符号列总数symbolMapCount, 以及每列已经写入的符号总数,其中,symCount表示写入已经提交的符号表总数,transientSymCount表示已经写入包括未提交的符号总数。
分区元数据partitionMeta,记录了已经创建的时间分区的总数partitionUpdateCount, 以及partitionUpdateCount个分区元数据partitionMetaEntry,每个partitonMetaEntry记录了分区的小时间戳partitionTimestampLo, 已经写入的行数rowCount,名称事务编号nameTxn(当名称有变更时记录,默认值为-1),数据事务编号dataTxn,每当该partition有数据写入时记录表的事务编号txn;
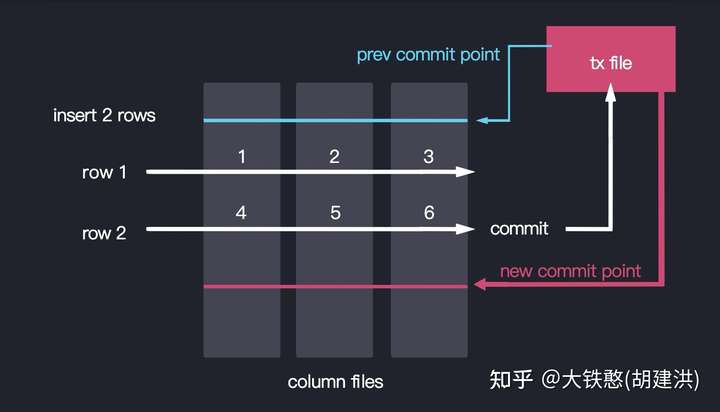
QuestDB通过事务数据文件进行读写事务(隔离性)支持的示例如下图所示。
3.4.3 列数据文件
列数据文件格式比较简单,命名方式为: "column.d", 写入方式为直接在文件尾部通过mmp的方式追加数据,如下所示。
QuestDB目前支持的数据类型分成两类:定长数据类型(boolean、byte、int、double、geohash等)和变长数据类型(string、binary),共计15种数据类型,详情参考官网文档:https://questdb.io/docs/reference/sql/data*/
对于定长数据类型,可以直接根据行号rowId计算出数据在文件中偏移offset,或者根据偏移offset计算出行号rowId,计算公式如下所示,其中dataTypeLen表示数据类型的长度,比如,double为8个字节、boolean为一个字节;

对于变长数据类型,是没有办法直接根据数据的offset计算出其对应的行号rowId,因此需要将变长类型数据的在文件中偏移量offset存储下来,然后增加一个对原始数据偏移量offset的二级索引,间接计算出原始数据的行号rowId。
QuestDB对于列数据的存储方式,是每列一个文件。若是变长数据类型,则增加了一个"column.i"文件作为二级索引,如下所示。
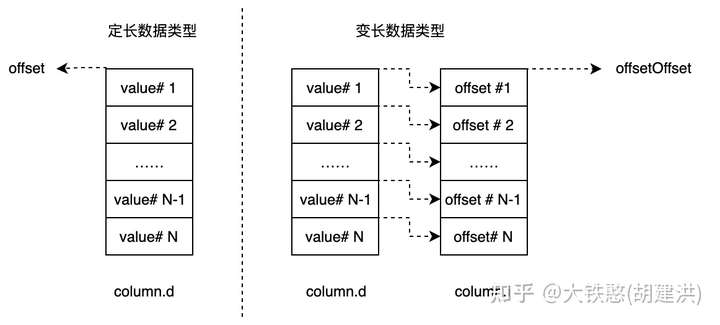
即对于定长数据类型,只要知道行号rowId,即可以计算出数据在文件中的偏移offset;对于变长数据类型,需要先根据行号rowId计算出数据偏移offset的偏移offsetOffset,然后根据offsetOffset到column.i文件中读出数据偏移offset,后到column.d文件中读取对应的数据,即变长数据类型的读取要比定长数据类型的读取多一次文件IO。
3.4.4 符号表文件
QuestDB 引入了一种名为symbol的数据类型, 用于存储重复字符串的数据结构,定义为symbol的列支持索引。比如对应InfluxDB行协议写入的数据,QuestDB就将标签tag映射为symbol类型,如下所示,city和make标签的数据类型为symbol。通过字典化的方式降低存储成本,并提高检索效率。
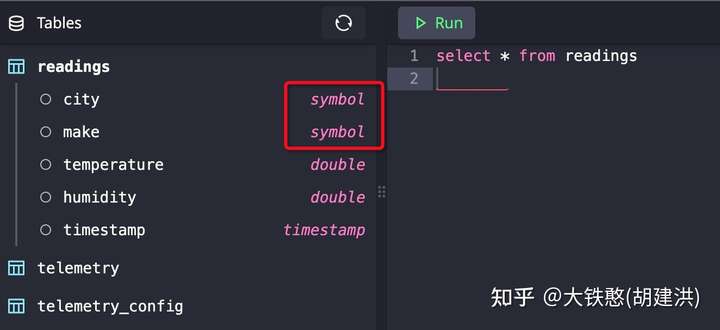
因为Symbol类型是变长类型的,因此通过冗余记录符号的偏移offset才能对文件中的符号进行索引,因此符号表文件包括偏移文件column.o和字符文件column.c,两个文件的结构和两者之间的关系,如下图所示。
对于offset文件,主要分成两个部分:
- 个部分:64字节固定大小的头部,目前只记录了符号容量symbolCapacity和符号缓存标识symbolCacheFlag两个字段,剩余字节填充0;
- 第二个部分:存储的是symbol在符号文件中偏移charOffset;需要注意的是,charOffset是符号插入char文件后的文件偏移offset,第N个charOffset指向的是第N +1个字符在char文件中开始偏移Offset;
对于char文件,比较简单,使用append的方式不断追加新出现的字符。
对于写入文件中符号,需要支持按照符号内容进行检索的能力,因此QuestDB还针对符号构建了位图索引(关于位图索引的实现,在3.3.5小节会简要介绍)。因为符号的长度是不固定的,且数量不确定,因此QuestDB为了简化索引时间,对符号本身进行了有界hash处理生成一个索引的key,即key = boundHash(symbol, 127),取值范围为[0, 127]。因此,对于符号文件本身的索引,终是将(key, offsetOffset)添加到位图索引中,其中offsetOffset为charOffset在offset文件中的起始位置。这样通过有界hash的方式,将key的范围从不确定压缩到确定的范围内,虽然当hash出现冲突时,会有额外的IO开销,但会大大降低symbol索引的实现负责度和存储开销。
另外,对于symbol类型,也会在数据分区目录下创建一个列数据文件,该文件存储的是符号索引symIndex, 其中symIndex = (offset - 64) / 8, 其中,offset为charOffset在offset文件中的offset,64为offset文件的头部的大小。symbol类型的列数据文件因为offset是定长,且数量相对较少,因此其天然适合用来间接构建行号索引,加速数据过滤。对于列数据文件,是将(symIndex, offset)添加到位图索引中的,这里的offset是指每次新添加的symIndex在列数据文件中的偏移。
3.4.5 列索引文件
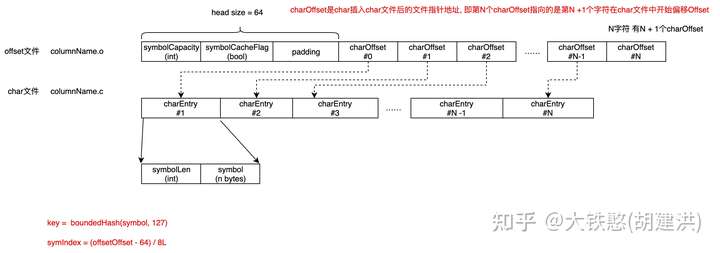
QuestDB的列索引为位图索引,位图中记录是行号,索引示例如下图所示。

当通过"INSERT INTO Table values(B, 1)"插入一条数据时,将触发两个更新,一个Table的更新,一个在Index中的更新,如下图所示。
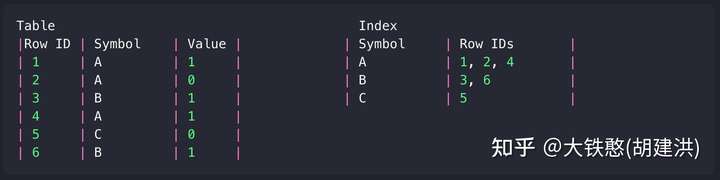
QuestDB的位图索引实现,包括key文件(column.k)和value文件(column.v)两个文件,这两个文件的结构如下所示。位图索引的输入key是int类型,value为long类型的。
对于key文件,整体上分成两个部分,部分为固定的大小的头部,主要记录索引的摘要信息,其中,signature为魔法数,相当于文件版本号,sequence记录了已经写入key的总数,valueMemSize记录了value文件已经分配的大小,blockValueCount表示每个valueBlock能够写入的value总数,keyCount表示的是已经写入的key的大值,sequenceCheck是sequence的双写保证,maxRow记录了已经添加到索引中的行数;第二部分为多个keyEntry集合,每个keyEntry记录了这个key下面的存储的value总数valueCount、个valueBlock的偏移firstValueBlockOffset、后一个valueBlock的偏移lastValueBlockOffset、value总数的双写检查valueCountCheck,因为key的类型为int,且keyEntry的大小固定,因此在key文件中没有物理存储key的值,而是将key作为偏移量隐式存储下来的,即keyEntry在文件的偏移量offset = 64 + key * 4 * 8。
对于value文件,存储文件内容比较简单,就是一系列的valueBlock,valueBlock的大小是固定的,即valueBlockSize = blocValueCount * 8 + 16,每个valueBlock存储文件偏移offset集合,以及前后valueBlock地址的偏移previousValueOffset和nextValueBlockOffset(这两个偏移将每个key的valueBlock串起来,形成双向链表)。
3.4.6 数据检索
假设给定查询 "SELECT sum(Value) FROM Table WHERE Symbol='A'", 在QuestDB内部是如何检索数据的呢?下图是这个查询对于的大致的数据检索过程,整体上可以分成7个步骤,会经过两次索引查找,次为符号表的索引查找,得到符号"A"的编号symIndex, 第二次为列数据的索引文件查找, 得到符号"A"关联的行号集合。
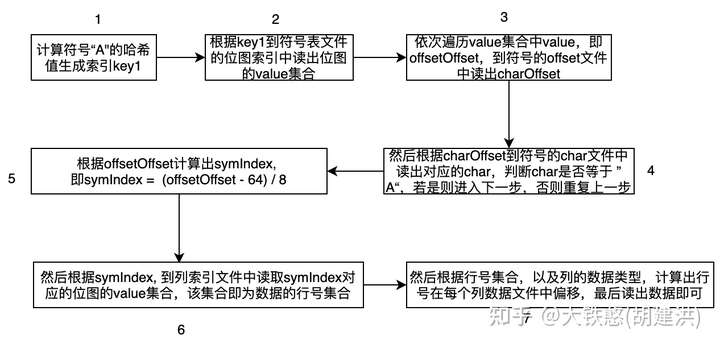
3.4.7 其他文件
QuestDB还要其他类型的文件,比如_todo_, _txn_scoreboard , _archive等文件,由于时间关系,暂时没有进行分析,如果了解或熟悉的同学知道,欢迎评论区不吝赐教。
4.总结
由于时间和精力有限,本文只是结合QuestDB的存储引擎CairoEngine部分源码和相关文档,对QuestDB的存储机制进行了简要的分析,并未深入,尤其是对于QuestDB的读取逻辑和SQL计算逻辑等这块的实现,对这块比较熟悉的同学,欢迎不吝赐教。
QuestDB的存储实现还是非常巧妙的,按列存储,支持读写隔离和乱序写入。但也存在一些不足:
- 数据丢失风险:使用mmap读写文件,所以没有WAL,写入性能从实现机制上要比有WAL的时序数据库(如influxdb)要好,但存在掉电后一定的数据丢失风险。
- 数据未压缩:由于QuestDB是直接append数据到列文件末尾的,不支持数据压缩,因此存储成本相对支持压缩的时序数据库高不少。
- 索引能力较弱:QuestDB目前的索引只支持对Symbol类型,不支持其他数据类型。
QuestDB整体上来说,还是非常不错的,使用关系模型建模,无需透传时间线的概念,用户理解成本较低,支持WebUI和SQL,上手容易。
来源 https://zhuanlan.zhihu.com/p/429830373
