物联网场景已经成为各行业巨头和各互联网公司的兵家必争之地,百度云天工TSDB对物联网场景下时序数据表现除了的存储和查询能力,已经成为物联网应用的标配,支撑着智能制造、工业能源、智能车联网、智能家居、智慧城市等多个行业应用。TSDB正在助力企业拥抱物联网时代的到来。
众所周知,百度云TSDB在读取、写入和查询数据上的性能一直表现优异。
支持每秒百万级数据点的写入,可线性扩展
查询1亿个数据点聚合值的响应时间小于1秒
提供优于传统数据库的压缩能力,大大节约存储空间
弹性、按需的海量数据存储能力,成本更低。
我们都清楚,仅有提供海量的数据存储、极速的查询能力还不足以支撑不停发展的物联网行业应用。存储的海量数据如何产生价值为业主所用,是TSDB要解决的新问题。

物联网场景下,设备都是7*24小时工作以一定的频率上报数据的,数据量十分巨大。比如一辆无人车,以10Hz的频率上传数据,每次上传20个维度的数据点,每辆车每天就要存储1700万数据点;一个传感类监测设备比如温度传感器,通常每10秒钟上传一次数据,一个楼宇建筑中如果部署200个监测点,那一天下来需要170万个数据点。随着业务的发展,数据只会越来越多。这么多数据都是挖掘行业应用的金矿。
我们都不甘心数据只做存储躺在服务器里,那怎么把TSDB中的数据发挥价值呢。不用担心,TSDB目前已经可以作为Hadoop和spark集群的数据源,进行数据分析计算啦。
先来看常使用的大数据分析工具Hadoop。Hadoop作为大数据分析的领军代表,提供可靠存储HDFS以及MapReduce编程范式以便大规模并行处理数据。TSDB作为存储海量数据的数据源,自然更需要Hadoop的帮助来做数据分析啦。我们都知道,Hadoop提供了基于廉价硬件实现大规模并行处理的能力,不过,简单的查询都要写MapReduce代码,对于商业用户实在不怎么友好。所以TSDB采用了更友好的方式,直接提供基于TSDB的Hive SQL。Hive是一个关系数据仓库,用户可以方便的利用类似SQL语言查询数据,而Hive会自动把SQL语言转换成MapReduce代码交给Hadoop处理。
那么,怎样用Hive的方式将TSDB的数据可以引用到Hadoop中做数据分析呢?非常简单,只有三步。
让我们来举个栗子:
一个风机监测站,用TSDB来存储风速的实时数据。大家知道,风速可是矢量数据,TSDB存储了x轴和y轴的数据,需要对x和y轴的数据求矢量和才能得到风速。
TSDB中的原始数据用简单的表格示意一下,就是如下:
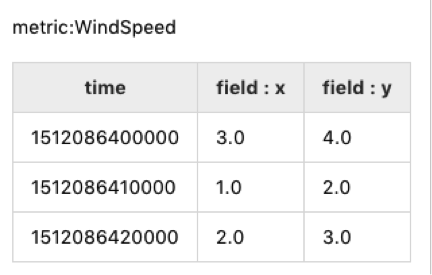
背景就是这么简单,我们就开始三步走啦。
一、下载Jar包。这个Jar包支持实现了一个TSDB的HiveStorageHandler,通过Hive CLI或Hue使用,支持对TSDB的读取。如果是本地hive集群,请下载jar包到本地,如果使用百度MapReduce(BMR),请直接使用地址bos://iot-tsdb/hive-tsdb-handler-all.jar
二、Hadoop集群中加载Jar包,并初始化。
示例代码如下:

上面的代码由以下几部分组成,
1、加载Jar包、创建表、设置storage为TSDBStorageHandler
2、初始化TSDB的参数。在TBLPROPERTIES中初始化在TSDB中用到的相关参数,如tsdb.metric_name、tsdb.timestamp_name、tsdb.field_names、tsdb.tag_keys初始化为TSDB中的值
三、通过SQL得到结果
上面的x轴和y轴的风速,需要计算矢量和拿到后的风速,利用SQL和计算函数就很简单啦

得到的结果如下:
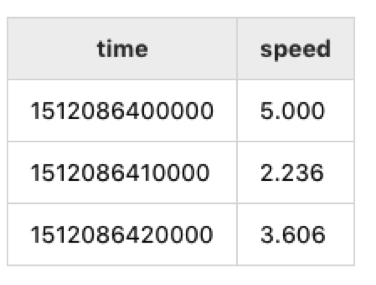
是不是很简单,聪明的你一定可以举一反三,用灵活的hive工具,就可以完成更复杂的在Hadoop做数据分析的功能啦。
除了可以直接使用hiveSQL,TSDB还支持spark SQL,步骤还是和将大象装进冰箱一样需要三步哦,需要的开发者可以直接查看帮助文档来查看操作步骤和示例代码哟
后,别忘了动手实践,可以把实践的教程贴到天工的论坛中跟大家一起分享,大家好才是真的好。
来自:https://mp.weixin.qq.com/s/l82docwfYSpHFc8PUbqEDA
