一、YARN Proxy 概述
Web应用程序代理是YARN的一部分。默认情况下,它将作为资源管理器(RM)的一部分运行,但可以配置为以独立模式运行。代理的原因是为了减少通过YARN进行基于网络的攻击的可能性。
在YARN中,应用主机(AM)有责任提供web UI并将该链接发送到RM。这引发了许多潜在的问题。RM以受信任用户的身份运行,访问该网址的人会将其及其提供给他们的链接视为受信任,而实际上AM是以不受信任用户身份运行的,并且它提供给RM的链接可能指向任何恶意或其他内容。Web应用程序代理通过警告不拥有给定应用程序的用户他们正在连接到不受信任的网站来减轻这种风险。
除此之外,代理还试图减少恶意AM可能对用户造成的影响。它主要通过从用户身上剥离cookie,并用一个提供登录用户用户名的cookie来替换它们。这是因为大多数基于网络的身份验证系统都会根据cookie来识别用户。通过将此cookie提供给不受信任的应用程序,它打开了利用此cookie的可能性。如果cookie设计得当,那么潜力应该相当小,但这只是为了减少潜在的攻击向量。
使用YARN Proxy,您可以做到以下几点:
查看YARN集群的基本信息,包括作业的概述、cluster的Metrics和近的作业历史。
查看当前正在运行的作业列表,并对其进行管理。
查看每个NodeManager的概述,以及它们所在的机器的系统和硬件资源使用情况。
查看和搜索集群日志。
查看简化的配置和状态信息,以及错误报告。
使用REST API进行远程调用和管理。
yarn proxyserver 配置参数 yarn.web-proxy.address。用于分发Resource Manager访问请求。
从Resourcemanager上点击正在执行的app,会跳转到 yarn.web-proxy.address,这里展现正在执行的job信息,job执行结束后,会跳转到historyserver上;若是没有配置 yarn.web-proxy.address,则这个功能会集成到RM中。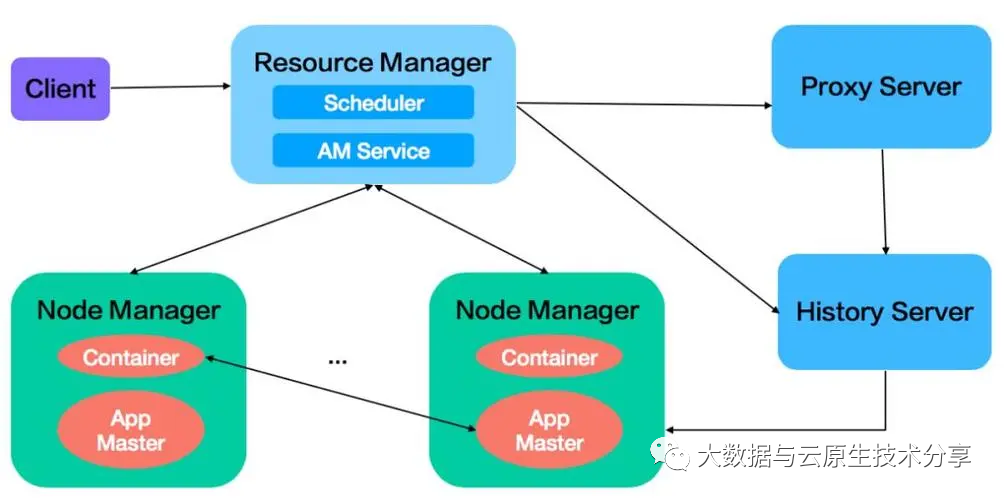
官方文档:https://hadoop.apache.org/docs/stable/hadoop-yarn/hadoop-yarn-site/WebApplicationProxy.html
二、环境准备
如果已经有了环境了,可以忽略,如果想快速部署环境进行测试可以参考我这篇文章:通过 docker-compose 快速部署 Hive 详细教程
# 登录容器
docker exec -it hive-hiveserver2 bash
# 连接hive
beeline -u jdbc:hive2://hive-hiveserver2:10000 -n hadoop
三、Hadoop 中的 historyserver
1)MapReduce Job History
MapReduce Job History,通常简称为“Job History”,是Hadoop MapReduce框架的一部分,用于记录已完成作业(job)的信息,包括它们的输入输出、计数器、任务(task)尝试次数和任务失败原因等。By默认情况下,Job History将日志聚合到本地文件系统,可以通过启用HistoryServer来统一管理和监视所有作业的历史记录。
2)Spark History Server
Spark通过Spark History Server记录了应用程序的历史记录。Spark History Server是一个可选的Web界面,用于查看已完成的应用程序的事件和元数据。Spark集群中的所有工作节点都会将应用程序的事件信息存储在本地磁盘上。当应用程序完成后,它们的事件信息会被拷贝到Spark History Server节点所在的位置。
Spark History Server默认情况下会监听 18080 端口,您可以在浏览器中访问http://<host>:18080检查已完成的应用程序。
Spark History Server提供了以下几种功能:
查看已完成应用程序的摘要信息,包括完成时间、运行时间、状态、应用程序ID和应用程序名称等。
查看应用程序的所有阶段和任务的摘要信息,包括阶段ID、父级阶段、任务ID、任务类型和任务执行时间等。
查看应用程序的计数器信息,了解它们所使用的资源。
查看应用程序执行期间的事件信息,例如Spark应用程序的RDD、计算图或输出操作,以及在内存、磁盘或网络中执行的任务。
总之,Spark History Server提供了一种简单的方法,可以查看Spark应用程序的历史记录,包括成功或失败的应用程序的事件和元数据,以便进行分析和性能调整。
3)Flink History Server
Flink也有类似于Spark的History Server功能来记录应用程序的历史记录。Flink History Server是一个用于查看和管理已完成的Flink应用程序的Web界面。
Flink History Server会收集已完成的应用程序的事件信息和日志并保存在HDFS上。Flink历史服务器本身本身是一个独立的Flink应用程序,它会检索、解析和存储存储在HDFS上的事件信息和日志,用户可以在Web界面中查看所有已完成应用程序的详细信息和日志。
Flink History Server提供以下几个功能:
查看已完成应用程序的总体摘要信息,包括DAG、计数器、开始时间、结束时间和状态等,可以从每个应用程序的监视视图链接到此处。
查看已完成应用程序的详细摘要信息,包括自定义计数器和速率指标等,同时还提供查看作业执行计划、Web UI日志和单个任务的摘要信息的链接。
通过不同的方式搜索和过滤应用程序,例如按作业ID、作业名称、状态、起始日期和结束日期等查询。
查看历史记录详情,可以查看Flink任务、操作符和物理执行计划的完整概览,并提供任务日志和操作符跟踪的链接。
总之,Flink History Server是一个很有用的工具,可以允许您查看和分析Flink作业的执行情况。它提供了丰富的功能,如过滤、搜索、摘要等,使得您可以更好地了解应用程序的执行过程。
四、相关配置
1)yarn proxyserver 配置
配置如下:
$HADOOP_HOME/etc/hadoop/yarn-site.xml
<configuration>
...
<property>
<name>yarn.web-proxy.address</name>
<value>hadoop-yarn-proxyserver:9111</value>
</property>
...
</configuration>
2)historyserver 配置
1、MapReduce Job History
mapreduce.jobhistory.address 和 mapreduce.jobhistory.webapp.address 都是与MapReduce作业历史记录(JobHistory)相关的配置属性。它们分别指定JobHistory服务器运行的地址(IP地址或域名)和端口号,以及Web界面的地址和端口号。
mapreduce.jobhistory.address用于指定JobHistory服务器的地址(IP地址或域名)和端口号,让MapReduce框架知道将作业历史记录发送到哪个服务器。例如:mapreduce.jobhistory.webapp.address用于指定JobHistory服务器的Web界面地址和端口号,让用户可以通过Web访问作业历史记录。例如:
配置文件:$HADOOP_HOME/etc/hadoop/mapred-site.xml
<configuration>
...
<!-- MR程序历史服务地址 -->
<property>
<name>mapreduce.jobhistory.address</name>
<value>hadoop-mr-historyserver:10020</value>
</property>
<!-- MR程序历史服务web端地址 -->
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hadoop-mr-historyserver:19888</value>
</property>
...
</configuration>
2、Spark History Server
修改 spark-defaults.conf,添加如下内容:
spark.eventLog.enabled true
spark.eventLog.dir hdfs://hadoop-hdfs-nn:9000/sparkhistory
spark.driver.memory 64g
spark.eventLog.compress true
修改spark-env.sh,添加如下内容:
export SPARK_HISTORY_OPTS="-Dspark.history.ui.port=7777 -Dspark.history.fs.logDirectory=hdfs://hadoop-hdfs-nn:9000/sparkhistory"
3、Flink History Server
Flink 提供了 history server,可以在相应的 Flink 集群关闭之后查询已完成作业的统计信息。此外,它暴露了一套 REST API,该 API 接受 HTTP 请求并返回 JSON 格式的数据。
配置项 jobmanager.archive.fs.dir 和 historyserver.archive.fs.refresh-interval 需要根据 作业存档目录 和 刷新作业存档目录的时间间隔 进行调整。
# 监视以下目录中已完成的作业
historyserver.archive.fs.dir: hdfs:///hadoop-hdfs-nn:9000/flinkhistory
historyserver.web.address: 0.0.0.0:8082
# 每 10 秒刷新一次
historyserver.archive.fs.refresh-interval: 10000
五、yarn proxyserver 和 historyserver 启停
1)yarn proxyserver 启停
$HADOOP_HOME/bin/yarn --daemon start proxyserver
$HADOOP_HOME/bin/yarn --daemon stop proxyserver
2)historyserver 启停
1、MapReduce Job History 启停
$HADOOP_HOME/bin/mapred --daemon start historyserver
$HADOOP_HOME/bin/mapred --daemon stop historyserver
2、Spark History Server 启停
$SPARK_HOME/sbin/start-history-server.sh
$SPARK_HOME/sbin/stop-history-server.sh
【温馨提示】
start-history-server.sh脚本默认情况下启动Spark History Server只是将文件存储在/tmp/spark-events目录下,这是本地文件系统路径。如果您没有在配置文件中指定spark.history.fs.logDirectory属性,则Spark History Server将在该目录下保存事件日志和历史记录。对于开发和测试目的而言,这个默认的存储路径是足够的。
3、Flink History Server 启停
$FLINK_HOME/bin/historyserver.sh start
$FLINK_HOME/bin/historyserver.sh stop
yarn proxyserver 和 historyserver 讲解就先到这里了,有任何疑问欢迎给我留言或私信
