早些年,在所有程序员眼中BAT可谓是宇宙厂,是很多人的终极目标。可是谁也想不到当初BAT像依赖氧气一样依赖IOE(IBM:服务器提供商,Oracle:数据库提供商,EMC:存储设备提供商)。有这样一个故事,2008年马云邀请王坚加入阿里,目的是为了解决阿里的“计算力”问题。当时淘宝面临的大问题就是数据没地方存,IOE并没有扛过高并发。这里我们只关心数据没地方存的问题,如果只是一味的扩大机器数量那么买服务器的钱都不够。关于这个故事大家可以去阿里云社区看看阿里云的这群疯子这篇文章。
早些年前后端项目基本都是JSP+Servlet。这也就是大家口中的Web1.0时代,这个时代很多应用程序都是用JSP+Servlet开发的。直到2000年左右,谷歌,各种论坛开始兴起,访问量剧增,很多公司面临单机MySQL效率非常低下的问题(APP很大一部分性能取决于服务端)。
单机MySQL问题的初期解决方案是使用文件来缓存数据,但是访问量继续增大时,文件缓存也招架不住,原因是后台通常部署多个项目,多个项目不能共用一个缓存文件。
文件缓存后的解决方案是分布式缓存服务器Memcached,这个阿里至今还在使用,它为多个web项目提供了共享的缓存服务。
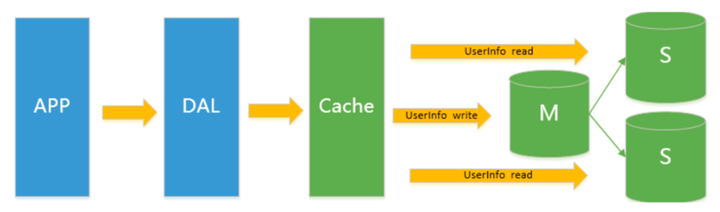
大家都知道缓存是直接放在内存中的,读取是非常快的,而直接读取数据库则比较慢。简单说缓存相当于数据库的上一层。(没有什么是加一层解决不了的)
Mysql主从读写分离
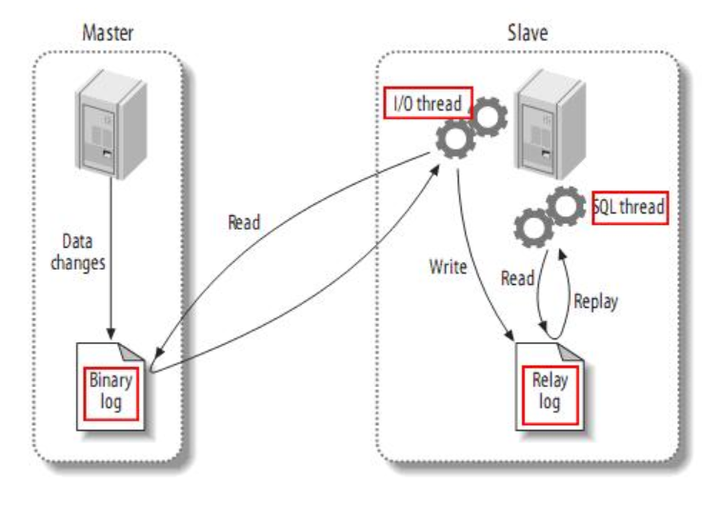
随着用户爆炸式增长,数据库的写入压力也变得越来越大。上面的缓存只能解决读的压力,而写的压力却不能解决。这个时候读写集中在一个关系型数据库,压力非常大。解决问题的方案是主从复制来达到读写分离的目的。Mysql的master-slave模式被广泛应用。需要注意的是数据只能从主机写入,同步到从机
主从复制即有主有从,采用增加服务器的方式来提高系统的可用性。一般是1主2从,数据写入主库,后复制到从库中。复制到从库中除了读的作用以外,还能起到容灾备份,保证数据完整性等功能。
主从复制的三个步骤:
- master将改变记录到二进制日志(binary log)中(这些记录叫做二进制日志事件,binary log events);
- slave(从机)将master(主机)的binary log events拷贝到它的中继日志(relay log);
- slave(从机)重做中继日志中的事件,将改变反映它自己的数据。
读写分离
主从复制后,主机负责写,从机负责读。除此之外,当时还流行分库分表来缓解写压力和数据增长的扩展问题。 MySQL的cluster集群只能在一定程度上保证程序的可靠性。
- 什么是分库分表? 顾名思义就是把一个库的数据分到几个库里,把一个表里的数据分到几个表里(简单理解就是复制容器,共同存储数据)
- 为什么要分库分表? 分库分表主要原因是数据库中数据量是不可控的,在未分库分表的情况下,库中的表会越来越多,表中的数据也会越来越多,相应的读写操作也会变多;第二个点就是单机的情况下,数据库的存储能力和处理数据的能力都会达到瓶颈。
- 分库分表的实施策略
- 水平拆分
- 垂直拆分
为什么要学习NoSQL
jsp+servlet的web1.0时代已经过去,随之兴起的是web2.0时代,这个时候java崛起。天猫都由php转向java。但是大数据时代的来临,一个商品详情里有商品信息,图片信息,大量的描述,视频等,存在在非关系型数据库是不合理的。MySQL是不支持存储图片与视频的,他存放的是一行一列的东西。
在众多Nosql中,发展快的就是redis,所以我们要学redis。Redis1s写8w,读11w。NoSQL数据库都具有非常高的读写性能,尤其在大数据量下,同样表现。这得益于它的无关系性,数据库的结构简单。一般MySQL使用Query Cache。NoSQL的Cache是记录级的,是一种细粒度的Cache,所以NoSQL在这个层面上来说性能就要高很多。
常见NoSQL数据库
| 分类 | 举例 | 典型应用场景 | 数据模型 | 优点 | 缺点 |
| 键值(k-v)存储 | Redis,OracleBDB,MemcacheDB | 内容缓存,主要用于处理数据的高访问负载,也用于一些日志系统等等。 | Key指向Value的键值对,通常用hash table来实现 | 查找速度快,存储不管value的格式 | 数据无结构化,通常只被当做字符串或者二进制数据 |
| 列存储 | Cassandra ,HBase,Hypertable | 分布式的文件系统 | 以列簇存储,将同一列数据存在一起 | 查找速度快,针对某一列或几列查询有很大的IO优势 | 功能相对局限 |
| 文档存储 | CouchDB,MongoDB | Web应用(与Key-Value)类似,Value是结构化的,不同的是数据库能够了解Value订单内容 | Key-Value对应的键值对,Value为结构化数据 | 只针对文档中的某些字段建立索引。数据结构要求不严格,表结构可变,不需要像关系型数据库一样需要预先定义表结构 | 查询性能不高,而且缺乏统一的查询语法 |
| 图形(Graph)存储 | Neo4J,InfoGrid,Infinite Graph,FlockDB | 社交网络,推荐系统等。专注于构建关系图谱 | 图结构 | 图形关系的佳存储。利用图结构相关算法。比如短路径寻址,N度关系查找等。 | 很多时候需要对整个图做计算才能得出需要的信息,而且这种结构不太好做分布式的集群方案 |
大环境下的问题及现状
3v:
- 海量Volume
- 多样Variety
- 实时Velocity
3高:
- 高并发
- 高可拓
- 高性能
