本文转载至Power BI 中国社区
微软除了有Power BI数据可视化这个强大的武器之外, 还有哪些新的秘密武器呢? 今天就给大家介绍一个微软新的数据分析服务 - Azure Synapse Analytics。
Azure Synapse Analytics(原名Azure SQL数据仓库)是一种无限制的分析服务,它可以使用无服务器的按需资源或预配资源,任意执行自己定义的大规模数据查询。它将企业数据仓库和大数据分析结合在一起, 以统一的经验引入、准备、管理和服务数据,满足即时 BI 和机器学习的需求。
近,Azure Synapse Analytics正式发布了两个与关系型数据库有关的新功能: 结果集缓存和具体化视图, 在配合Power BI使用时可大幅提升报表性能。本文将介绍可以为Power BI查询提速的不同方法,以及在Power BI中是否依然需要使用Azure Analysis Services,或者只使用表格模型就足够了。
* 请注意,Azure Synapse Analytics还有一个单独的预览版本,该版本包含工作区(Workspace)以及一些新功能,例如Apache Spark、Azure Analytics Studio、Serverless按需查询,该版本中的关系型数据库引擎和关系型存储是“SQL Analytics”池的一部分。本文介绍的所有内容同样适用于SQL Analytics池。为避免产生混淆,下文将使用“SQL DW”同时代表当前版本的Azure Synapse Analytics以及预览版中的SQL Analytics池。
首先简单看看可以在Power BI中使用的各类选项:
1 导入
从数据源(例如SQL DW)选中的表和列可导入Power BI Desktop进而导入计算机内存。随着我们创建可视化或与可视化结果交互,Power BI Desktop将直接使用导入的数据,而不会碰触数据源(在其内部,Power BI会将相关数据存储在位于内存缓存中的分析服务引擎中)。我们必须刷新数据进而将完整数据集重新导入(或使用Power BI Premium的增量刷新功能),才可以看到自从初始导入或上次刷新后底层数据产生的变化(因此这种方式并不是实时的)。Power BI服务中导入的数据集大小存在上限,Power BI Premium版多可导入10GB数据集(预览版中该上限为400GB,这也是Azure Analysis Services能支持的大规模),Power BI免费版多可导入1GB数据集。
* 请注意,数据在被导入内存时会被高度压缩,因此实际可导入的数据量可能远大于这些限制。
详情可参阅Power BI Desktop中的数据源:
https://docs.microsoft.com/zh-cn/power-bi/desktop->
2 DirectQuery
不将任何数据导入或复制到Power BI Desktop中。此时当我们创建可视化或与可视化结果交互时,Power BI Desktop会直接查询底层数据源(例如SQL DW),这意味着我们始终可以看到SQL DW中的新数据(也就是实时的)。DirectQuery可供我们针对非常大的数据集构建可视化,此时数据集的规模甚至可以大到已经无法首先导入然后进行聚合(虽然现在可以支持大400GB的数据集,但聚合表依然需要使用DirectQuery,因为很多情况下数据集无法完全装入内存,并且只有需要实时获得结果时才有必要使用DirectQuery)。
* 详情可参阅DirectQuery支持的数据源:
https://docs.microsoft.com/en-us/power-bi/power-bi->
3 复合模型
可供一个报表无缝结合来自一个或多个DirectQuery数据源的数据,并/或结合来自DirectQuery数据源和已导入数据的混合数据。这就意味着我们可以将多个DirectQuery数据源与多个导入的数据源结合在一起。
4 双重存储模式
取决于提交到Power BI数据集的查询上下文,双重表(Dual table)可以表现为缓存的(导入的)或未缓存的。某些情况下,使用缓存的数据即可实现查询;但也有些情况,可能需要针对数据源执行按需查询(DirectQuery)才能实现查询。
5 聚合
通过底层详细信息表(将被设置为DirectQuery,意味着详细信息数据会保留在数据源,不被导入)可以创建聚合表(如果设置为导入模式,聚合表会驻留在内存中)。如果用户查询所需的数据可以从聚合表中获取,那么将直接从内存中的表内获取;否则会针对底层详细信息表发起一次DirectQuery。针对同一个详细信息表,我们可以使用不同的Summations off创建多个聚合表。聚合表可以看作一种微型的多维数据集,或类似于在SQL数据库中通过索引加速SQL查询的性能优化技术。然而要注意,聚合表的创建过程需要耗费一定时间(类似于多维数据集的处理工作),并且数据不是实时的(只能体现后一次刷新后的结果)。
你可能会好奇,Power BI的导入模式现在已经可以支持更大的模型(400GB),此时还有必要使用聚合表吗?大部分情况下还是必要的。
首先,仅Power BI Premium支持更大的模型,如果你使用了免费版Power BI,那么模型大只能达到10GB。其次,导入大规模的详细信息表会在不进行聚合的情况下导入所有详细信息记录(如果是一个260亿行的表,那么就要将260亿行数据导入内存)。因此哪怕上限高达400GB,一些非常大的表依然无法导入,因而此时可以使用聚合表创建聚合(260亿行的表经过这种方式处理,可能被缩小为仅1000万聚合行,更容易装入内存中)。这种情况下,需要复制到内存的数据量将会大幅减小。就算某个查询需要的聚合数据无法从内存中的聚合表内获取,此时也没问题,Power BI会针对详细信息表执行DirectQuery。简而言之,聚合表可以帮助我们顺利使用原本根本无法完全装入内存的大容量数据集,可以帮助我们使用更便宜的SKU节约成本,并且我们完全不需要管理将数据复制到内存的相关操作。
Azure Synapse Analytics新增的两个用于提高性能的功能非常重要:
结果集缓存:可将查询结果自动缓存到用户数据库中以供重复使用。借此,后续查询执行时就可以从持久缓存中直接获得结果,不再需要重新计算。结果集缓存可改善查询性能(将所需时间降低至毫秒级)并降低计算资源的用量。此外,使用缓存结果集的查询会在Azure Synapse Analytics中设置为do not use any concurrency slots,因此不会消耗现有的并行请求限制。
具体化视图:和表类似,这是一种预算计算、存储并在SQL DW中维持数据的视图。每次使用具体化视图时,将不再重新进行计算。用到具体化视图中全部或部分数据的查询可以借此实现更高性能。更棒的是,查询甚至可以在无需直接引用的情况下使用具体化视图,因此该功能的使用完全不需要更改应用程序代码。
因此在使用Azure Synapse Analytics作为Power BI数据源的情况下,查询访问数据时涉及到的不同层面将会如下所示
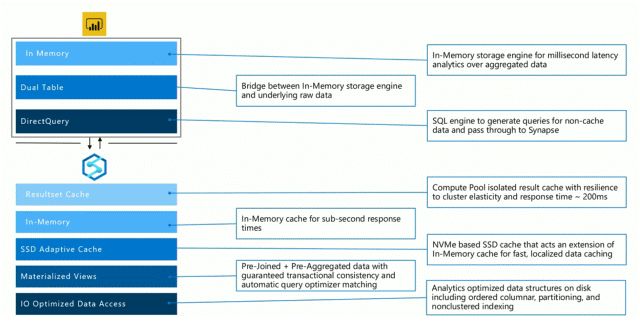
每一层的性能表现到底如何?分享一个实例: 在微软Ignite课程中我们针对260亿行数据运行相同Power BI查询: 按年份返回店铺的总销量。相同查询使用不同层运行了三次:
针对SQL DW中的表运行DirectQuery,耗时8秒。
针对SQL DW中的具体化视图运行DirectQuery,耗时2.4秒。请注意:无需在查询中指定自己要使用具体化视图,SQL DW优化器会判断是否可以使用。
使用导入到Power BI的聚合表,耗时0毫秒。
需要注意的是,这一切对用户都是透明的,用户只需要创建报表即可。如果用户在Power BI中查询的表不在内存中,将会针对数据源执行DirectQuery,整个过程可能需要一些时间。不过因为SQL DW支持结果集缓存,因此重复的DirectQuery将会变得非常快(在Ignite课程中演示的DirectQuery,查询运行耗时42秒,但在使用结果集缓存的情况下,再次运行该查询仅耗时154毫秒)。
完整实例链接
https://myignite.techcommunity.microsoft.com/sessions/84568?source=sessions
借助结果集缓存和具体化视图等功能,我们就可以在不将数据载入Power BI的前提下获得梦寐以求的高性能。
另外需要注意:短期内,Synapse并不会对使用外部联接的查询(而这恰恰是Power BI默认发送的查询类型)使用具体化视图。因此Power BI用户如果希望使用具体化视图,需要为数据完整性选项设置可信数据源(但当Synapse正式发布后就不需要这样做了)。另外需要注意,具体化视图可以直接查询,因此用户可以创建具体化视图,随后即可在Power BI中创建直接引用这些视图的聚合。
这些新功能也会让我们产生疑问:我们是否依然需要Azure Analysis Services(AAS),或者只需要使用Power BI中的表格模型(例如“多维数据集”)?还是两者都不再需要,直接在Power BI中使用DirectQuery?
对于个问题:
假设你已经有了Power BI Premium(尤其是该版本现已支持XMLA终结点),那么确实没必要继续使用AAS。Power BI Premium终将包含AAS的全部功能。但考虑到平移迁移的场景,AAS在可预见的未来将继续获得支持:AAS在模型建模方面与本地的SSAS保持了一致,因此对于尚未真正了解Power BI在现代化革新等方面完整收益(具体收益可参阅下文)的客户,在准备好拥抱Power BI前,这些客户可能暂时会选择迁移至AAS(但终依然将支持从SSAS平移至Power BI的做法)。如果希望将其与第三方产品(例如报表工具)配合使用,并且无法使用Power BI Premium(例如你的公司可能统一使用了其他报表工具)此时可能依然需要用到AAS。
将Power BI与AAS配合使用可获得的收益包括:使用Microsoft Information Protection标签实现基于Microsoft Cloud App Security的数据保护、共享数据集、聚合、通过DW为大数据创建的复合模型、借助增量刷新实现的简化管理、跨越工作区的Power BI数据世系视图、与大数据数据源更完善的连接能力、分页报表、数据流、自动化的机器学习和认知服务、Power BI Desktop建模、自带(加密)密钥以及多模型内存管理。
不过也要注意,目前AAS的某些功能依然未包含在Power BI中,这些功能包括:从Visual Studio部署至Power BI的能力、XMLA写入终结点、查询的横向扩展、与某些第三方工具的集成、备份/还原、防火墙、多种服务层级、Log Analytics集成、REST API的异步处理、透视、模型中的关键绩效指标(KPI)、不规则层次结构、对象级别安全性以及元数据翻译。
好在以后我们将能用非常简单的方法把Analysis Services模型部署到Power BI Premium,因此如果现在使用了Analysis Services,以后也不会丢失任何工作成果。届时,我们只需要在Visual Studio中,将部署服务器属性的值由现有SSAS或Azure AS服务器改为Power BI Premium工作区的XMLA终结点即可。
对于第二个问题:
是否可以针对SQL DW只使用DirectQuery,以避免在Power BI中同时使用AAS和多维数据集。答案是肯定的,但前提是你确定所要使用的查询总是能命中SQL DW的结果集缓存. 但如果无法满足这样的前提,尤其是你使用的Power BI仪表板需要为所有查询实现毫秒级别的响应,那么好在Power BI中为这样的仪表板使用多维数据集或聚合,并为即席查询使用SQL DW。另外需要注意,在Power BI中针对SQL DW使用DirectQuery时会在DAX方面用到一些限制,此时可能需要在Power BI中使用AAS或多维数据集,而非DirectQuery。这些限制也包括时间智能功能。另外还要注意,当你不再使用多维数据集时,可能会非常怀念它所提供的某些价值:语义层、无需联接或关系、层次结构、KPI、时间计算,以及更高的并行请求限制。
