
不少分布式系统都在使用ETCD分布式中间件系统作为分布式系统,系统数据的存放地,通过ETCD存储的信息来为分布式系统本身提供节点状态的传递和节点状态的确认依据. 相对于同样支持分布式协议的zookeeper ,ETCD为什么受到不少分布式数据库系统或单机系统高可用的欢迎。
在设计分布式系统中,需要保持各个分布式节点获取整体分布式节点中各个节点的状态,这需要两个考虑来完成这个需求, 1 分布式节点状态传达与统一 2 节点状态信息的存储, ETCD 在这两方面是可以满足需求的。虽然ETCD使用的很广泛,对ETCD本身的探究却很少,那么使用ETCD的时候需要主意什么问题?
ETCD基于raft 协议, etcd系统在运行中会产生一个leader节点,leader节点主要的功能管理集群, 并进行日志的复制。etcd集群中的领导节点leader,根据预设的心跳时间,定期向follwer发送状态信息, 在规定的时间内如果leader并未发送信息,则集群中会发起产生新leader的过程。
由于ETCD对于系统运行的稳定性有着比较强的依附性,这就导致ETCD不能工作在网络不稳定和磁盘超负荷运转的系统中良好的工作。 所以不建议ETCD 部署在工况不好的环境中,以免导致频繁的主节点切换。
主节点工作中会接受来自客户端的访问和数据的写入,并下发到follower节点中,当收到大多数的follower节点的回馈,则数据写入成功,否则事务失败。
当ETCD集群中的节点的数量不符合大多数原理,则集群整体会停止工作,不在接受客户的访问和数据的写入。
2n+1 - (2n/2) = 大多数
ETCD中的数据组织通过BTREE的方式来进行组织,ETCD的存储数据的数据库建立在blotDB上通过BTREE 的方式来进行数据的存储
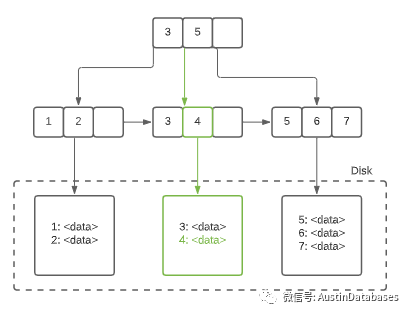
页面的数据更新方式是通过创建新的页面代替旧的页面的方式来进行的,旧的页面会挂在在freelist 区域,以备后期调用的可能。这样使用页面的方式会产生一个问题,就是会浪费数据的存储空间, 所以需要进行数据的压缩和清理的工作。
ETCD 的数据是通过多版本控制来进行控制的,通过raft log 中的索引与不同的版本进行关联。
---- Revision begins at 1 ----tx: [put foo bar] -> Revision is 2tx: [put foo1 bar1] -> Revision is 3tx: [put foo updatedBar] -> Revision is 4tx: [put foo2 bar2, put foo3 bar3] -> Revision is 5
这样存储数据的好处在于可以追踪数据的当前值和历史值, etcd中的数据存储通过
KEY VALUE 的方式来存储,如 key:(1,0,nil) value:{key:"foo",value:"hello"}
在查找这些数据的过程中,在内存中建立这些数据的B-TREE的maps 如下图,通过树
型的结构可以快速的找到数据版本中新的数据, 这里需要提醒一句,在 etcd中存
储大量的数据,可能会降低ETCD的性能,建议 1 不要在etcd 中存储巨量的数据 2
使用SSD 磁盘系统为SSD 提供存储服务。
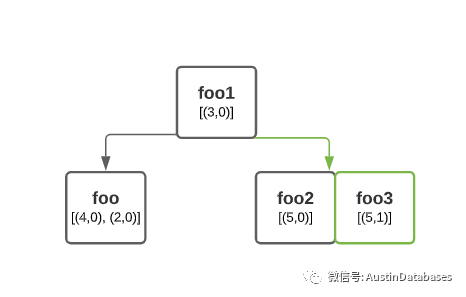
另随着数据的版本更新,越来越多的版本会保留在系统中,占用大量的内存和磁盘的空间,此时就需要进行碎片的清理,在清理的过程中,系统会阻止任何数据的写入。反观在ETCD中建立新的键,就不大会产生上面的问题。所以在使用ETCD中 频繁更新数据并不是一个好的设计,频繁更新数据会导致查询终的版本的数据,肯能要跨越多个页面才能获取到。
总结:
ETCD的使用中注意,网络和系统磁盘负载的情况,并且不要让ETCD 处于高负载压力的系统中,以免造成ETCD本身的无响应导致跳转LEADER ,在转换过程中,数据无法写入的一些问题,并且在使用ETCD的同时,需要尽量不要高频进行数据更新,避免系统在获取新的数据时,需要横跨多个数据页面获得数据。
