
▲中兴通讯GoldenDB分布式数据库架构师 陆天炜
众所周知,中兴通讯的主航道产业是5G通信,但是各行各业都会使用数据库,中兴通讯提交给客户的通讯设备上面也都使用了大量的数据库,为了给客户提供更好的交付体验,大部分都是自研的产品。
从2002年开始,中兴通讯推出EBASE文件数据库,2007年推出EBASE-MEM内存数据库,做到2011年的DHSS分布式数据库,开始有了一个雏形。2014年的时候,中兴通讯开始研发了GoldenDB这个金融级的数据库,2015年的时候已经有个商业版本GoldenDB 1.0,并在中信银行的北京营业厅的冠字号业务上开始使用。到2016年的时候,已经在多个银行不同业务等级的生产系统上做了商用投产。2017年,中兴通讯做了另外一件事情,和中信银行一起在总行的账务系统上做了一个核心下移的测试验证,并且验证通过了,性能超过40000TPS。当时客户就决定要在2019年的时候,把核心业务的数据库,从基于小机的DB2上迁移到基于X86平台的GoldenDB上。
GoldenDB分布式数据库总体架构是什么?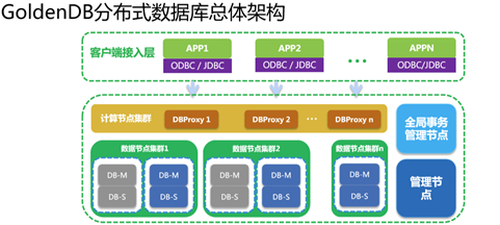
GoldenDB分布式数据库总体架构分成四个重要部分:
部分,是计算节点集群,是多点读写模式,因为计算节点没有状态,所以可以做到横向扩容。
第二部分,是数据节点集群。在一套GoldenDB里面,可以有多个数据节点集群去承载多个不同的业务,每个数据节点集群是可以做到物理隔离的。每个集群内部根据对应的业务流量,还有存储压力,去做分片,做负载均衡。每个数据分片都是一主多备的结构,每个备机可以做容灾和读负载能力的扩展。
第三部分,全局事务管理节点,用来管理全局分布式事物的一个生命周期。它跟计算节点做交互,提供全局事务ID的分配、回收,以及全局活跃事物列表的查询功能。
第四部分,是管理节点,主要包含几个重要功能:,提供了一个Web控制台页面,在控制台上可以做自动的安装、更新,集群的组建,主备切换,备份恢复等各种与运维相关的操作;第二,管理节点里面还包含了元数据管理器,源数据管理器存了两部分信息,部分信息是GoldenDB拓扑的组网信息,包括各个集群的设备信息,主备信息、IP信息等,第二部分就是业务数据库的源数据,包括DDL、库表结构、分布状态、分布规则;第三,管理节点还提供了监控,可视化告警等与管理相关的功能。
这就是GoldenDB数据库的整体架构,对外连接业务,提供的是MySQL的标准协议。
GoldenDB现在正在做的一个事情是,在2019年底的时候要把中信银行的DB2给替换掉。下面总结了GoldenDB数据库满足金融核心功能的一些关键需求。
,实时一致的分布式事务控制;在做分布式事务控制的时候,能够做到实时一致,并且事务处理不影响业务原来的业务逻辑,业务原来的代码迁到GoldenDB上的时候是不需要做逻辑变更。他们原来的代码是RPG的代码,直接通过工具改成Java代码,业务开发的工作量非常少。
第二,支持同城异地容灾和一致的备份恢复,符合异地监管的一致性。GoldenDB契合金融的两个三中心架构,能够做到同城RPO为0。无论是一致的备份恢复,还是异地接管的恢复,在做备份的时候各个节点单独备份,但恢复的时候能够能恢复到全局一致的状态。所以,异地做接管的时候,虽然会有数据丢失,但是接管后的数据也是一个一致的状态,更加方便业务进行数据回补。
第三,线性横向扩展和联机数据重分布,这包含两部分内容:一个是性能的横向扩展;一个是容量的横向扩展。关于性能的横向扩展,DBProxy能做到百分之百的横向扩展,底层数据节点是瓶颈的时候,数据节点能做到95%的横向扩展。支持在线数据重分布,并且通过追增量和冻结日志的方式,能够把真正对联机交易的影响降低到秒级,一般默认的阈值配置都在5秒以下。
第四,丰富的监控体系和完善的运维能力。传统核心基于DB2或者Oracle,只有一两台设备,运维人员和DBA人员只要监控一两台设备就行,换到这个X86的分布式架构下面,可能是十几台或者几十台,这对运维体系的易用性,对监控体系的完备性要求就更高。所以,中兴通讯的GoldenDB在2018年一整年都在做这么个事情,那就是丰富监控运维体系,跟很多第三方的平台和第三方工具做对接。
如何看待GoldenDB 事务处理机制的各种问题?
1、事务理论的分布式延伸
关于GoldenDB的分布式事务处理机制,我们先看下事务处理在分布式架构有哪些延伸。我们理解的事务的一致性,其实是在事务内的原子性(原子性-A)和事物间的隔离性(隔离性-I),以及故障时的持久性(持久性-D),只有三者组合到一起才能保证数据的一致性(C)。
在分布式架构下,原子性的要求,是在多个数据分片上的多次操作,要么一起成功,要么一起失败;而在单机架构下,仅是一台机器上多条记录的多次操作;隔离性方面,要求多个计算节点上的不同连接,不会相互访问到在多个数据分片内未提交事务的数据;而单机数据库的隔离性,是指不同连接(处理线程或进程)不会相互访问到当前机器上未提交事务的数据;另外,从持久性角度看,分布式数据库的事务提交前必须将日志在分片主、 从节点都得到复制,主节点故障时,能在从节点上找回数据,继续完成事务;单机数据库的事务要求是,提交前必须先将日志落盘,机器宕机恢复后不丢失数据。
2、分布式事务的难点
那么,要实现分布式事务的实时一致性(保证ACID ),难点在哪?其实包括两个部分:一是部分DB提交失败,如何保证全局事务的原子性(A);另一部分是,并发访问时,每个事务都不知道其他事务的状态,如何保证事务之间的隔离性(I)。以转账交易为例: 交易前2个账户资金余额各100,事务T1从账户1转账50到账 户2。需解决问题:在事务T1提交期间,由于DB1和DB2提交时间有空隙,若此时事务T2读取2个账户的余额,会发现余额之和是 50+100=150;存在事务T1对账户1上扣钱成功,给账户2加钱失败的情况。
3、如何保障原子性?
在业内,通常都用2PC协议保障原子性,在MySQL中就能看到很多场景,一个是MySQL里跨存储引擎的事务,二有存储引擎里bin log一致性的保障,都通过2PC实现。2PC有自己的优势,参与者在投赞成票之前可以单方面取消事务,但是也有一些局限性。个问题,它本身是一个阻塞式的算法,进入Prepare以后一定要成功;第二个问题是,协同者的状态其实是一个单点,协调者挂了以后,参与者没有办法继续进行下去,参与者和协调者在某些状态会等待消息,需要启动定时监控;第三问题是,正常的提交流程,日志写入数量比较大,为 2N+3 ,消息数也多,为 4N ,其中 N 为参与节点的数量。
另外,还有很多通过增加消息中间件,或者使用TCC分布式事务框架,来实现事务原子性的方案。通过业务改造保障原子性,会有额外的问题:首先,是对业务的侵入性较大,所有业务都要增加反向操作逻辑/增加额外中间件;其次,处理过程中数据存在短暂不一致或导致更新延后,原子性不能保障;其三,无论2PC、MQ还是TCC,都存在的一个问题,就是在2阶段提交Commit阶段,在MQ不断重试的阶段,在TCC的Confirm阶段如果出现了异常,没有办法解决,没有补救措施,必须人工干预。
至于,GoldenDB事务原子性机制如何实现?总结起来就两句话:句是一阶段提交。GoldenDB有一个全局事务,整体的提交是一阶段。把一个全局事务拆成由若干个子系统单独提交的一个个子事务,把这些子事务由计算节点交给对应DB去执行。执行之前,我们先在GTM那边把事务标记成活跃的状态;如果所有的DB都执行成功了,在GTM那边把事务标记为不活跃,全局事务就结束了;第二句是自动回滚补偿。遇到像转账失败的流程后,子事务在单机上会自动回滚,反馈给计算节点后,不是全部成功的,计算节点需要向数据节点下发回滚的消息。回滚补偿就是把下发回滚的操作做到数据库层面,业务层不需要做补偿交易。这种模式的优点,一是应用层无需增加额外补偿逻辑;二是,失败回滚是少数情况,整体性能高于两阶段提交,只需要一次交互就可以了,大大节省了单机资源。
4、已提交事务回滚实现和优化方式
在这一过程中,会涉及已提交事务回滚的实现和优化方式。整个过程要经历定位-遍历-生成-执行这样一个流程。通过全局事务ID所对应的Binlog提升回滚性能,数据行里会存有全局事务的ID, 当你Commit的时候,全局事务ID会随着Binlog一起进入文件里。通过Binlog里面的GTID找到这个GTID所对应的所有Binlog的语句块,然后解析Binlog,生成SQL,立刻组成新的事务,重新执行一遍。对整个操作过程,GoldenDB做了很多优化,包括表定义缓存、预分析并行查找、共享内存、key值利用、SQL格式,未来还要把正向Binlog直接生成反向 Binlog,不走SQL解析,直接走MySQL并行回放机制,直接应用到数据库。
5、事务隔离性的各种异常
我们如何处理事务隔离性的各种异常?首先,事务隔离性的各种问题都是并行调度处理不好导致,如果写写冲突,处理不当,会导致 ‘脏写’。比如: T1w、T2w、T1a,基于被回滚的数据做了update,造成了丢失回滚。再比如,写读冲突处理不当,导致‘脏读’,如果读,读到了未提交的数据,那就是脏读,如果多次读并读了不同版本的数据,那是不可重复读,由于事务并发导致前后读出的多个数据间不满足原有约束,那是读偏序,由于事务并发导致满足条件的结果集,变多或者变少,那是幻读。此外,还有读写冲突,处理不当导致 ‘脏写’ ,比如:T1r、T2w、T1w,T2w被覆盖,会导致丢失更新。后是写偏序,这是一种违反语义的异常,在数据库层面看正常,但是达不到你要求的效果,就像黑白球,我有一黑一白两个球,事务一要把黑球改成白球,事务二要把白球改成黑球,当在快照级别隔离下,两个事务一起并发操作时,会导致终事务一改了一个球,事务二改了一个球,一黑一白变成了一白一黑,这种情况是错误的,不满足于任意一种串行处理结果。以上这些异常都是并发调度没有处理好的结果。
在《A Critique of ANSI SQL Isolation Levels》论文中,总结了隔离级别及对应的现象。首先,R R级别的隔离解决不了幻读;其次,SI隔离解决不了写偏序。只有可串行化的隔离级别才能解决所有问题。有人说MySQL级别的R R隔离能解决幻读,其实MySQL级别的R R隔离并非论文里指出的R R级别,它实际上是SI的隔离级别。
那么,实现可串行化隔离级别的方式有哪些呢?种方式是严格按照串行顺序执行,这种方式肯定能保证隔离性。像Voltdb,号称是fast的内存数据库,通过串行保证隔离性,通过在存储过程里执行保证了原子性。Redis是单线程跑,所以隔离性也没有问题,但是Redis只支持单语句事务,只能保证单语句的原子性。如果你需要Redis去做多行的事务,就需要自己去保证它的原子性。第二种,是运用SS2PL技术,加锁解决幻读 。比如:MySQL、SQL Server、Informix的隔离级别,实际上都是通过SS2PL技术做到可串行化的隔离级别。第三种,可串行化的快照隔离SSI,可解决写偏序问题。像PostgreSQL、FoundationDB,都是这种模式的隔离。这三个都是正确的隔离,而其他的隔离都是对性能的妥协,都是不正确的。
6、如何通过2PL进行事务并发控制?
这里主要看下如何通过2PL进行事务并发控制。Eswaran等人已经证明:遵守2PL算法的并发调度一定是可串行化的。什么是2PL?是指在数据库事务处理中的两阶段锁定,前一个阶段只能加锁,后一个阶段只能释放锁。如果所有的事务都能遵循这样一个原则去处理,并发起来的终结果就等同于某一种串行化的并发调度结果了。不考虑事务Commit时的失败,那2PL这就够了,已经能保证事务的一致性了。但是这个可串行化的可能太多了,而且LockPoint比较难找,所以大部分厂商的实现方式都是SS2PL,都是把读锁和写锁的释放放到Commit阶段一起去执行。
问题是,从2PL到SS2PL到底有哪些限制?个是到S2PL,它做了个限制,先把写锁放到Commit,当一个事务对某个数据做了修改,但是没提交之前,所修改的数据的后像是不能被其他的事务读或者写的。SS2PL则在S2PL基础上,把读写也放到了后。如果一个事务做了修改,那么所做修改的数据的前像是没有被其他事务给读过的,SS2PL终达到的效果是,在所有的可串行化的并发调度里终选择了某一种或者某几种,来保障事务的特性。
GoldenDB是怎么做事务的并发控制的?GoldenDB引入了全局事务管理器(GTM:Global Transaction Manager)实现全局事务的隔离性,并协助实现全局事务的原子性。
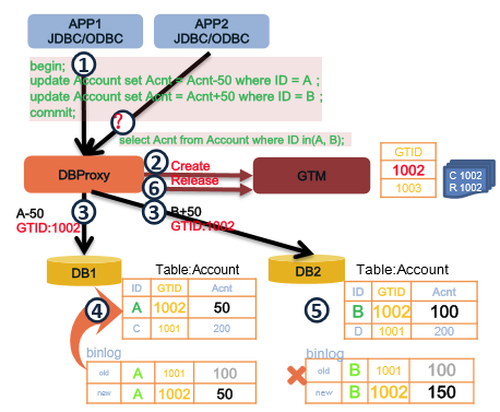
与SS2PL的比较,GTM封锁是在事务提交之前,所有的GTID相关的数据都不能被读取和修改。活跃事务列表里的GTID,相当于写锁。保障了写写和写读冲突下的数据一致性。另外,通过对读操作显式加锁,达到严格的SS2PL效果,保障了读写冲突下的数据一致性。而SS2PL只在事务提交的的时候才释放读锁和写锁。
GoldenDB还有一个预锁机制,用来解决如下问题:DBProxy查询到的活跃事务列表是旧的;DBProxy基于活跃事务列表做的判断是不准确的。GoldenDB的解决办法是,将所有的可能性冲突都认为是冲突。在返回活跃事务列表中,增加Max_GITD,Proxy判断如果GTID大于Max_GITD,也认为该事物是存在冲突的。
总结下来,对于事务处理中的写一致处理,涉及两个方面:一个是满足条件的记录上无锁, GTID不活跃,就可以直接修改数据,如果GTID活跃,这个时候需要通过预锁机制重新等待GTID被释放;另外是满足条件的记录上有锁,只能先走单机锁冲突的事务处理机制,等到锁释放了,再去判断GTID是否活跃。
对于事务处理中读一致性的处理:在脏读的场景下,不做任何判断,直接读,但是不推荐这种隔离级别;读已提交,如果有排它锁,证明这条数据有事务正在修改,直接读它的前像。如果无排它锁,GTID不活跃,没有单机事务,全局事务,直接读当前数据行。如果无排它锁,GTID活跃,说明没有单机事务,但是有全局事务,仍然不能读单机上的数据,需要去读 数据,这个前像数据的purge操作需要全局进行;在读已提交的场景下,有排他锁和无排他锁、GTID活跃场景的处理方式是一样的;在可重复读,有排它锁的情况下,会按照GTID版本号去找,找到快照开始时候的版本号。在可重复读的场景下,无排它锁,GTID不活跃,看上去没有问题,但是当前数据行有可能已经被提交过了,不能直接读,需要筛选版本判断是否需要找前像数据。无排它锁,GTID活跃,也是一样的,需要去找满足条件的GTID版本号的事务版本;可序列化级别也如此,加共享锁无冲突,GTID不活跃,可以直接读数据,如果GTID活跃,还可以读数据,但是要把活跃的冲突的GTID号给带上去,DBProxy根据预锁的机制,判断什么时候GTID能正常释放,如果正常释放,数据就可以读到。不能的话,需要把事务重启。在可序列化、加共享锁有冲突的场景下,仍然按照单机锁冲突的并发控制去处理。
事务处理模块优化有哪些实践经验?
在GoldenDB上有个GTM,是一个主要的优化点。怎么解决性能的瓶颈?首先,GTM被设计得很简单,只有三个流程,负责GTID的分配、回收,负责向计算节点提供活跃事务ID的查询的一个接口。GTID的分配和回收需要实时落盘,GTID相当于一个大号的Binlog ,一次写盘大概1μs,理论上限100万 TPS,能否突破?另外一个优化点是,Proxy和GTM之间的消息交互,对网络资源消耗过大,理论瓶颈1.25GB 带宽如何利用?
1、申请/释放GTID优化:Proxy批量请求
在释放GTID的时候,做了批量释放,能够做到减少交互次数,降低交互的数据量。在申请GTID的时候也做了批量申请,但是这里有个问题,在RC和串行隔离下面,可以任意使用批量申请,但是在RR隔离下面,是不能肆无忌惮的去使用批量申请的,在RR隔离级别下,是基于GTID的数据快照,要求GTID是严格单调的,所以在GTID申请的时候,还是要保障GTID单调,先来的事务先获得GTID。但实际上,由于系统的调度都是有误差的,比如Proxy1向GTM申请了GTID1,要去修改数据A, Proxy2向GTM申请了GTID2,也要修改数据A,虽然是Proxy1先申请,但是他不一定能快地给数据I加上锁,所以靠分配GTID去严格保障时间顺序,有误差。也就是数据库调度会有问题,不能保证先来的请求一定会先被执行。所以,在一定误差范围内,分配的GTID可以不保证严格单调的,需要做额外处理。Proxy1先申请了1000个GTID,我需要他在很短的时间内把这1000个GTID给用掉,如果不用,需要有一个废弃的机制,相当于保证GTID申请的这些事务在误差内保证单调。这样可也减少交互次数,降低交互数据量。
2、查询GTID列表优化:Proxy进行组提交
Proxy北向是一个数据库连接池,跟应用的连接池做交互,有的执行线程是在做建链,有的是在做SQL解析,但是也有可能他们都在做GTID的查询,如果所有的线程都能直接和GTID去做交互,交互数据量会很大。所以,代理线程可汇总执行线程的请求,然后跟GTM做单独的交互,并且这个交互是单线程单工的,使用一份活跃事务列表应答。当在途请求没有返回时,代理线程不会发送新的查询请求。
3、查询GTID列表优化:GTM进行组提交
GTM和Proxy是一对多的,多个计算节点去访问同一个GTM,GTM在汇总多个Proxy请求以后,他也可以产生一个子线程出来。专门处理GTM返回请求的拼装,用同一份活跃事务列表应答不同Proxy发来的请求。 当子线程没有拼装完返回列表时,不会处理新的请求,这和Proxy处理机制类似。
4、组提交优化后对预锁机制的影响
有一个问题是,刚在Proxy上和GTM上都做了组提交,但对之前的预锁机制,对性能到底有没有影响。在优化之前的场景下,Proxy上所有向GTM发的查询请求,都需要过0.5ms(32k包大小万兆下的双向时延)才能收到响应,Proxy获取到的事务列表都落后GTM0.25ms;优化之后,Proxy上所有的请求,在0~0.5ms 内会收到响应,Proxy获取到的事务列表的时间没有变化,仍然是落后GTM0.25ms,经过组提交优化后,并未增加单消息处理时延。可能有人会问,如果以后性能要求更高的情况下,如何处理带宽占用的问题?我们可以通过自适应算法精简请求,依据请求数、统计时间和当前负载情况,实时修改发送周期。另外,可以通过数据压缩技术,通过记录GTID起始值(8Byte)和偏移量位图(255Byte),将数据包大小由32k降到1K以内,压缩后万兆的带宽允许提供1200个Proxy。所以,Proxy和GTM的带宽不会是性能瓶颈。
5、申请释放GTID优化:GTM线程优化
这是之前踩的一个坑,之前是按照做DB的思路去做GTM上的持久化,专门弄了一个Flush线程去写日志,但是没有考虑到一个问题就是GTM上的数据结构非常简单,消耗的不是I/O,消耗的是IOPS,专门弄一个线程去做异步处理,处理得很快,每次收到的请求很少,导致IOPS非常高,而且线程切换非常严重。但是,把它变成串行化处理了以后,请求积攒了,IO量变大了,但是IOPS会降下来,不用做CPU的线程的切换了,CPU也减低了。
经过各种优化后,GoldenDB在这个数据模型下,经过了严苛的技术验证,实现了3亿客户15亿账户转账交易、明细查询40000 TPS的支撑能力。在这一过程中,还模拟了软硬件故障的各种测试,能满足核心业务强一致性要求,正确率达到。同时,在这个场景下,做了当Proxy是瓶颈的时候,去扩展Proxy;在DB是瓶颈的时候,去扩展DB的一个测试。其中,计算节点扩展线性率达到,数据节点扩展线性率95%。在故障隔离方面,计算节点故障、不影响整体系统交易;数据节点故障的时候,不影响其他节点交易。
原文链接:https://blog.csdn.net/weixin_36337561/article/details/113657056
