Graphite就属于一种时序数据库,作用是存储和聚合监控数据并绘制图标,不负责数据的收集。之所以想写一篇关于Graphite的博文主要是因为这是我接触到的另一种新型数据库,其特点和功能让人眼前一亮。但是需要强调的是,这里所谓的时序数据库只是Graphite的一部分(WhisperDB的),而Graphite不仅仅是数据库那么简单,它还包含有监控、数据计算、生成图标等功能。
Graphite包括3个组件:
Carbon:守护进程,监听时序数据
Whisper:数据存储,graphite内置的DB
graphite webapp:用Django开发的UI,用于图标的渲染,提供API被调用者做页面层集成。
架构图:
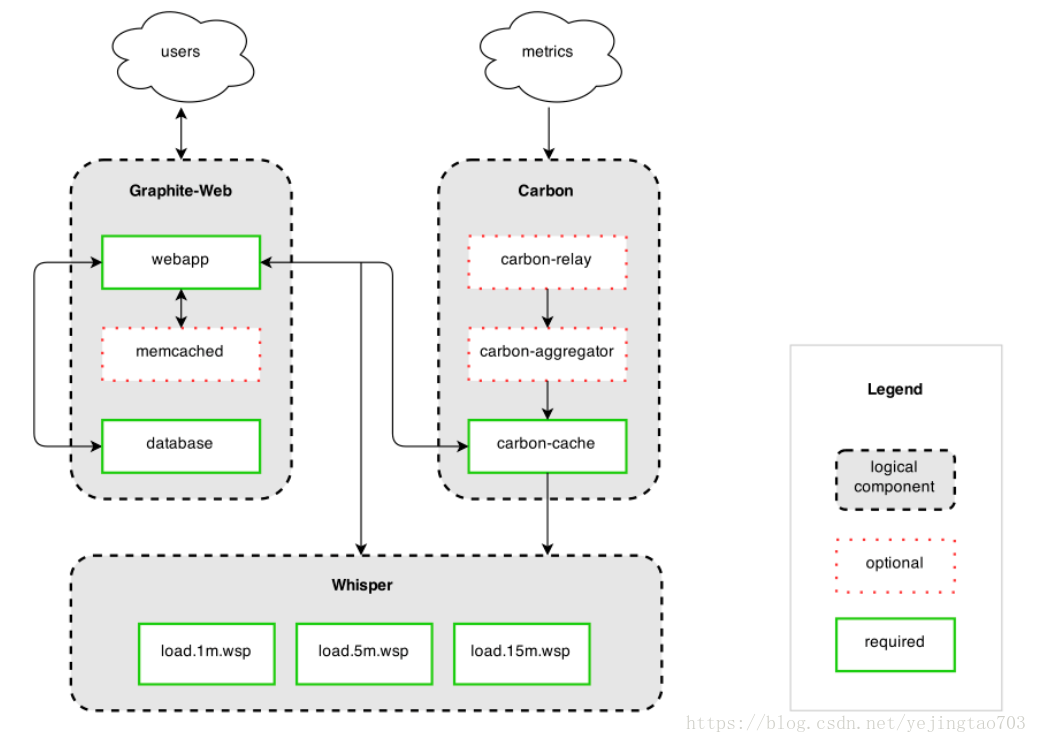
Carbon:
Carbon是一组守护进程,更详细的说是一组python代码编写的监听数据服务的进程。
简洁的安装只需要carbon-cache.py,更的安装还需要carbon-relay.py和carbon-aggregator.py,我们就来看下这3个python进程的详细功能。
carbon-cache.py,根据不同策略接受数据,并尽可能高效地将它们写到磁盘上。主要功能有2部分:1缓存数据;2写入磁盘。涉及到的配置文件也是围绕这两部分:carbon.conf中的[cache]定义了监听的端口和缓存策略;storage-schemas.conf定义了数据如何存储。
carbon-relay.py,复制和分片,为分布式而服务。涉及到的配置文件:carbon.conf中的[relay]定义了监听的主机、端口和分发模式;relay-rules.conf定义了在rules模式下详细的分发策略。
caibon-aggregator.py做数据的聚合,通过聚合减少数据库压力防止磁盘爆掉。涉及到的配置文件:carbon.conf中的[aggregator]定义了接收和分发的主机;aggregation-rules.conf定义的是聚合策略。
carbon-aggregator-cache.py是carbon-cache.py和carbon-aggregator.py的整合,将两个进程合并成一个进程,本质上要做的事情不变,涉及到的配置也不变。
从上文可以看得出carbon.conf是重要的配置文件,carbon-cache和carbon-relay可以安装在同一个主机,carbon.conf中配置如下:
LINE_RECEIVER_INTERFACE = 0.0.0.0
LINE_RECEIVER_PORT = 2003
PICKLE_RECEIVER_INTERFACE = 0.0.0.0
PICKLE_RECEIVER_PORT = 2004
storage-schemas.conf也是个很重要的配置,配置里可以配置多个策略,每个策略只有3行。
1 name,策略标识
2 以pattern=开头的一个正则表达式
3 一个时间的配置规则
例如我现在的配置是这样的;
[default]
pattern = my.com$
retentions = 10s:8d,1m:31d,10m:1y,1h:5y
pattern配置的是必须以my.com结尾,这个好理解,难点在retentions的配置。
Retentions中配置规则如下:
s - second
m - minute
h - hour
d - day
w - week
y - year
10S:8d表示每10秒记录一次保留8天,以此类推剩下的配置,这里为什么要配置不同的策略?其实从粒度上可以看得出来越来越粗旷,这是充分考虑了我们的现实应用、磁盘空间等因素,取其平衡。本质是数据不断插入又不断整合的过程。
storage-aggregation.conf这是个非必须的配置文件,功能与上面的storage-schemas.conf类似,字面意思看得出是做数据从高精度向低精度聚合而用的。虽然是非必须,并不是说聚合是非必需的,因为如果没有聚合Whisper会爆掉,Graphite提供了默认的聚合规则,所以没有storage-aggregation.conf配置也是可以的。
有3种方式可以向Graphite发送数据:文本、Pickle和AMQP
简单直接的方式是发送文本,大批量的数据通过Pickle,并发太大只能通过AMQP异步方式来削峰填谷。
纯文本方式格式:
<metric path> <metric value> <metric timestamp>
<metric path>是命名空间,是用逗号分隔开的keys
<metric value>是收集的value
<metric timestamp>是时间戳,距离1970年1月1日0点的秒数
问题:Graphite明确表示不做收集,我们是通过什么方式把需要的数据吐给Graphite的呢?
我能想到主要有2种模式:纯push模式、pull+push模式。
Push模式,就是在被监控实例上通过脚本主动讲数据吐流给graphite,这种模式理解起来简单,但是缺点是要在每一个数据提供者上做定制化处理。
Pull+push模式是在中间服务器上主动去被监控实例上获取数据,然后吐流给graphite。这种方式的优点是对于被检控方没有污染,是完全绿色的方案。缺点也有,不能太频繁的去pull。
例如我们可以通过python写一个脚本,利用云平台的sdk周期性请求获得想要的数据,然后吐流给Graphite。
Web App:
Web app提供了多种数据表现方式:
url以http://GRAPHITE_HOST:GRAPHITE_PORT/render开始,后面根据实际需求拼接不同的连接。
1 数据统计范围
Graphite的范围分为空间和时间两个维度。
空间,代表要统计哪些target,target对应的值是命名空间。我们把对应的以逗点隔开的命名空间定义为一个path,*代表0-多个字符;{A,B,C}代表字符取值列表,[0-9]中括号代表取值范围。
时间,代表统计的时间范围,由&from=-8d&until=-7d这样来限制,格式比较灵活,也可以&from=20091201&until=20091231这样
From默认是24小时之前,until默认是now。
2 返回类型
graphite的返回类型几乎涵盖了所有的类型:
&format=png
&format=raw
&format=csv
&format=json
&format=svg
&format=pdf
&format=dygraph
&format=rickshaw
调用者根据自己的需要来决定以何种方式来获取response数据。常用的当然是json,因为其灵活度高,虽然graphite提供了png格式的报表,但是建议慎用,因为比较丑。。。我一般是json获取数据然后用echart之类的展示。
3 常用统计运算函数
值:
&target=absolute(Server.instance01.threads.busy)
聚合:
&target=aggregate(host.cpu-[0-7].cpu-{user,system}.value,"sum")
个参数是命名空间表达式,第二个参数支持average, median, sum, min, max, diff, stddev, count, range, multiply, last
平均值:
前面聚合里包含了普通平均值的计算方式,avg()就是aggregate的average方式,这里介绍的是带有过滤条件的更复杂的平均值函数。
&target=averageAbove(server*.instance*.threads.busy,25)
平均值大于某个值的指标才会显示。同理还有averageBelow
别名:
&target=alias(Sales.widgets.largeBlue,"LargeBlue Widgets")
百分比:
&target=asPercent(Server*.connections.{failed,succeeded},Server*.connections.attempted, 0)
求每台机器连接的成功和失败率,默认为0
第二个参数是总数,第三个参数是缺省值,如果没有指定总数百分比的分母就是个参数value自动求和。
积累:
&target=cumulative(Sales.widgets.largeBlue)
统计个数:
&target=countSeries(carbon.agents.*.*)
&target=currentAbove(server*.instance*.threads.busy,50)
只绘制大于某个值的记录,同理还有currentBelow
命名空间剔除
&target=exclude(servers*.instance*.threads.busy,"server02")
Value条件剔除:
&target=filterSeries(system.interface.eth*.packetsSent,'max', '>', 1000)
括号内参数是<命名空间><运算> <比较符> <比较值>
运算符支持:average, median, sum, min, max, diff, stddev, range, multiply & last
比较符支持:=, !=, >, >=, < & <=
Graphite自带了Dashboard,访问url:http://my.graphite.host/dashboard
在Dashboard中可以编辑自己的仪表盘,这里不再详细介绍,因为我们一般是通过前面的API接口来获取Graphite的Json数据或者图表嵌入到自己项目中。
Whisper Database:
数据库分为关系数据库、NoSql数据库、RRD时序数据库
RRD数据库的特性是:环形、大小固定、无需运维
RRD refers to Round Robin Database
Graphite为什么不用已有的RRDtool而是选择自开发一个whisper?
原因一:Graphite给自己的定位是运维专用时序数据库,所以要贴合业务,普通RRD的默认设置不能满足运维的要求,例如延时,如果默认为0肯定不符合我们的预期。
原因二:对接上千个数据结点时RRD过于频繁的存储(例如每秒钟入库1次)对IO压力过大,所以开发了whisper,可以将数据进行处理后延时入库(例如收集上千个数据结点数据后10分钟后聚合一下再入库),这种设计为了减少IO的压力。PS:graphite在设计时当时的RRD并不能满足需求,whisper开发出来之后其它RRD也有了聚合插入的功能,但原因一仍然是Graphite要单独开发一套whisperDB的根本原因。
Whisper的数据在聚合时要求配置的精准度是倍数关系。例如现在配置了大小两个粒度10s和1m,因为1m是10s的整数倍,所以这是合理的。但是如果两个粒度是40s和1m,这样是错误的。
数据库层在聚合时的策略支持以下几种(默认是avarage):
average
sum
last
max
min
Whisper Database的性能比传统RRD慢2-5倍,并不是因为whisper的设计不如RRD,而是因为whisper是用python实现的,而RRD是由C实现的,python的执行效率比C要低的多。
Whisper Database是Graphite的默认存储DB,但并不是的DB,我们也可以使用自己的数据库以及存储方式。Graphite WebApp获取数据的API是通过“finder”接口来实现的,默认的是对接whisper的实现。
STORAGE_FINDERS = (
'graphite.finders.remote.RemoteFinder',
'graphite.finders.standard.StandardFinder',
)
如果使用自己的finder,就需要自己写python脚本,继承CustomFinder,实现里面的find_函数
class CustomFinder(object):
def find_nodes(self, query):
#
这些是非常的用法了,我还是推荐用默认的whisper DB来作为Graphite的存储更方便快捷。
看下我自己代码的例子:
def get_aggrate_metric_data(self, metrics, from_, until,
period, alias, func=None, series_func=None):
# http://172.28.209.218/render?target=alias(summarize(sumSeries(alicloud.*.*.lb.*.network_traffic_in), "1hour"),'total')&format=csv
if func is None:
func = 'avg'
if series_func is None:
series_func = 'sumSeries'
expression = self.alias_template.format(
func=func,
pattern=metrics,
period=period,
alias=alias,
series_func=series_func
)
return self.__get_metric_data(alias, from_, until, expression, period)
def __get_metric_data(self, target, from_, until, expression,
period='1day', func='summarize', format='json'):
'''
@params:
target: graphite metric name # ex: stats.counter.foo
from_: start time # 20181201
util: end time # 20181203
expression: summarize(stats.gauges.aliyun.ggg,"20min")
format: data format # json,xml,csv etc.
@return:
formated json for echart
{
'time': [201911,201912...],
'value': [20,30,...],
}
'''
url = urljoin(self.endpoint, '/render')
print "expression ===", expression
payload = {'target': expression, 'format': format, 'until': until, 'from': from_}
payload_str = "&".join("%s=%s" % (k, v) for k, v in payload.items())
response = requests.get(url, params=payload_str)
data = response.json()
period_format = {'day': '%Y%m%d', 'hour': '%Y%m%d%H', 'min': '%Y%m%d%H%M'}
m = re.search(r'\d+(\w+)', period)
key = m.group(1)
try:
formatter = period_format[key]
except KeyError:
raise ValueError("not supported period: %s" % period)
ret = {}
for entry in data:
ret[target] = []
ret['time'] = []
for point in entry['datapoints']:
value = point[0]
if value is None:
value = 0
m = re.search(r'\d+(\w+)', period)
key = m.group(1)
try:
formatter = period_format[key]
except KeyError:
raise ValueError("not support this period: %s" % period)
x = datetime.datetime.fromtimestamp(
int(point[1])).strftime(formatter)
ret['time'].append(x)
ret[target].append(int(value))
return ret
返回的数据的Json格式如下:
<type 'list'>: [{u'target': u'aliyun.*.*.lb.*.network_traffic_in', u'datapoints': [[52741453320.0, 1530144000], [67990254390.0, 1530147600], [75203783520.0, 1530151200], [84519116310.0, 1530154800], [97207351410.0, 1530158400], [85248715260.0, 1530162000], [77570771850.0, 1530165600], [78157443840.0, 1530169200], [82784259870.0, 1530172800], [93145906620.0, 1530176400], [98472522750.0, 1530180000], [104994759480.0, 1530183600], [113430028800.0, 1530187200], [111290674350.0, 1530190800], [88019724510.0, 1530194400], [59661109860.0, 1530198000], [43395220110.0, 1530201600], [28912292760.0, 1530205200], [22186935360.0, 1530208800], [18953705880.0, 1530212400], [17860729380.0, 1530216000], [21559443900.0, 1530219600], [28923104520.0, 1530223200], [40697908200.0, 1530226800], [57158022330.0, 1530230400], [69985946970.0, 1530234000], [79089390270.0, 1530237600], [87491228640.0, 1530241200], [100534699350.0, 1530244800], [90967098120.0, 1530248400], [83598698910.0, 1530252000], [84985892520.0, 1530255600], [14350187070.0, 1530259200]]}]
