目录
关于 Pandas 和 R
比较数据操作
用于数据操作的 R 与 Pandas
关于 Pandas 和 R
让我们简要介绍一下 R 和 Pandas。
R 编程语言
我们可以将 R 视为 S 语言的一种实现,它是一种专门设计用于数据统计和图形分析的语言和环境。使用 R 语言,我们可以利用各种统计分析技术,如线性或非线性建模、测试、聚类、分类等。该语言还提供了各种功能,我们还可以使用这些功能执行图形分析。使用 R 语言,我们可以生成任何数据的高度交互的图。
在本文中,我们将讨论可用于数据操作的 R 语言工具或包。
关于Pandas
Pandas是 python 中的一个库,用于许多与数据相关的任务,例如数据操作和转换。我们在 Pandas 中使用表格形式的数据。通过这些任务,我们还可以使用 Pandas使用 Pandasql进行数据仓库。当我们将数据移入或移出进程时,Pandas 下的功能可用于检查数据。
通过查看以上几点,我们可以说 Pandas 是 python 中的工具包或库,而谈到 R,它本身就是一门语言,并且在其下拥有许多工具包,用于执行与数据相关的任务。在本文中,我们将根据数据相关任务比较 R 语言和 Pandas 库。
让我们开始比较。
比较数据操作
作为数据科学的从业者,我们需要定期使用python和R语言来执行与数据相关的任务。通过本文的这一部分,我们将了解如何在 python 语言中执行使用 R 语言和 Pandas 库的不同操作工具包。
在 R 中,我们主要使用dplyr工具包进行查询、过滤和采样操作。下表展示了我们使用 dplyr 和 Pandas 工具包进行上述简单操作的不同方法。
| R | Pandas |
| dim(data) | data.shape |
| head(data) | data.head() |
| slice(data, 1:10) | data.iloc[:9] |
| filter(data, col1 == 1, col2 == 1) | data.query(‘col1 == 1 & col2 == 1’) |
| data[data$col1 == 1 & data$col2 == 1,] | data[(data.col1 == 1) & (data.col2 == 1)] |
| select(data, col1, col2) | data[[‘col1’, ‘col2’]] |
| select(data, col1:col3) | data.loc[:, ‘col1′:’col3’] |
| distinct(select(data, col1)) | data[[‘col1’]].drop_duplicates() |
| select(data, -(col1:col3)) | data.drop(cols_to_drop, axis=1) |
| distinct(select(data, col1, col2)) | data[[‘col1’, ‘col2’]].drop_duplicates() |
| sample_n(data, 10) | data.sample(n=10) |
| sample_frac(data, 0.01) | data.sample(frac=0.01) |
让我们根据转换操作来看看 R(dplyr) 和 Pandas 之间的区别。
| R | Pandas |
| arrange(data, col1, col2) | data.sort_values([‘col1’, ‘col2’]) |
| arrange(data, desc(col1)) | data.sort_values(‘col1’, ascending=False) |
让我们根据group-by和summary操作来看看R(dplyr)和Pandas的区别。
| R | Pandas |
| summary(data) | data.describe() |
| gdata <- group_by(data, col1) | gdata = data.groupby(‘col1’) |
| summarise(gdata, avg=mean(col1, na.rm=TRUE)) | data.groupby(‘col1’).agg({‘col1’: ‘mean’}) |
| summarise(gdata, total=sum(col1)) | data.groupby(‘col1’).sum() |
Slicing
我们可以使用 R 中的 c() 函数执行切片操作,例如列选择。在 python 中,我们可以使用 Pandas 来执行此操作。例如,下面的代码可以在 R 中使用列名或整数位置来选择和访问列。
使用column name
data <- data.frame(a=rnorm(5), b=rnorm(5), c=rnorm(5), d=rnorm(5), e=rnorm(5))
data[, c("a", "c", "e")]使用 integer location
data <- data.frame(matrix(rnorm(1000), ncol=100))
data[, c(1:10, 25:30, 40, 50:100)]在 Pandas 中,我们可以使用以下代码行执行相同的操作。
import pandas as pd
import numpy as np
datacolumns=list("abc")
data = pd.DataFrame(np.random.randn(5, 3), columns=columns)
data输出:
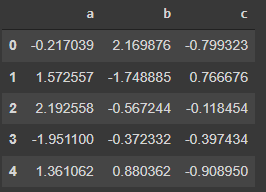
使用column name
data[["a", "c"]]输出
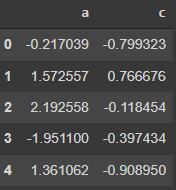
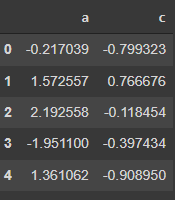
使用location
data.loc[:, ["a", "c"]]输出
Aggregation
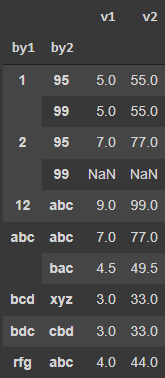
使用 R 语言,我们按 gata 分组以生成子集并使用 by1 和 by2 函数计算每个子集的平均值,如下所示:
data <- data.frame( by1 = c("abc", "bdc", 1, 2, "abc", "bcd", 1, 2, "rfg", 1, "abc", 12), by2 = c("bac","cbd",99,95,"bac","xyz",95,99,"abc",99,"abc","abc") v1 = c(1,3,5,7,8,3,5,NA,4,5,7,9), v2 = c(11,33,55,77,88,33,55,NA,44,55,77,99))aggregate(x=data[, c("v1", "v2")], by=list(mydata2$by1, mydata2$by2), FUN = mean)使用 Pandas,我们可以使用以下方式执行此类操作:
data = pd.DataFrame( { "by1": ["abc", "bdc", 1, 2, "abc", "bcd", 1, 2, "rfg", 1, 'abc', 12], "by2": ["bac","cbd",99,95,"bac","xyz",95,99,"abc",99,"abc",'abc',], "v1": [1, 3, 5, 7, 8, 3, 5, np.nan, 4, 5, 7, 9], "v2": [11, 33, 55, 77, 88, 33, 55, np.nan, 44, 55, 77, 99], }) data输出
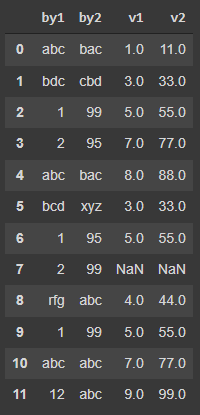
g = data.groupby(["by1", "by2"])g[["v1", "v2"]].mean()输出
查询功能
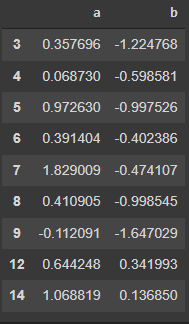
在 R 语言中,我们需要使用子集函数对数据集执行条件查询。下面的代码是这个函数的一个例子。
data <- data.frame(a=rnorm(15), b=rnorm(15))subset(data, a >= b)data[data$a >= data$b,]我们正在提取列 a 的值小于列 b 的行。
使用 Pandas,我们可以使用查询功能执行此操作。
data = pd.DataFrame({"a": np.random.randn(15), "b": np.random.randn(15)})data.query("a >= b")输出
用于数据操作的 R 与 Pandas
使用以上几点,我们讨论了如何使用 Python 中的 Pandas 和 R 的工具包执行各种数据分析。我们发现在 R 中,包是围绕语言传播的,我们需要在本地机器上单独安装它们。当我们将 Pandas 用于类似目的时,我们可以在托管意义上拥有所有功能,或者我们可以说这些功能在一个地方,我们不需要寻找其他工具。R 语言对数据分析有好处的一件事是 R 的速度及其比 Pandas 更加用户友好的界面。关于 R 语言,我们可以说它没有 python 语言那么复杂。R 和 Pandas 都各有所长。
后的话
在本文中,我们讨论了 R 和 Pandas 的比较。总之,我们可以说 R 是一种编程语言,而 Pandas 是一种库。使用 R 的包,我们可以执行不同的操作,而 Pandas 帮助我们执行不同的操作。本教程将帮助初学者了解两者之间的区别,也有助于轻松迁移。
参考:
Link for the codes。
Comparison with R / R libraries
来自:Linux迷
链接:https://www.linuxmi.com/r-using-pandas-data.html
