Presto SQL的核心要素
Presto设计了Connector、Catalog、Schema、Table这4个概念来定义SQL计算中数据源表。
Connector:Connector连接数据源与Presto,在Presto中新增Catalog时,都需要指定这个Catalog对应的Connector名称,如下,我们新增了一个Catalog(name = taobao),它对应的数据源是mysql:
// etc/catalog/taobao.properties
connector.name=mysql
connection-url=jdbc:mysql://mysql:13306
connection-user=test
connection-password=testCatalog:一个数据源中的所有数据的集合,一个Catalog中可以包含多个Schema。
Schema: 等同于关系型数据库中的database,一个Schema中可以包含多个Table。
Table:等同于关系型数据库中的table。在Presto系统中,确定一个表的方式是用<catalog>.<schema>.<table>这样的三元组来表达(英文为:Fully Qualified Name)。例如,假设有catalog = taobao,它包含了schema = orders,这个schema包含了 table = payment:
select * from taobao.orders.payment;也正是因为这种特性,Presto支持多个数据源之间的关联计算,即在SQL中直接用Join算子来连接多个不同catalog的table,完成SQL计算。
如何运行一个Presto SQL
如果想提交运行一个SQL,有很多种方式:
种:官方命令行工具SQL Client
首先到https://prestosql.io/download.html下载“Command Line Interface”,启动之前需要有Java运行环境,确保系统环境PATH中有Java。
mvn presto-cli-339-executable.jar presto
chmod +x presto
./presto --server localhost:8080 --catalog hive --schema default执行上面命令,启动presto命令行,即可向presto集群中提交SQL。
第二种:JDBC
首先到https://prestosql.io/download.html下载“JDBC Driver”,启动之前需要有Java运行环境,确保系统环境PATH中有Java。
在Java项目中引入依赖:
<dependency>
<groupId>io.prestosql</groupId>
<artifactId>presto-jdbc</artifactId>
<version>339</version>
</dependency>引入依赖后,即可向普通Java程序那样来使用这个Driver来向Presto集群提交SQL,代码很容易搜到,就不在这里赘述了。
第三种:HTTP API
其实,上面种和第二种,它们的底层实现都是调用了Presto Coodinator的HTTP API提交的SQL,所以用户也可以直接调用相关API提交,不过一般不推荐直接这么用, 没什么收益。
第四种:支持Presto作为底层执行引擎的BI工具
某些BI工具,如Superset,支持集成Presto数据源。在Superset的UI上面可以写SQL或者配置图表,将Presto作为底层的数据执行引擎,也是典型的OLAP场景的应用。
常用SQL
我们把SQL分为几种类型来分别介绍:基础SQL、DDL(数据定义)、DML(数据操作)、DQL(数据查询)。基本上90%以上的ANSI SQL Presto都是支持的,使用起来也没有特殊的语法和限制。
- 基础SQL:
查看系统中有哪些catalog,用SHOW CATALOGS;
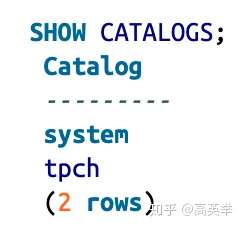
查看指定catalog中有哪些schema,用 SHOW SCHEMAS FROM;

查看指定schema中有哪些table,用SHOW TABLES FROM

如果需要查看指定表的建表结构,用 DESCRIBE(如果想查看建表语句,应该用SHOW CREATE TABLE);

除此之外,还可以使用SHOW FUNCTIONS来查看系统中已经注册的Functions,用USE来切换catalog和schema。
以上的基础SQL,如show xxx,实际上在Presto的底层实现中,会把这样的SQL语句改变为select 语句来执行,如:
改变前的SQL:
show catalogs;
改变后的SQL:
select * from (values ('catalog1'), ('catalog2'), (...)) as catalogs (catalog) order by catalog asc改变后的SQL,其实就是先获取到系统中所有的catalogs,之后用ValueOperator构造一个虚拟的表,再应用select语句。也就是说,在代码实现上,Presto成功复用了select语句的执行逻辑,而不需要为show catalogs这样的SQL编写一套特定的处理逻辑。
- DDL
Presto支持:
- 创建表(Create Table)
- 参照其他表来创建新表(Create Table Like)
- 创建视图(Create View)
- 创建表的同时插入数据(Create Table AS)
如:Create Table 与 Create Table Like:
// SQL1:
CREATE TABLE IF NOT EXISTS orders (
orderkey bigint,
orderstatus varchar,
totalprice double,
orderdate date
)
WITH (format = 'ORC');
// SQL2:创建表bigger_orders时,会根据此处定义的column和orders表中定义的column来创建
CREATE TABLE IF NOT EXISTS bigger_orders (
another_orderkey bigint,
LIKE orders INCLUDING PROPERTIES,
another_orderdate date
);关注一下,上面的SQL,使用到了WITH语法:
WITH ( property_name = expression [, ...] )是否使用WITH是可选的,Presto使用它来在SQL中指定各种参数(property),执行这个SQL时,系统可以根据这些参数,产生不同的行为,相当于不改变SQL语法而扩展了SQL的表达能力。
一些传统的SQL On Hadoop技术,如Hive的做法是自行扩展了SQL的语法,而不是使用WITH,如下面SQL:
CREATE EXTERNAL TABLE page_views(
view_time INT,
user_id BIGINT,
page_url STRING,
view_date DATE,
country STRING
) STORED AS ORC
LOCATION 'hdfs://user/hive/warehouse/analysis/';如果用Presto SQL来表达相同的含义如下:
CREATE TABLE hive.analysis.page_views(
view_time INT,
user_id BIGINT,
page_url STRING,
view_date DATE,
country STRING
)
WITH (
format = 'ORC',
external_location = 'hdfs://user/hive/warehouse/analysis/';
)可以看到Presto使用的是WITH方式,遵循了ANSI SQL标准,更加通用。WITH语法在Presto SQL中有着非常重要的作用,WITH中的的Properties,能表达很多丰富的语义,而且完全是可自定义的。这种WITH用法,与现在比较流行的FlinkSQL完全一样。
还有一种混合了DML和DDL的SQL,支持创建一张表,同时插入数据,它是CREATE TABLE AS SELECT ,用起来也比较方便。如下SQL所示:
CREATE TABLE orders_column_aliased (order_date, total_price)
AS
SELECT orderdate, totalprice
FROM orders需要注意的是,并不是所有的Connector都支持上面介绍的DDL,这个需要看特定Connector的实现,Presto的Connector执行框架为数据源提供了实现Create Table,Create View的机制,但是部分Connector没有实现,因为通过Presto来做Create Table和Create View的需求确实不多,除非是想用Presto做数据的ETL。当然,一些常用的Connector,如Hive Connector已经实现了,通过Presto来对Hive执行查询和数据读写操作也很方便。
- DML
Presto 的Insert、Delete语法就是ANSI标准SQL语法,示例如下:
// SQL1:
INSERT INTO nation (nationkey, name, regionkey)
VALUES (26, 'POLAND', 3);
// SQL2:
INSERT INTO cities VALUES (2, 'San Jose'), (3, 'Oakland');
// SQL3:
DELETE FROM lineitem WHERE shipmode = 'AIR';Presto 不支持Update语法,即使Connector指定为MySQL这种支持Update的数据源,也无法通过Presto来更新MySQL的数据。不过这并不是坏事,毕竟大数据OLAP系统中,核心操作是数据查询分析,数据更新需求几乎没有,而不是OLTP系统那样的CRUD操作。
需要注意的是,并不是所有的Connector都支持Insert,Delete,这个需要看特定Connector的实现,Presto的Connector执行框架为数据源提供了实现Insert,Delete的机制,但是部分Connector没有实现,因为通过Presto来做Insert和Delete的需求确实不多,除非是想用Presto做数据的ETL。当然,一些常用的Connector,如Hive Connector,已经实现了Insert和Delete,通过Presto来对Hive执行查询和数据读写操作也很方便。
- DQL
Presto用户可以使用ANSI标准SQL来查询数据,下面给出了5个示例SQL:
// SQL1:查询表中的指定字段
SELECT name FROM tpch.sf1.region;
// SQL2:查询表中的指定字段,并且做一些条件过滤和排序
SELECT name FROM tpch.sf1.region WHERE name like 'A%' ORDER BY name DESC;
// SQL3:将两个表JOIN在一起输出,FROM后面跟两个表,用逗号连接,等同于A JOIN B这种形式。
SELECT nation.name AS nation, region.name AS region FROM tpch.sf1.region, tpch.sf1.nation WHERE region.regionkey = nation.regionkey AND region.name LIKE 'AFRICA';
// SQL4:用聚合函数(avg)计算给定字段的平均值,并向上取整。
SELECT round(avg(totalprice)) AS average_price FROM tpch.sf1.orders;
// SQL5:用SELECT子查询输出的结果来做条件过滤额
SELECT regionkey, name FROM tpch.tiny.nation WHERE regionkey = (SELECT regionkey FROM tpch.tiny.region WHERE name = 'AMERICA');以上的举例只是基本用法,Presto SQL还有许多高阶和实用的DQL查询,我们将在后面的专栏内容详细介绍。
Presto SQL支持的数据类型
Presto支持的数据类型有:
- 基础数据类型:BOOLEAN、Int(TINYINT、SMALLINT、INT、BIGINT)、浮点(REAL、DOUBLE)、DECIMAL、字符串(VARCHAR、CHAR)
- 集合数据类型:为了支持复杂多样的数据格式表达和计算需求,Presto支持了ARRAY、MAP、JSON、ROW。其中的ROW类型,类似Spark或Flink中的Row,是一个允许有多种数据类型的不同值组成的复合结构。
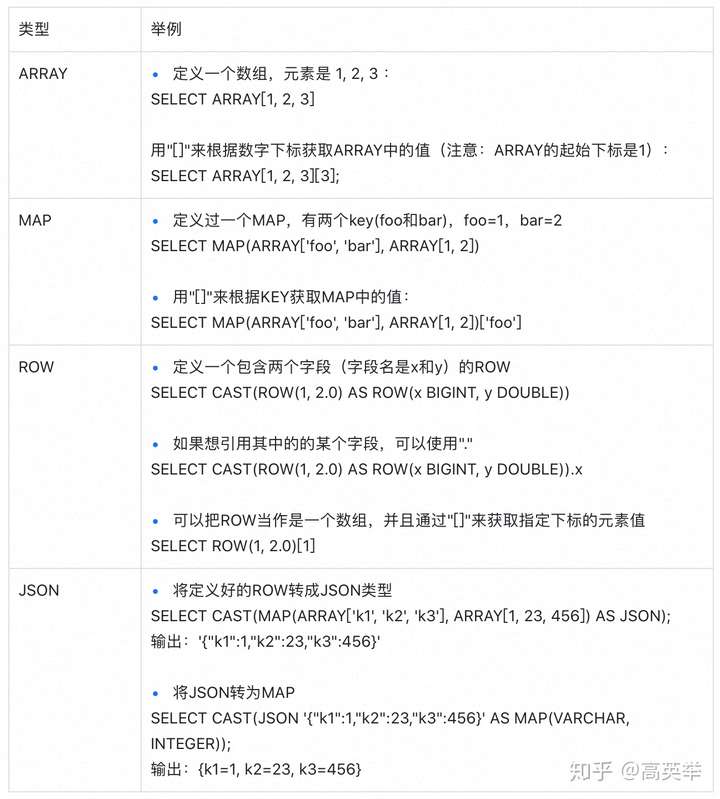
- 时间类型:DATE(表示日期)、TIME(表示时间)、TIMESTAMP(包含了DATE和TIME)、INTERVAL(表示时间偏移)
其中INTERVAL类型,我们举个例子,很快就可以理解它的用途:
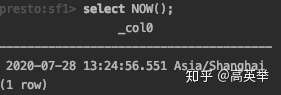
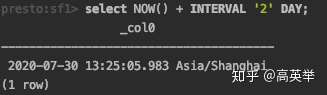
SELECT NOW() + INTERVAL '2' DAY; 的意思是当前的时间再加上两天。
注意一下,Connector对应的数据源也有自己定义数据类型(如mysql connector),对于大部分数据类型,都能找到Connector的数据类型与Presto数据类型的一一对应映射,这种映射关系依赖Connector的具体实现。也有少部分数据类型,可能是Connector数据源支持的而Presto不支持,也可能是Presto支持的但是Connector数据源不支持。使用特定的数据源时,可以先了解一下对应文档和源码。
Presto WebUI
提交了SQL后,如何查看SQL的执行进度和结果呢?这里可以用到Presto WebUI,下面是它的一个截图:
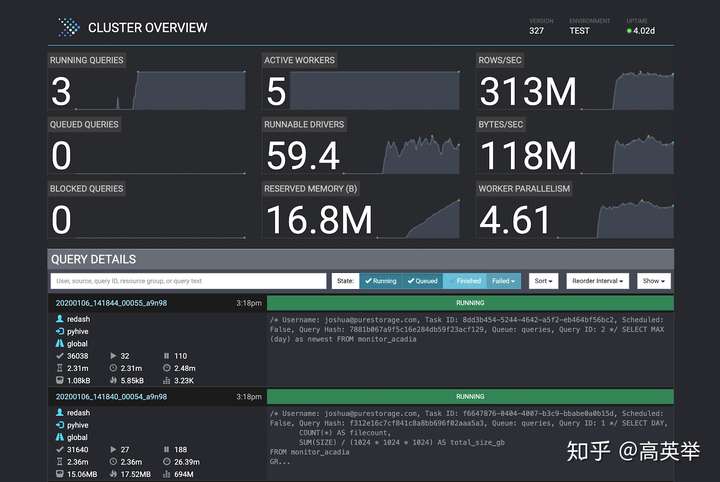
打开WebUI的首页,我们能够看到三个区域:
- 顶部信息区域:展示了Presto的版本,环境、启动时间。
- 集群统计信息:展示了集群的多个核心指标,如正在运行的Query个数(Running Queries)方便监控Query QPS;在线的Worker数量(Active Workers);
- 历史Query列表(Query Details):展示了历史Query的信息,包括QueryID,执行耗时,执行结果和状态,SQL内容,其他可供参考的Query运行时收集到的统计信息等。
- Query详情:在历史Query列表中,点击QueryID将进入指定Query的详情页中,里面的内容和统计数据更加丰富。Presto有一个强大的点是在SQL执行的底层实现中,Stage和Task中有大量的收集Query运行时统计信息的代码逻辑,这些统计信息包括数据量、内存占用、执行耗时等,为慢Query的原因定位和优化提供了较多的便利。不过在实践中来看,如果希望知道这些统计数据对应的准确含义,需要结合着Presto的代码实现来看才行,在Presto的官方文档中,并没有非常详尽的介绍,这算是一个小小的问题。
基本上,数据工程师在查看Presto运行状态,分析慢SQL优化思路时,都需要看Presto WebUI,关于Presto WebUI的其他详情,我们放到了后面的“看懂Presto WebUI”专栏中来做详细介绍。
References:
- 《Presto The Definitive Guide》
- PrestoSQL 官方文档 Presto Documentation
来源 https://zhuanlan.zhihu.com/p/260660023
