近主要在切换工作,很久没有更新了,今天来写一写。
我在阿里云参与的后一个项目"CloudJump: Optimizing Cloud Databases for Cloud Storages"发表在了今年的 VLDB 工业 track 里面。这篇论文的大部分内容来源于 PolarDB 的存储引擎团队在过去的几年里面向云上的 polarfs 在 InnoDB 中所做的工程迭代和优化。有些朋友可能知道我之前是 LSM-tree 组的,那么也就能看出来这些都不是我自己所在团队的工作。大概是一年多前的某天晚上下班的时候,隔壁组的老板在卫生间门口问我有没有兴趣跟他们一起搞事情,出于对他们组工作价值的把握,我当即就答应了。后来我就和隔壁组的豪华阵容一起搞来搞去,前前后后搞了一年多时间,终搞出来这么一篇文章。大佬拿了飞天奖,我……辞职加入初创公司,我们都有光明的未来。
背景交代了,现在我们来讲讲技术。
从 10 到 20 年前开始,传统的 on-premise 数据库架构就已经不能满足数字化企业的业务需求了。在这一点上,Amazon 和淘宝可能走在了前面。不断爆炸性增长的业务数据以及实时处理分析数据的需求,催生了很多在今天大家已经习以为常的数据库架构。在 Amaon Web Services (AWS)上比较典型的有 DynamoDB 和 Aurora,在淘宝这边非严格对标的则是 Tair 和 PolarDB。虽然我本人也就类似问题发过一些 SIGMOD,但我认为今年 ATC 上 DynamoDB 的论文对云数据库应运而生的本质把握得更加清楚。
DynamoDB 强调了一个概念,也是一个主要卖点,即 'consistent performance at any scale',也就是说无论数据库如何 scale,它都能够提供一个稳定、可预期的性能,'single-digit millisecond read and write performance'。这个产品定位非常、非常清晰。至于为什么会有这么样的定位,如果你清楚 Amazon 的电商架构,或者了解淘宝大促背后的内存缓存功臣 Tair,那么应该就很容易理解了。不清楚的话,可以看看上面的论文,也可以思考一下如果你是数据库上层的 app developer,如果底层数据库可以让你无需担心业务数据量的不断增长,同时提供非常稳定、非常低的延迟,难么你是不是可以相对容易地做出用户体验一致的 app,而且性价比还不错。
下面我把这个产品定位翻译成数据库的技术挑战或者设计上的优先级。
必须分布式。单机是不可能完成任务的,AWS 和淘宝都有每秒将近亿级别的事务或者请求量,必须保证低延迟实时处理。如果还上单机,那么势必就像一只羊站在了核爆中心。早年间分布式一致性技术还没有在数据库中普及,像淘宝一开始搞得是使用分库分表的中间件来管理多个独立的单机 MySQL;到今天,Paxos 和 Raft 成熟的理论和技术已经让非常多数据库实现了从单机到分布式的扩展,人人都可以讲五分钟脱口秀,啊不,选主。
存储必须池化。本地盘是不够用的,数据库的容量不能被存储的装机容量限制。同时对数据高可用、高性能、不丢失、低成本等等等等的需求也要求 infra 层面不能依赖本地盘。存储池化可以为单个数据库集群提供上百 TB 的总存储容量,还支持按量付费,用户无需为 always-on 的存储集群付费,也不需要管理硬件替换和故障。这些加起来非常自然地构成了一种存储服务。
而成熟的单机数据库及其存储引擎,全部都是从单机环境下迭代出来的,的就是 InnoDB 里面的 B-tree 一族和 RocksDB 里面的 LSM-tree 了。这些现成的引擎面对上述两个要求,大多捉襟见肘。
传统的存储引擎为了实现较高的 I/O 利用率,会将较为碎片的数据在内容中 buffer 起来,以顺序的方式写入磁盘;而在池化的分布式存储中,一个要执行 I/O 任务的节点可以同时向多个存储节点写入数据,聚合带宽远高于单个本地节点,无需再像本地存储上凑 buffer 了。
数据库往往依赖 cache 来隐藏 I/O 延迟并提供内存级的低延迟。但在分布式条件下,如果每个参与事务或查询处理的节点都有一份本地的 cache,那么 cache 之间的一致性开销所带来的麻烦可能会大于 cache 能够减少的 I/O 开销,尤其是在 RDMA 网络可以大幅降低网络延迟的情况下。如果没有 cache,B-tree 一族无非是需要到存储中读取被访问的 page;而 LSM-tree 麻烦就非常大了,它的读放大会被暴露,而且不仅仅暴露在查询的延迟中,也会被暴露在写入的延迟中(在需要做性、存在性检查的操作中)。
负载均衡相关的问题也会有更大的影响,甚至是用户可感知的影响 。如果存储层用了非常多的存储节点来装 100 TB 的数据,但是热点就集中在其中的某个 10 GB 上,那用户就是花了翡翠白菜的价格买了个烂白菜级别的体验。上文提到的 DynamoDB 在这方面做了非常多的设计。PolarDB 的底座 polarfs 也做了非常多的设计。简单来说,数据库的文件要被散开摆放在多个节点中,还可能被重新 shuffle 来优化平衡,也可能配合 partition 和性能 throttle 等等技术。再比如说,用户一般会显式地知道他的集群买了几个计算节点,云原生数据库往往都会支持一写多读模式下的只读节点水平扩展,但只读节点往往无法满足强一致读的需求。因为同步延迟墙的问题,只有主节点能够为强一致查询和事务请求提高低延迟的服务。如果用户看到他花重金开的只读节点挺闲的,你猜他会不会挑战数据库的弹性价值。
还有更多问题此处不再展开了。
在 CloudJump 这篇文章里面,我们从 update-in-place 的 B-tree 一族和 append-only 的 LSM-tree 两个角度出发,讨论了存储引擎怎么在云上的分布式和池化场景下优化性能和成本,列举了我们所做的许多工程优化细节,虽然都不是特别 fancy 的技术,比如老掉牙的 prefetching,但有效。
从论文的角度,我们需要追求讨论的完备性,处处都会对比 B-tree 和 LSM-tree,看起来是在回答一个存储引擎技术选型的问题。具体的内容欢迎大家到文章里去看。此处我想区分一个概念,就是产品优先的选型和技术优先的选型是不一样的。
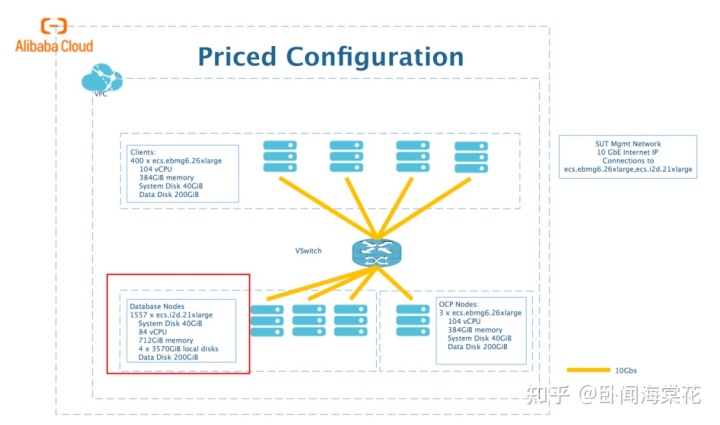
从技术角度来说,LSM-tree 难以提供稳定的性能,其读写放大都太大了。为了做成一个好的产品,像 OB 这样用 LSM-tree 用得比较好的系统,其实是使用了一些成本较高的架构才实现的这一点。比如大家如果点开 OB 的 TPC-C 结果,会发现它的单个数据库节点坐拥 712 GB 内存,而整个集群像这样的大节点一共有 1557 个。如果没有比较大的规模,像 OB 这样的分布式数据库很难实现 8 小时内 tpmC 性能波动小于 2% 这样的性能稳定性要求。在云上,OB 需要使用多租户这样的形式来降低单个用户的使用成本。
OB 做这样的设计是因为他们一开始就假设了充足的内存,充足到一个数据库的内存可以充分缓存一天之内的所有变更,以至于每天只需要在夜深人静的时候做一次 compaction 将内存里面的变更与磁盘上的基线数据合并。这样不仅性能稳定,而且 compaction 对资源的占用也被尽可能地隐藏了,OB 甚至还在同一个 paxos group 内搞轮转合并,进一步隐藏 compaction 的影响。这套设计挺厉害的,就是太贵了。
如果大家了解公共云数据库的话就会知道,绝大部分用户的数据库节点一般是 4C8G 或者 8C16G 这样的小规格,与 OB 的节点规模相差非常大。
同一个 LSM-tree subtable 内部不同的分层之间因为存在数据耦合,为了做一个 get,如果我们只定位一个 extent,是没办法确定其中存储的数据是不是我们所需要的 key 的完整 value。这样不利于 LSM-tree 的数据像 page 一样在分布式存储集群里面自由地摆放。如果 extent 打散了,每次查询的时候都需要做跨界点的 merge。
所以从技术角度上来讲,使用 LSM-tree 的存储引擎在云上并不是多么的选择。
不过从产品角度出发,RocksDB 是拥有活跃开源社区、非常多大厂踩过坑的、拿来就能用的存储引擎。相比深度融合进 MySQL 的 InnoDB,RocksDB 几乎成为了众多新兴开源数据库厂商的靠谱选择。尤其是对于内核人才不足的初创团队来说,如果能快速获得一个稳定的存储底座,就可以使用紧张的人力去开发自己产品更需要的其它组件。而 RocksDB 的成熟度也远高于仍处于初期的自研系统,如果用了 RocksDB,可以有那么好几年都不用操太多存储的心。
说到这里,大家也能发现,其实云上没有一个清清爽爽的存储引擎。我知道有一些研究团队和初创团队希望通过更为直接的方式直接开发出适应云上环境的、可以自由定制优化、便于开发的存储引擎系统,不过目前还没有特别的答卷交出来。这个方向值得持续关注。有志于从事这个方向的话,不如先学一下 rust。
不管是从现有系统中改出一个适应云上环境的存储引擎,还是从头来过,只要上了云,就可以利用云服务的弹性拉开和线下 on-premise 部署的产品之间的差距。所以,上不上云也就成了存储引擎的分水岭。也许到 2025 年,我们会分水岭云这一侧涌现出更多的新系统,而不是只有魔改的 InnoDB 和 RocksDB。
如果我们聚焦在国内近的这些数据库创业公司的话,目前大家基本都在科技树上点亮了计算-存储分离的数据库架构,下一步就是要在计算层、存储层上拼进一步的细功夫了。随着市场和投资人都越来越理性,只是吹吹新技术和新概念是没有办法满足市场需求的,老的 RDBMS 走过的路、解决过的问题,新兴的产品都要一个一个再啃一遍,还要解决自己独有的一些新问题,才能在这行立足站稳。不过站在巨人的肩膀上,现在的技术难度小了很多。
