链接:https://zhuanlan.zhihu.com/p/22427880
来源:知乎
著作权归作者所有。商业转载请联系作者获得授权,非商业转载请注明出处。
Spark入门学习资源:Spark入门系列实验课程。
一、Spark简介
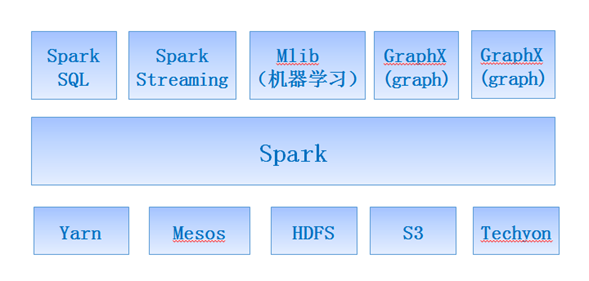
Spark是UC Berkeley AMP lab开发的一个集群计算的框架,类似于Hadoop,但有很多的区别。大的优化是让计算任务的中间结果可以存储在内存中,不需要每次都写入HDFS,更适用于需要迭代的MapReduce算法场景中,可以获得更好的性能提升。例如一次排序测试中,对100TB数据进行排序,Spark比Hadoop快了三倍,并且只需要十分之一的机器。Spark集群目前大的可以达到8000节点,处理的数据达到PB级别,在互联网企业中应用非常广泛。
二、Spark理论导读
学习spark前推荐的理论文章:
2.1 大数据技术生态介绍
写的很好的一篇大数据技术生态圈介绍文章,层次条理分明,内容详尽。推荐必读。
2.2 谁在使用Spark?
这个页面列举了部分使用Spark的公司和组织,有使用场景的介绍,可做简单了解。
2.3 Spark与Hadoop对比
这篇介绍是我看到过详尽的,讲到很多Spark基本原理和对比Hadoop的优势,推荐必读。
三、Spark入门实践教程
有很多想要学习Spark的小伙伴都在自学,实验楼近整理了一系列的spark入门教程,并提供线上配套的练习环境,希望对Spark学习者有所帮助~
Spark线上实验环境:
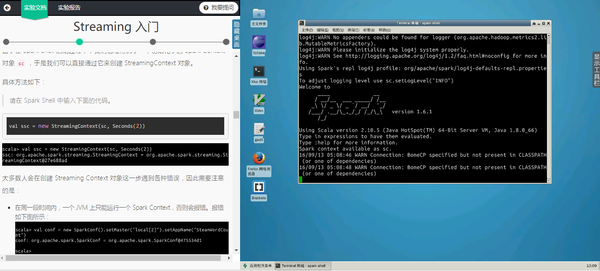
3.1 Spark 讲堂之 SQL 入门
Spark SQL 是一个分布式查询引擎,在这个教程里你可以学习到 Spark SQL 的基础知识和常用 API 用法,了解常用的数学和统计函数。后将通过一个分析股票价格与石油价格关系的实例进一步学习如何利用 Spark SQL 分析数据。
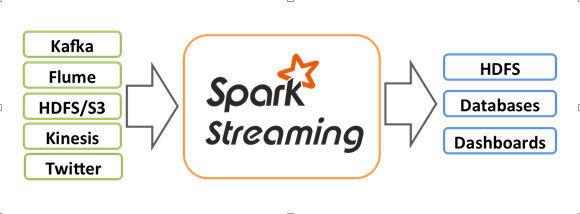
Spark Streaming 适用于实时处理流式数据。该教程带你学习 Spark Streaming 的工作机制,了解 Streaming 应用的基本结构,以及如何在 Streaming 应用中附加 SQL 查询。
Streaming图:
这个教程你可以了解到 Spark 的 MLlib 库相关知识,掌握 MLlib 的几个基本数据类型,并且可以动手练习如何通过机器学习中的一些算法来推荐电影。
GraphX是Spark用于解决图和并行图计算问题的新组件。GraphX通过RDD的扩展,在其中引入了一个新的图抽象,即顶点和边带有特性的有向多重图,提供了一些基本运算符和优化了的Pregel API,来支持图计算。
GraphX包含了一些用于简化图分析任务的的图计算算法。你可以通过图操作符来直接调用其中的方法。这个教程中讲解这些算法的含义,以及如何实现它们。
SparkR是一个提供轻量级前端的R包,集成了Spark的分布式计算和存储等特性。这个教程将以较为轻松的方式带你学习如何在SparkR中创建和操作DataFrame,如何应用SQL查询和机器学习算法等。
DataFrame让Spark具备了处理大规模结构化数据的能力,在比原有的RDD转化方式更加易用、计算性能更好。这个教程通过一个简单的数据集分析任务,讲解DataFrame的由来、构建方式以及一些常用操作。
这个教程通过更加深入的讲解,使用真实的数据集,并结合实际问题分析过程作为引导,旨在让Spark学习者掌握DataFrame的操作技巧,如创建DataFrame的两种方式、UDF等。
3.9 Sqoop 数据迁移工具
Sqoop 是大数据环境中重要的是数据转换工具,这个教程对Sqoop 的安装配置进行了详细的讲解,并列举了Sqoop 在数据迁移过程中基本操作指令。
以上9个教程比较适合有一定的Spark基础的人学习。
3.10 Spark 大数据动手实验
这个教程是一个系统性的教程,总共15个小节,带你亲身体验Spark大数据分析的魅力,课程中可以实践:
Spark,Scala,Python,Spark Streaming,SparkSQL,MLlib,GraphX,IndexedRDD,SparkR,Tachyon,KeystoneML,BlinkDB等技术点,无疑是学习Spark快的上手教程!
这个教程较为系统,非常适合零基础的人进行学习。
希望以上10个教程可以帮助想入门Spark的人技术更上一层楼。
