

OpenAtom OpenHarmony(以下简称“OpenHarmony”)作为一款面向终端设备的操作系统,多媒体业务是其重要的应用场景。在终端多媒体业务中,CMA 内存的使用对业务功能和性能至关重要。本文将从入门开始,带你深入理解 CMA 的设计初衷和工作原理。(备注:在本文描述中,把 CMA 管理的内存区域称为 CMA 区域;把 CMA 的上层使用者称为 CMA 业务。)
为什么需要CMA?
CMA 全称是 Contiguous Memory Allocator(连续内存分配器)。顾名思义它是一种内存分配器,提供了分配、释放物理连续内存的功能。
你可能会有疑问:为什么需要 CMA?这个问题等价于两个子问题:
,为什么业务需要物理地址连续的内存空间?
第二,为什么 buddy 系统无法满足业务的此类连续内存需求?
对于个子问题:主要原因是功能上需要。很多嵌入式设备没有 IOMMU,也不支持 scatter-getter,因此这类设备的驱动程序需要操作连续的物理内存空间才能提供服务。早期,这些设备包括相机、硬件音视频解码器和编码器等,它们通常服务于多媒体业务。虽然,随着移动设备的发展,手机等终端设备已经配置了 IOMMU,但是依然有诸多嵌入式设备没有 IOMMU,需要使用物理地址连续的内存。
此外,物理地址连续的内存 cache 命中率更高,访问速度更优,对业务性能有优势。
对于第二个子问题:虽然 buddy 系统可以通过分配高 order 的页面来分配物理地址连续的内存空间,但是仍旧存在两个不足:
其一,随着系统运行,内存碎片化越来越严重,高 order 内存分配耗时长,且容易分配失败。
其二,如果业务需要的内存大小远超过高 order 的大小,则无法分配。以 ARM64 为例,buddy 系统中高 order 是 10,单次支持分配的大内存大小是 4MB,所以无法为业务分配超过 4MB 物理地址连续的内存。
鉴于上述原因,我们需要 CMA 来实现大块连续物理地址内存的分配。
CMA的设计思路
要实现大块连续物理地址内存的分配,首先面临的问题就是:大块连续的物理内存从哪里找?
这里有两个方案:方案一:
在系统开机时,从整机内存中划分一块出来作为 CMA 区域的预留。
方案二:
当多媒体业务启动时,再清理出一块物理地址连续的空闲内存。
显然,个方案对多媒体业务是可靠、友好的。但是缺点也很明显,即在非多媒体业务场景,预留的 CMA 区域无法得到利用,整机内存利用率变低了。第二个方案对整机友好,因为没有 CMA 预留,整机内存利用率相比方案一更高。但是由于碎片化问题,随着系统运行获取连续物理内存越来越耗时,影响多媒体业务的性能,甚至当内存分配失败时,会导致业务不可用。
综上所述,问题本质上是整机内存利用率与 CMA 业务性能之间的平衡。那么,CMA 如果解决上述问题呢?它采取了折中的办法:
- 开机时,系统预留出 CMA 区域。
- 在 CMA 业务不使用时,允许其他业务有条件地使用 CMA 区域,条件是申请页面的属性必须是可迁移的。
- 当 CMA 业务使用时,把其他业务的页面迁移出 CMA 区域,以满足 CMA 业务的需求。
CMA是如何工作的?
了解了 CMA 的产生背景和设计思路后,下面来看看 CMA 具体是如何工作的。
1. 前置知识
在了解 CMA 如何工作之前,我们需要先了解一点有关迁移类型和 pageblock 的知识。
在 buddy 系统中管理着多种迁移类型(migrate type)的内存页面,不同的迁移类型有各自的用途。举例来说, MIGRATE_MOVABLE 表示保存在其页面的数据是可以被迁移的,这种迁移类型在磁盘缓存、进程页等方面贡献很大。MIGRATE_UNMOVABLE 表示该页面不能被迁移。
pageblock 是一个物理上连续的内存区域,它包含多个页面。例如,在 ARM64 中,一个 pageblock 的大小是 4MB,一个页面的大小为 4KB,每个 pageblock 管理着 1024 个页面。
页面的迁移类型与其所在的 pageblock 的迁移类型一致。当 buddy 系统接收到内存分配请求时,会根据请求标识从对应迁移类型的 pageblock 中分配页面。
当对应迁移类型的 pageblock 中页面不够分配时,buddy 系统会从其他的 pageblock 中获取页面。在一定条件下,这可能会改变一个 pageblock 的迁移类型。比如,请求一个不可移动的页面时,如果系统从 MIGRATE_MOVABLE 迁移类型的 pageblock 中分配页面,会导致这个 pageblock 的迁移类型变成 MIGRATE_UNMOVABLE。这个过程被称为 fallback。
对于 CMA 区域的内存页面,它并不希望被改变迁移类型,因此 CMA 引入了一个新的 MIGRATE_CMA 迁移类型。这种迁移类型具有一个重要的性质:不是所有的内存申请都能到该区域分配内存,只有可移动的页面才能从 MIGRATE_CMA 类型的 pageblock 中分配。
掌握了以上知识之后,下面我们来看看 CMA 的三个主要工作流程:创建 CMA 区域、分配 CMA 内存和释放 CMA 区域内存。
2. 创建CMA区域
创建 CMA 区域的流程如下:
(1)在启动阶段, CMA 通知 memblock 保留一部分内存。
(2)CMA 将这部分内存设置为 MIGRATE_CMA 迁移类型,并其返还给 buddy 系统。
系统中可能存在多个 CMA 区域。这些被预留的 CMA 区域由 buddy 系统管理。buddy 系统可以利用这部分页面用于满足可移动页面的分配请求,这样既保证了预留内存是物理连续的,又提高了整机内存利用率。
3. 分配CMA区域内存
CMA 业务通过 cma_alloc() 接口申请 CMA 区域内存。CMA 区域内存的分配过程如下:
(1)根据分配请求选择要分配的页面范围。
(2)将涉及该页面范围的 pageblock 从 buddy 系统中隔离。由于 buddy 系统不会从 MIGRATE_ISOLATE 迁移类型的 pageblock 分配页面,所以 CMA 将 pageblock 的迁移类型由 MIGRATE_CMA 变更为 MIGRATE_ISOLATE,从而实现隔离。如图 1 所示。

(3)在隔离后,将分配范围内已使用的页面进行迁移处理。迁移过程就是将页面内容复制到其他内存区域,并更新对该页面的引用。
(4)迁移完成后,pageblock 的迁移类型从 MIGRATE_ISOLATE 恢复为 MIGRATE_CMA,后将这些页面返回给调用者。如图 2 所示。
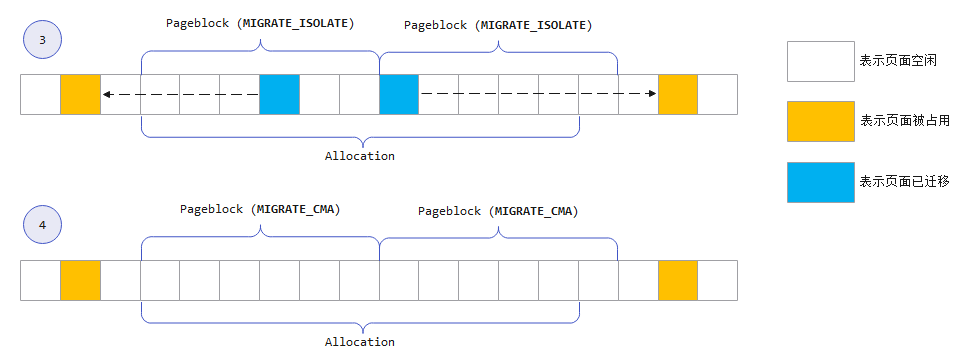
4. 释放CMA区域内存
CMA 业务通过 cma_release () 接口释放 CMA 区域内存。释放过程就是简单迭代这些页面,将它们一一放回 buddy 系统。
代码流程讲解
上面为大家介绍了 CMA 的工作原理,接下来我们来看看 CMA 的代码是如何实现的。
(备注:这部分只是讲解主流程,并未面面俱到展开。具体细节,读者可以自行查阅代码。)
1. CMA管理结构
首先让我们来看一下 CMA 区域在代码中是怎么表示的。
CMA 区域抽象为 struct cma 结构:
struct cma {
unsigned long base_pfn; // 区域的起始页帧号
unsigned long count; // 区域所包含的总页面数量
unsigned long *bitmap; // 位图,用于描述区域的分配单元的分配情况
unsigned int order_per_bit; // 表示位图中一个bit所代表的页面数量(2^order_per_bit)
char name[CMA_MAX_NAME]; // 区域名称
};
extern struct cma cma_areas[MAX_CMA_AREAS]; // CMA区域数组
extern unsigned cma_area_count; // CMA区域总个数CMA 区域通过 bitmap 进行管理,每个 bit 表示 2^order_per_bit 个页面。bit 为 0 则表示空闲,为 1 表示已占用。
系统中存在多个 CMA 区域, cma_areas[MAX_CMA_AREAS] 表示 CMA 区域数组,cma_area_count 表示 CMA 区域总个数。
2. 创建CMA区域
简单介绍完 CMA 的管理结构,下面我们来看创建过程。
CMA 区域的创建常用两种方式:
1)使用 command line 方式:cma=nn[MG]@[start[MG][-end[MG]]]- cma=nn[MG]:用来指定 CMA 区域大小。
- @[start[MG][-end[MG]]]:用来指定可创建 CMA 区域的地址范围。
例如:cma=64M@0x00000000-0x20000000
在内核启动过程中会解析 cmdline 中 CMA 区域配置参数,后通过 cma_init_reserved_mem() 函数完成 CMA 区域的创建,具体代码流程如下(以 ARM 为例):
start_kernel()
`-|setup_arch()
`-|arm_memblock_init()
`-|dma_contiguous_reserve()
`-|dma_contiguous_reserve_area()
`-|cma_declare_contiguous()
`-|cma_declare_contiguous_nid()
`-|cma_init_reserved_mem()2)使用 DTS 方式
这里以共享 CMA 区域(cma-default)创建流程为例:
首先,使用 DTS(Device Tree Source)描述当前要创建的 CMA 区域。
Reserved-memory {
#address-cells = <1>;
#size-cells = <1>;
ranges;
/* global autoconfigured region for contiguous allocations */
linux,cma {
compatible = "shared-dma-pool";
reusable;
size = <0x04000000>;
alignment = <0x2000>;
alloc-ranges = <0x00000000 0x20000000>;
linux,cma-default;
};
};- “linux,cma”为创建的 CMA 区域名称。
- “compatible”属性必须为“shared-dma-pool”。
- “reusable”属性说明 CMA 区域的页面是可以映射建立页表,在 CMA 区域页面闲置时可满足可移动页面请求,提高内存利用率。
- “size”属性表示当前 CMA 区域的大小。
- “alignment”属性指定 CMA 区域的地址对齐大小。
- “alloc-ranges”属性指定可创建 CMA 区域的地址范围。
- “linux,cma-default”属性指定当前区域为共享 CMA 区域。
然后,通过 rmem_cma_setup() 函数中解析 DTS 中的 CMA 区域配置信息,传递参数给 cma_init_reserved_mem() 函数进行 CMA 区域的创建
RESERVEDMEM_OF_DECLARE(dma, "shared-dma-pool", rmem_dma_setup);
rmem_cma_setup()
`-|cma_init_reserved_mem()创建完成后,由于暂时没有设备驱动使用,为了提升内存利用率,需要将这部分内存标记后,归还给 buddy 系统,供 buddy 系统满足可移动页面内存申请。
标记和返还 buddy 系统的过程如下:
core_initcall(cma_init_reserved_areas);
cma_init_reserved_areas()
`-|for (i = ; i < cma_area_count; i++)
`-|cma_activate_area()
`-|for (pfn = base_pfn; pfn < base_pfn + cma->count; pfn += pageblock_nr_pages)
`-|init_cma_reserved_pageblock()
`-|set_pageblock_migratetype(page, MIGRATE_CMA);
|__free_pages(page, pageblock_order);通过 cma_init_reserved_areas() 迭代所有的 CMA 区域,将 CMA 区域以 pageblock 为单位分割,设置 pageblock 为 MIGRATE_CMA 迁移类型,然后通过 _free_pages() 函数将内存页面返还给 buddy 系统。
3)分配CMA区域内存
现在 CMA 区域属于可用状态,我们来看一下如何分配 CMA 区域内存。
cma_alloc()
`-|for (;;)
`-|alloc_contig_range()
`-|start_isolate_page_range()
|__alloc_contig_migrate_range()
|isolate_freepages_range()
|undo_isolate_page_range()这部分流程和前面叙述的工作原理是相对应的。cma_alloc() 函数在 bitmap 中查找满足分配要求的内存区域,使用 alloc_contig_range() 函数进行分配处理。alloc_contig_range() 函数作为分配内存的主要函数,进行如下处理:
(1)通过 start_isolate_page_range() 函数将涉及分配区域的 pageblock 迁移类型更改为 MIGRATE_ISOLATE。
(2)通过 __alloc_contig_migrate_range() 函数将要分配内存范围内的页面进行迁移(将已使用的页面迁移出来)。
(3)isolate_freepages_range() 函数将需要使用的页面从 buddy 系统摘取出来。
后,通过 undo_isolate_page_range() 函数,恢复相关 pageblock 迁移类型。
4)释放 CMA 区域内存
设备驱动在不使用 CMA 区域内存时,可以通过 cma_release () 函数进行释放。释放后的内存又重新回到 buddy 系统,可以继续为整个系统服务。
cma_release()
`-|free_contig_range(pfn, count);
|cma_clear_bitmap(cma, pfn, count);cma_release() 函数通过 free_contig_range() 函数将不使用的内存页面归还到 buddy 系统,再通过 cma_clear_bitmap() 更新 CMA 区域内存使用情况。
OpenHarmony对CMA的增强
当前,CMA 主要存在两个问题:
- CMA 区域内存利用率低。
- 部分 Movable 内存无法迁移导致 cma_alloc 失败
下面我们来详细了解这两个问题,并看看 OpenHarmony 是如何应对这两个问题的。
问题1:CMA区域内存利用率低
当前 Linux 内核 CMA 区域使用策略较为保守,CMA 内存区域利用率低。极端情况下可能出现 CMA 区域内存充足,但非 Movable 申请不到内存的问题(因为使用 CMA 区域的条件是申请页面的属性必须是可迁移的)。
CMA 区域的使用策略主要是指图 3 中的 ① 处。

Linux 5.10 内核的策略是:当 #free_cma > 1/2#total_free 时(CMA 区域空闲量占总内存空闲量的一半以上),Movable 可以申请到 CMA 区域分配。假设物理内存中 CMA、Movable、其他(Unmovable 和 Reclaimable)的量分别是 X、Y、Z,通常情况下 X < Y 且 X<Z。显然,当用户通过 buddy 系统先申请 X 数量的 Movable、再申请 Y+Z 数量的非 Movable 时,就会出现:CMA 区域内存充足,但非 Movable 内存申请不到内存的问题。
随着移动设备多媒体业务的发展,CMA 区域越来越大,因此提高其利用率对系统至关重要。为此,OpenHarmony 将 CMA 使用策略调整为:Movable 申请优先到 CMA 区域分配。这样就可以规避上述问题了。
问题2:部分Movable内存无法迁移导致cma_alloc失败
部分 Movable 内存在某些情况下无法迁移,如果这类内存处于 CMA 区域,会导致 cma_alloc 失败。文章(
https://lwn.net/Articles/636234/)中首先提出该问题,该问题是 CMA 区域的 Movable 内存被长期 pin 住,导致这些内存会变得“不可迁移”。显然要彻底解决问题,必须从 Movable/Unmovable 内存的定义和划分入手,这已经不单是 CMA 要讨论的议题了,有兴趣的同学可以关注 Linux 社区的讨论。
回到 CMA 本身,针对该问题,Linux 社区有多种临时解决方案,比如:
方案1:当 Movable 内存需要被 pin 住时,把它迁移出 CMA 区域。
方案2:
仅允许那些不容易长期被 pin 住的 Movable 申请使用 CMA 区域。
显然这些方案未能从根本上解决 Movable 内存在某些情况下“不可迁移”的问题,所以它们都未能合入 Linux 主线。
OpenHarmony 采用了方案 2 的思路规避该问题,仅将 Movable 申请中的用户态匿名页申请重定向到 CMA 区域分配,因为这类内存比内核态申请的 Movable 迁移成功的概率更大。
图 4 从系统架构的角度展示了 OpenHarmony 中 CMA 内存的使用策略。(图中C/M/U/R分别表示CMA/Movable/Unmovable/Reclaimable。)
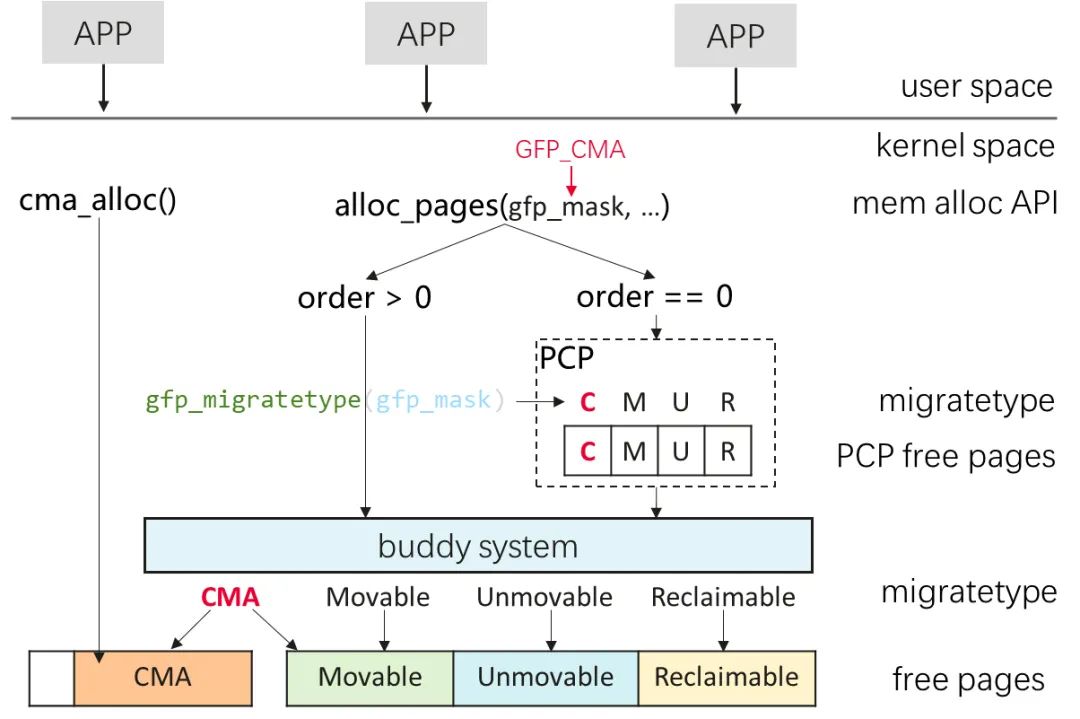
具体实现上,主要包括如下细节:
- 内核态引入 GFP_CMA 标记。触发 page fault 时,对用户态的匿名页内存申请,在 gfp_mask 参数中添加 GFP_CMA 标记。
- 在获取内存申请的 migratetype 时,根据 gfp_mask 中是否携带 GFP_CMA,将 Movable 申请划分成 MIGRATE_CMA 申请(带 GFP_CMA 标记)和 MIGRATE_MOVABLE 申请(不带 GFP_CMA 标记)。
- 对 order 0 申请,PCP 仅允许 MIGRATE_CMA 申请到 CMA PCP list 中分配,如果分配失败,再到 buddy 系统申请。非 MIGRATE_CMA 申请禁止到 CMA PCP list 中分配。
- buddy 系统处理 MIGRATE_CMA 申请时,优先到 CMA 区域分配。如果 CMA 区域空闲内存不足,再到 Movable 区域分配。非 MIGRATE_CMA 申请禁止到 CMA 区域分配。
结束语
感兴趣的小伙伴可以从以下链接获取OpenHarmony源码进行深入了解:
https://gitee.com/openharmony/kernel_linux_5.10/pulls/6源码中 GFP_CMA 标记的引入采用了 Chris Goldsworthy 等人的 Linux 社区 Patch(cma: redirect page allocation to CMA),在此对几位作者表示感谢。
Patch 链接:https://lkml.org/lkml/2020/11/2/646
本文参考资料:
https://lwn.net/Articles/396707/https://lwn.net/Articles/486301/
https://lwn.net/Articles/447405/
https://lwn.net/Articles/684611/
