概述
定义
Apache Hudi 官网地址 https://hudi.apache.org/
Apache Hudi 官网文档 https://hudi.apache.org/docs/overview
Apache Hudi GitHub源码地址 https://github.com/apache/hudi
Apache Hudi是可以在数据库层上使用增量数据管道构建流数据湖,满足记录级更新/删除和更改流,并实现自我管理,支持流批一体并在此基础上持续优化。新版本为0.12.1
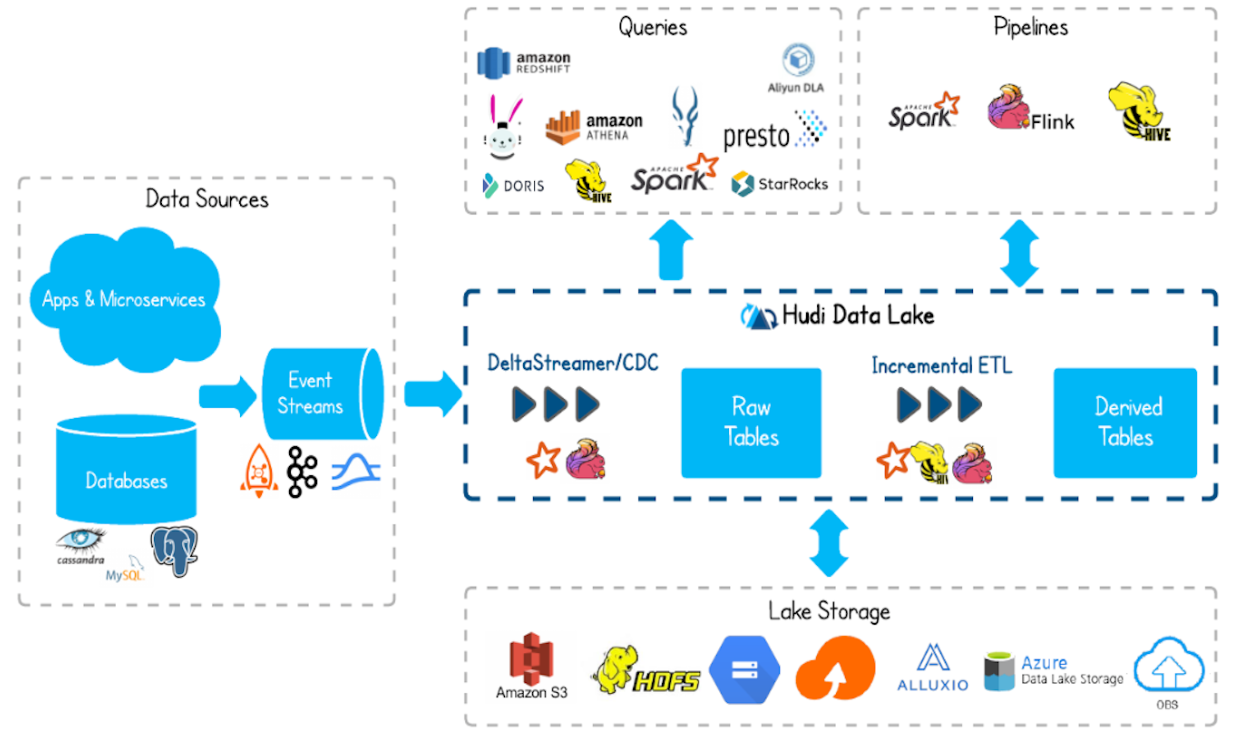
Apache Hudi(发音为“hoodie”)是下一代流数据湖平台,将核心仓库和数据库功能引入数据湖中。Hudi提供了表、事务、高效的upsert /delete、索引、流摄入服务、数据集群/压缩优化和并发性,同时将数据保持为开源文件格式,在分布式文件存储(云存储,HDFS或任何Hadoop文件系统兼容的存储)上管理大型分析数据集的存储;不仅非常适合于流工作负载,还允许创建高效的增量处理管道;得益于其性能优化,使得分析工作能否较好的支持流行的查询引擎如Spark、Flink、Presto、Trino、Hive。总体框架及周边关系如下:
Apache Hudi是一个快速发展的多元化社区,下面为使用和贡献Hudi的小部分公司示例:

发展历史
- 2015 年:发表了增量处理的核心思想/原则(O'reilly 文章)。
- 2016 年:由 Uber 创建并为所有数据库/关键业务提供支持。
- 2017 年:由 Uber 开源,并支撑 100PB 数据湖。
- 2018 年:吸引大量使用者,并因云计算普及。
- 2019 年:成为 ASF 孵化项目,并增加更多平台组件。
- 2020 年:毕业成为 Apache 项目,社区、下载量、采用率增长超过 10 倍。
- 2021 年:支持 Uber 500PB 数据湖,SQL DML、Flink 集成、索引、元服务器、缓存。
特性
- 支持可插拔、快速索引的Upserts/Delete。
- 支持增量拉取表变更以进行增量查询、记录级别更改流等处理。
- 支持事务提交、回滚和并发控制,具有回滚支持的原子式发布数据。
- 支持Spark、 Flink、Presto、 Trino、Hive等引擎的SQL读/写。
- 自我管理小文件,数据聚簇、压缩(行和列数据的异步压缩)和清理,使用统计信息管理文件大小和布局,利用聚类优化数据湖布局。
- 流式摄入,内置CDC源和工具。
- 内置可扩展的存储访问的时间轴元数据跟踪。
- 向后兼容的模式实现表结构变更的支持。写入器和查询之间的快照隔离,用于数据恢复的保存点。
使用场景
- 近实时写入
- 减少碎片化工具的使用,直接使用内置工具。
- 通过CDC工具增量导入RDBMS数据。
- 限制小文件的大小和数量。
- 近实时分析
- 相对于秒级的存储(Druid、时序数据库)节省了资源。
- 提供了分钟级别的时效性,支撑更高效的查询。
- Hudi作为lib,非常轻量。
- 增量pipeline
- 区分arrivetime和eventtime处理延迟数据。
- 更短的调度间隔减少端到端的延迟(从小时级别到分钟级别)的增量处理。
- 增量导出
- 替换部分Kafka的场景,数据导出到在线服务存储如ES。
编译安装
编译环境
组件版本
- Hadoop
- Hive
- Spark(Scala-2.12)
- Flink(Scala-2.12)
准备编译环境Maven
编译Hudi
- 上传源码包
# 可以在github中下载
wget https://github.com/apache/hudi/archive/refs/tags/release-0.12.1.tar.gz
# 解压
tar -xvf release-0.12.1.tar.gz
# 进入根目录
cd hudi-release-0.12.1/
- 修改根目录下的pom文件的组件版本和加速仓库依赖下载,vim pom.xml
<hadoop.version>3.3.4</hadoop.version>
<hive.version>3.1.3</hive.version>
<repositories>
<repository>
<id>nexus-aliyun</id>
<name>nexus-aliyun</name>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
<releases>
<enabled>true</enabled>
</releases>
<snapshots>
<enabled>false</enabled>
</snapshots>
</repository>
</repositories>
- 执行编译命令
mvn clean package -DskipTests -Dspark3.3 -Dflink1.15 -Dscala-2.12 -Dhadoop.version=3.3.4 -Pflink-bundle-shade-hive3
编译报错
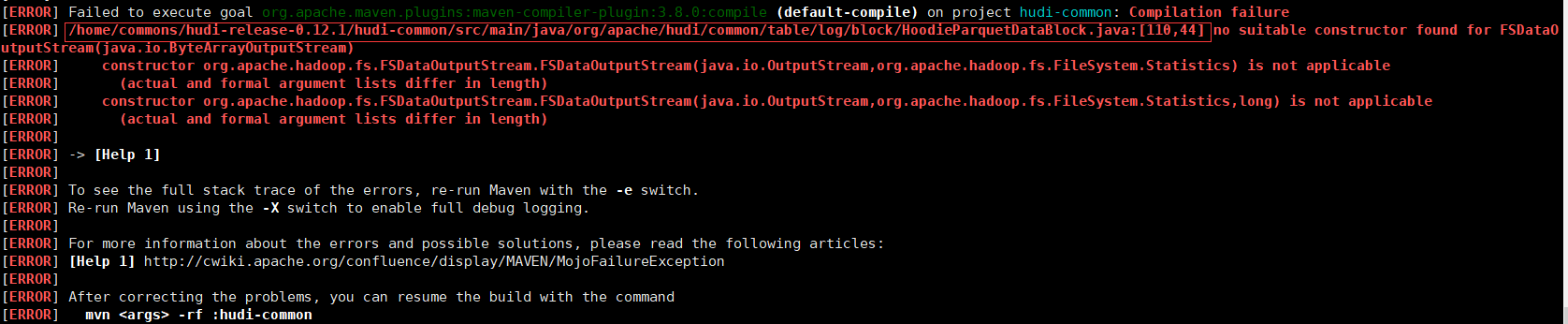
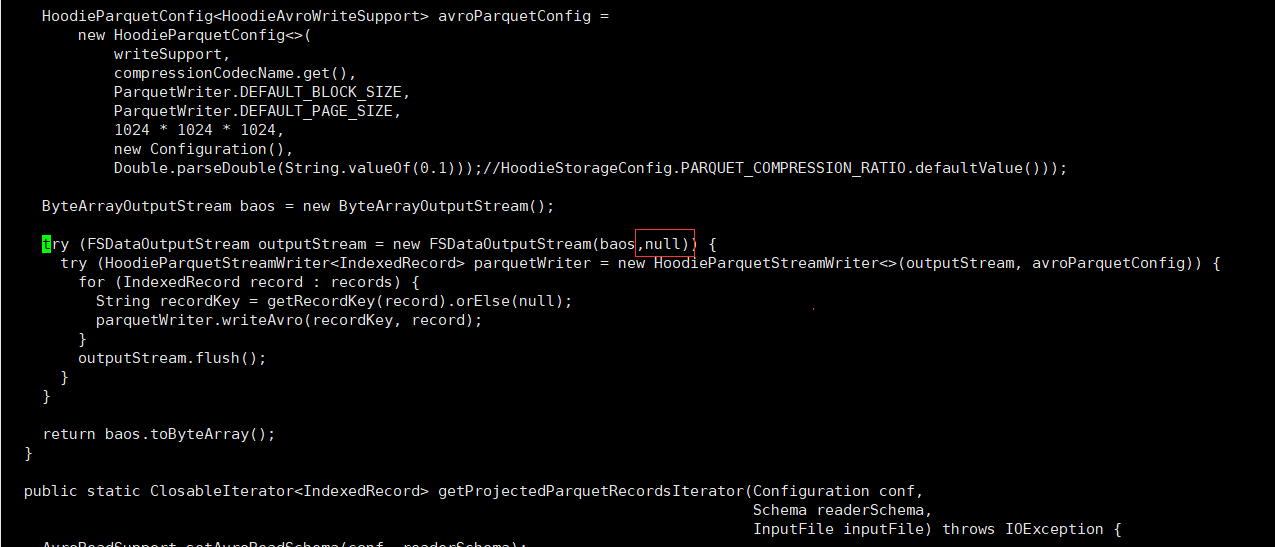
- 修改源码(110行位置),vim hudi-common/src/main/java/org/apache/hudi/common/table/log/block/HoodieParquetDataBlock.java
try (FSDataOutputStream outputStream = new FSDataOutputStream(baos,null)) {
- 手动安装Kafka依赖
由于kafka-schema-registry-client-5.3.4.jar、common-utils-5.3.4.jar、common-config-5.3.4.jar、kafka-avro-serializer-5.3.4.jar这四个包一直没有安装成功,因此我们手动下载安装到本地maven仓库
# 下载confluent包
wget https://packages.confluent.io/archive/5.3/confluent-5.3.4-2.12.zip
# 解压
unzip confluent-5.3.4-2.12.zip
# 通过find命令找到存储位置
find share/ -name kafka-schema-registry-client-5.3.4.jar
# 安装到本地maven仓库
mvn install:install-file -DgroupId=io.confluent -DartifactId=common-config -Dversion=5.3.4 -Dpackaging=jar -Dfile=./share/java/confluent-common/common-config-5.3.4.jar
mvn install:install-file -DgroupId=io.confluent -DartifactId=common-utils -Dversion=5.3.4 -Dpackaging=jar -Dfile=./share/java/confluent-common/common-utils-5.3.4.jar
mvn install:install-file -DgroupId=io.confluent -DartifactId=kafka-schema-registry-client -Dversion=5.3.4 -Dpackaging=jar -Dfile=./share/java/confluent-control-center/kafka-schema-registry-client-5.3.4.jar
mvn install:install-file -DgroupId=io.confluent -DartifactId=kafka-avro-serialize -Dversion=5.3.4 -Dpackaging=jar -Dfile=./share/java/confluent-control-center/kafka-avro-serializer-5.3.4.jar
解决spark模块依赖冲突(修改了Hive版本为3.1.2,其携带的jetty是0.9.3,hudi本身用的0.9.4)存在依赖冲突
- 修改hudi-spark-bundle的pom文件,排除低版本jetty,添加hudi指定版本的jetty。vim packaging/hudi-spark-bundle/pom.xml
在hive-service中376行之后增加如下内容
<exclusion> <artifactId>guava</artifactId> <groupId>com.google.guava</groupId> </exclusion> <exclusion> <groupId>org.eclipse.jetty</groupId> <artifactId>*</artifactId> </exclusion> <exclusion> <groupId>org.pentaho</groupId> <artifactId>*</artifactId> </exclusion>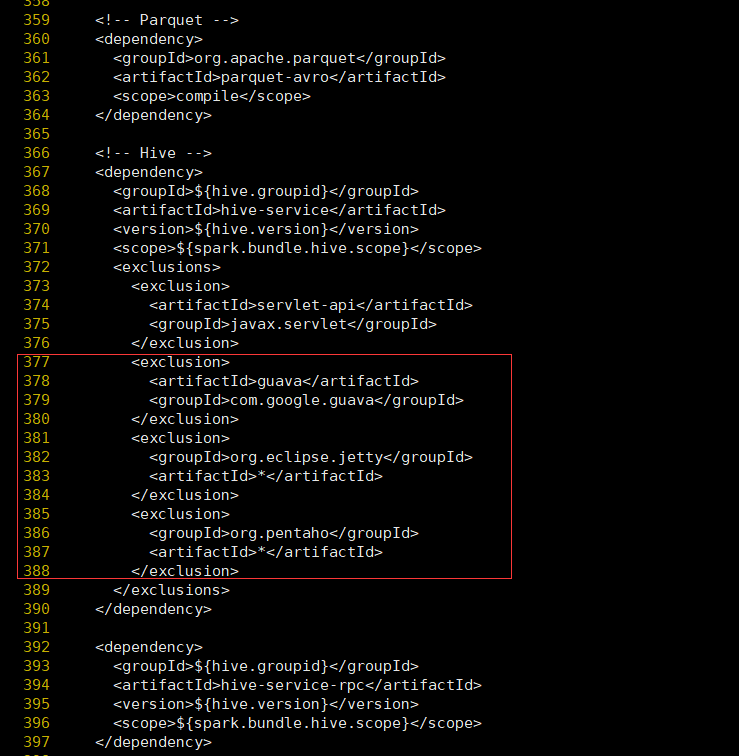
在hive-jdbc中排除下面依赖
<exclusions> <exclusion> <groupId>javax.servlet</groupId> <artifactId>*</artifactId> </exclusion> <exclusion> <groupId>javax.servlet.jsp</groupId> <artifactId>*</artifactId> </exclusion> <exclusion> <groupId>org.eclipse.jetty</groupId> <artifactId>*</artifactId> </exclusion> </exclusions>在hive-metastore中排除下面依赖
<exclusions> <exclusion> <groupId>javax.servlet</groupId> <artifactId>*</artifactId> </exclusion> <exclusion> <groupId>org.datanucleus</groupId> <artifactId>datanucleus-core</artifactId> </exclusion> <exclusion> <groupId>javax.servlet.jsp</groupId> <artifactId>*</artifactId> </exclusion> <exclusion> <artifactId>guava</artifactId> <groupId>com.google.guava</groupId> </exclusion> </exclusions>在hive-commons中排除下面依赖
<exclusions> <exclusion> <groupId>org.eclipse.jetty.orbit</groupId> <artifactId>javax.servlet</artifactId> </exclusion> <exclusion> <groupId>org.eclipse.jetty</groupId> <artifactId>*</artifactId> </exclusion> </exclusions>增加Hudi依赖的jetty版本
<!-- 增加hudi配置版本的jetty --> <dependency> <groupId>org.eclipse.jetty</groupId> <artifactId>jetty-server</artifactId> <version>${jetty.version}</version> </dependency> <dependency> <groupId>org.eclipse.jetty</groupId> <artifactId>jetty-util</artifactId> <version>${jetty.version}</version> </dependency> <dependency> <groupId>org.eclipse.jetty</groupId> <artifactId>jetty-webapp</artifactId> <version>${jetty.version}</version> </dependency> <dependency> <groupId>org.eclipse.jetty</groupId> <artifactId>jetty-http</artifactId> <version>${jetty.version}</version> </dependency>- 修改hudi-utilities-bundle的pom文件,排除低版本jetty,添加hudi指定版本的jetty(否则在使用DeltaStreamer工具向hudi表插入数据时,也会报Jetty的错误)vim ./packaging/hudi-utilities-bundle/pom.xml
在hive-service中396行之后增加如下内容
<exclusion> <artifactId>servlet-api</artifactId> <groupId>javax.servlet</groupId> </exclusion> <exclusion> <artifactId>guava</artifactId> <groupId>com.google.guava</groupId> </exclusion> <exclusion> <groupId>org.eclipse.jetty</groupId> <artifactId>*</artifactId> </exclusion> <exclusion> <groupId>org.pentaho</groupId> <artifactId>*</artifactId> </exclusion>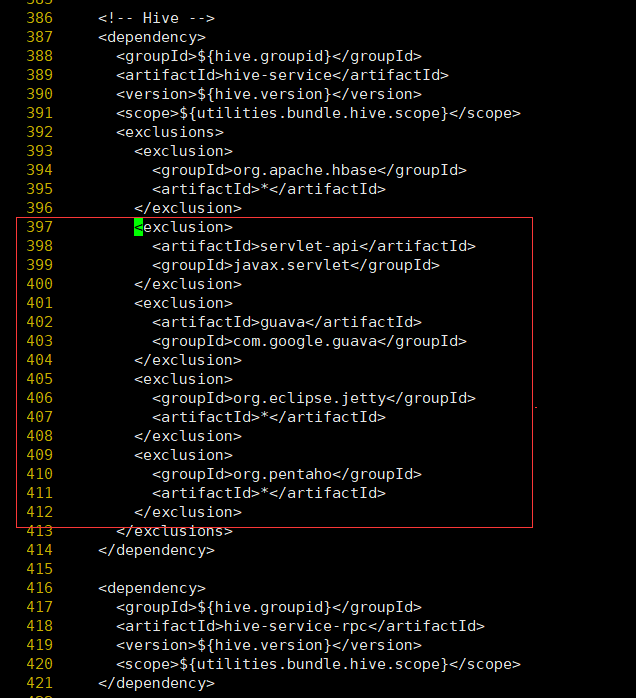
在hive-jdbc中排除下面依赖
<exclusions> <exclusion> <groupId>javax.servlet</groupId> <artifactId>*</artifactId> </exclusion> <exclusion> <groupId>javax.servlet.jsp</groupId> <artifactId>*</artifactId> </exclusion> <exclusion> <groupId>org.eclipse.jetty</groupId> <artifactId>*</artifactId> </exclusion> </exclusions>在hive-metastore中排除下面依赖
<exclusion> <groupId>javax.servlet</groupId> <artifactId>*</artifactId> </exclusion> <exclusion> <groupId>org.datanucleus</groupId> <artifactId>datanucleus-core</artifactId> </exclusion> <exclusion> <groupId>javax.servlet.jsp</groupId> <artifactId>*</artifactId> </exclusion> <exclusion> <artifactId>guava</artifactId> <groupId>com.google.guava</groupId> </exclusion>在hive-commons中排除下面依赖
<exclusions> <exclusion> <groupId>org.eclipse.jetty.orbit</groupId> <artifactId>javax.servlet</artifactId> </exclusion> <exclusion> <groupId>org.eclipse.jetty</groupId> <artifactId>*</artifactId> </exclusion> </exclusions>增加Hudi依赖的jetty版本
<!-- 增加hudi配置版本的jetty --> <dependency> <groupId>org.eclipse.jetty</groupId> <artifactId>jetty-server</artifactId> <version>${jetty.version}</version> </dependency> <dependency> <groupId>org.eclipse.jetty</groupId> <artifactId>jetty-util</artifactId> <version>${jetty.version}</version> </dependency> <dependency> <groupId>org.eclipse.jetty</groupId> <artifactId>jetty-webapp</artifactId> <version>${jetty.version}</version> </dependency> <dependency> <groupId>org.eclipse.jetty</groupId> <artifactId>jetty-http</artifactId> <version>${jetty.version}</version> </dependency>重新执行编译命令,等待5~10分钟时间
- 验证编译:上一步编译成功后,执行hudi-cli/hudi-cli.sh 能进入hudi-cli说明成功

- 编译完成后,相关的包在packaging目录的各个模块中,比如flink与hudi的包
关键概念
TimeLine(时间轴)
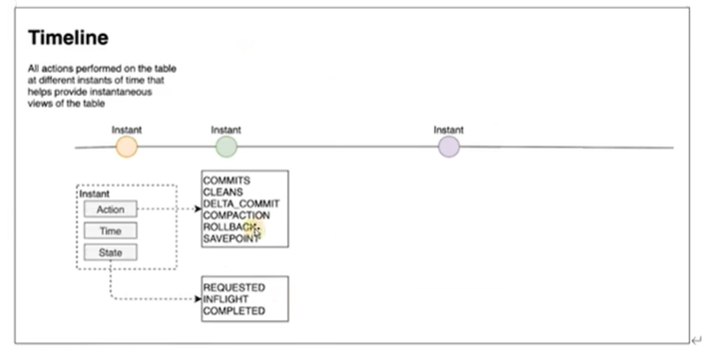
Hudi的核心是维护表上在不同时刻执行的所有操作的时间轴,这有助于提供表的瞬时视图,同时还有效地支持按到达顺序检索数据。TimeLine是Hudi实现管理事务和其他表服务,一个Hudi瞬间由以下几个部分组成:
- Instant action(即时动作):在表上执行的动作类型;Hudi保证在时间轴上执行的操作是原子的,并且是基于即时时间的时间轴一致的。
- COMMITS:表示将一批记录原子地写入表。
- CLEANS:清除表中不再需要的旧版本文件的后台活动。
- DELTA_COMMIT:增量提交是指将一批记录原子地写入MergeOnRead类型的表,其中一些/所有数据可以直接写入增量日志。
- COMPACTION :协调Hudi中不同数据结构的后台活动,例如:将更新从基于行的日志文件移动到柱状格式。在内部,压缩表现为时间轴上的特殊提交。
- ROLLBACK:指示提交/增量提交失败并回滚,删除在此写入过程中产生的所有部分文件。
- SAVEPOINT:将某些文件组标记为“已保存”,以便清理器不会删除它们。在发生灾难/数据恢复场景时,它有助于将表恢复到时间轴上的某个点。
- Instant time(即时时间):即时时间通常是一个时间戳(例如:20190117010349),它按动作开始时间的顺序单调增加。有两个重要时间概念
- Arrival time:数据到达Hudi的时间。
- Event Time:数据记录中的时间。
- State:瞬时的当前状态。
- REQUESTED:表示一个action已经调度,但尚未执行。
- INFLIGHT:表示当前action正在执行。
- COMPLETED:表示时间轴上action已完成。
File Layouts(文件布局)
Apache Hudi 文件在存储上的总体布局方式如下:
- Hudi将数据表组织到分布式文件系统的基本路径下的目录结构中。
- 表被分成多几个分区,这些分区是包含该分区的数据文件的文件夹,非常类似Hive表。
- 在每个分区中,文件被组织到文件组中,由文件ID标识。
- 每个文件组包含几个文件片(FileSlice)。
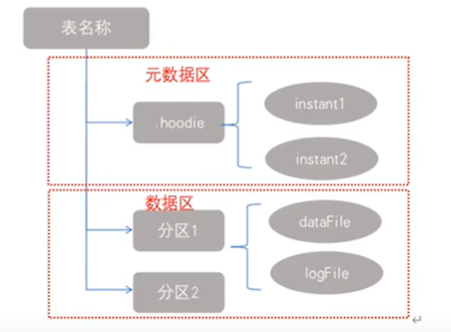
- 每个文件片都包含在某个 commit/compaction 瞬间时间生成的一个BaseFile(MOR可能没有),以及一组LogFile文件(COW可能没有),其中包含自BaseFile生成以来对BaseFile的插入/更新。Hudi将一个表映射为如下文件结构:
- 元数据:.hoodie目录对应着表的元数据信息,包括表的版本管理(Timeline)、归档目录(存放过时的instant也就是版本),一个instant记录了一次提交的行为、时间戳和状态;Hudi以时间轴的形式维护了在数据集上执行的所有操作的元数据。
- 数据:和hive一样,以分区方式存放数据;分区里面存放着BaseFile(.parquet)和LogFile(.log.*)。
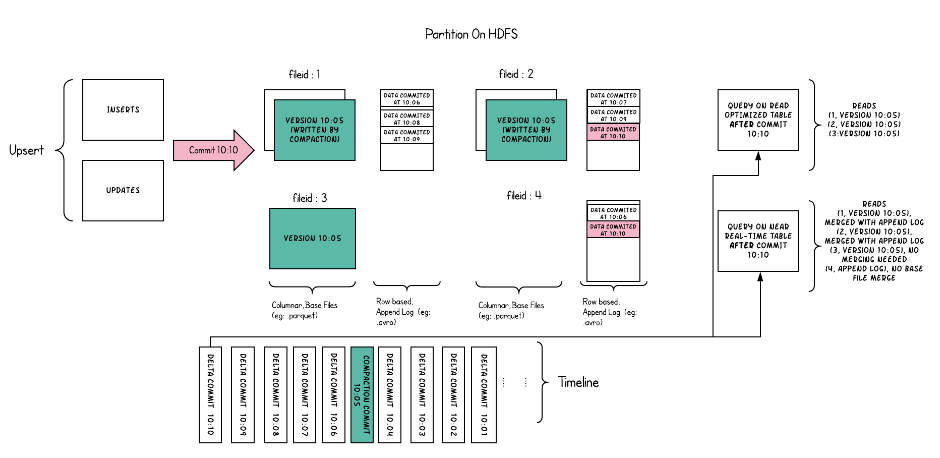
- Hudi采用多版本并发控制(MVCC)
- compaction 操作:合并日志和基本文件以产生新的文件片。
- clean 操作:清除不使用的/旧的文件片以回收文件系统上的空间。
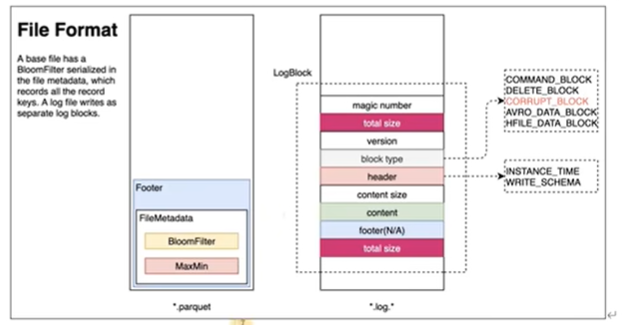
- Hudi的BaseFile在 footer 的 meta记录了 record key 组成的 BloomFilter,用于在 file based index 实现高效率的 key contains 检测。只有不在 BloomFilter 的 key 才需要扫描整个文件------索引检测key是否存在。
- Hudi 的 log 文件通过积攒数据 buffer 以 LogBlock 为单位写出,每个 LogBlock 包含 magic number、size、content、footer 等信息,用于数据读、校验和过滤。
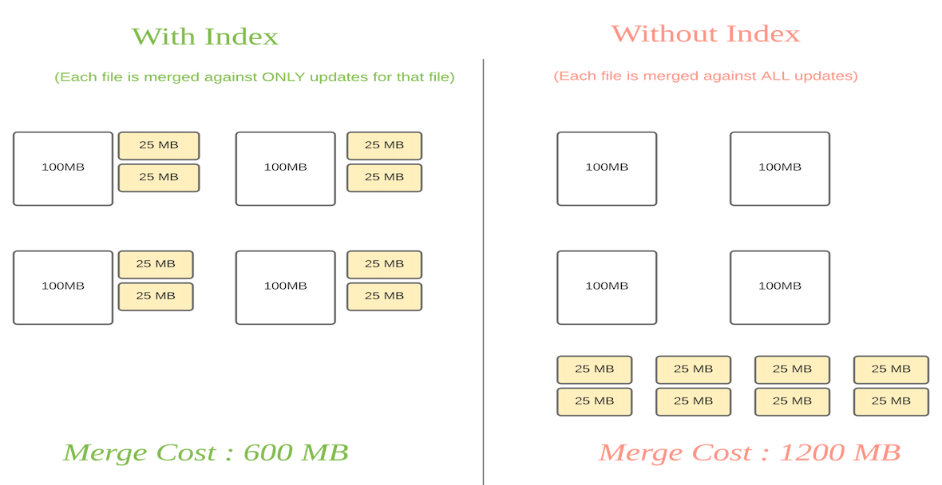
索引
原理:Hudi通过索引机制提供高效的upserts,具体是将hoodie key(record key+partition path)与文件id(文件组)建立映射,映射的文件组包含一组记录的所有版本。
- 数据次写入文件后保持不变,一个FileGroup包含了一批record的所有版本记录。index用于区分消息是insert还是update;此做法的意义在于,当更新的数据到了之后可以快速定位到对应的FileGroup,避免了不必要的更新,只需要在FileGroup内做合并。
- 对于Copy-On-Write tables 可以实现快速的upsert/delete操作,避免了需要针对整个数据集进行关联来确定要重写哪些文件。
- 对于 Merge-On-Read tables 这种设计允许Hudi限制需要合并的任何给定基文件的记录数量。具体地说,给定的基本文件只需要针对作为该基本文件一部分的记录的更新进行合并。
下图中黄色块为更新文件,白色块为基本文件
索引的类型
- Bloom Index(默认):使用布隆过滤器来判断记录存在与否,也可以选择使用record key范围修剪候选文件。
- 优点:效率高,不依赖外部系统,数据和索引保持一致性。
- 缺点:因伪正率问题,还需回溯原文件再查找一遍。
- Simple Index:根据从存储上的表中提取的键,把update/delete操作的新数据和老数据进行join。
- 优点:实现简单,无需额外的资源。
- 缺点:性能比较差。
- HBase Index:管理外部Apache HBase表的索引映射,把index存放在HBase里面,在插入 File Group定位阶段所有task向HBase发送 Batch Get 请求,获取 Record Key 的 Mapping 信息。
- 优点:对于小批次的keys,查询效率高。
- 缺点:需要外部的系统,增加了运维压力。
- 自带实现:您可以扩展这个公共API来实现自定义索引。
- Bloom Index(默认):使用布隆过滤器来判断记录存在与否,也可以选择使用record key范围修剪候选文件。
全局索引/非全局索引
- 全局索引:全局索引在全表的所有分区范围下强制要求键的性,也就是确保对给定的键有且只有一个对应的记录。全局索引提供了更强的保证,但是随着表增大,update/delete 操作损失的性能越高,因此更适用于小表。
- 非全局索引:默认的索引实现,只能保证数据在分区的性。非全局索引依靠写入器为同一个记录的update/delete提供一致的分区路径,同时大幅提高了效率,更适用于大表。
- HBase索引本质上是一个全局索引,bloom和simple index都有全局选项:
hoodie.index.type=GLOBAL_BLOOM hoodie.index.type=GLOBAL_SIMPLE索引的选择策略
- 对事实表的延迟更新:许多公司在NoSQL数据库上存储大量交易数据,例如共享的行程数据、股票交易数据、电商的订单数据,这些表大部分的更新会随机发生在较新的时间记录上,而对旧的数据有着长尾分布型的更新。也即是只有小部分会在旧的分区,这种可以使用布隆索引,如果record key是有序的,那就可以通过范围进一步筛选;如果更加高效的使用布隆过滤器进行比对,hudi缓存了输入记录并且使用了自定义的分区器和统计的规律来解决了数据的倾斜,如果伪正率较高,查询会增加数据的打乱操作,也会根据数据量来调整大小从而达到设定的假阳性率。
- 对事件表的去重:事件流数据无所不在,比如从kafka或者其他消息件发出的数据,插入和更新只存在于新的几个分区中,重复事件较多,所以在入湖之前去重是一个常见的需求;虽然可以使用hbase索引进行去重,但索引存储的消耗还是会随着事件的增长而线性增长,所以有范围裁剪的布隆索引才是佳的解决方案,可以使用事件时间戳+事件id组成的键作为去重条件。
- 对维度表的随机更新:使用布隆裁剪就不合适,直接使用普通简单索引就合适,直接将所有的文件的所需字段连接;也可以采用HBase索引,其对这些表能提供更加优越的查询效率;当遇到分区内数据需要更新时,较为适合采用Merge-On-Read表。
表类型
Hudi表类型定义了如何在DFS上对数据进行索引和布局,以及如何在这种组织之上实现上述原语和时间轴活动(即如何写入数据)。反过来,查询类型定义了如何向查询公开底层数据(即如何读取数据)。Hudi表类型分为COPY_ON_WRITE(写时复制)和MERGE_ON_READ(读时合并)。
Copy On Write
- 使用专门的列式格式存储数据(例如parquet),通过在写过程中执行同步合并,简单地更新文件的版本和重写。
- 只有数据文件/基本文件(.parquet),没有增量日志文件(.log.*)。
- 对于每一个新批次的写入都将创建相应数据文件的版本(新的FileSlice),也就是次写入文件为fileslice1,第二次更新追加操作就是fileslice2。
- data_file1 和 data_file2 都将创建更新的版本,data_file1 V2 是data_file1 V1 的内容与data_file1 中传入批次匹配记录的记录合并。
- cow是在写入期间进行合并,因此会产生一些延时,但是它大的特点在于简单性,不需要其他表的服务,也相对容易调试。
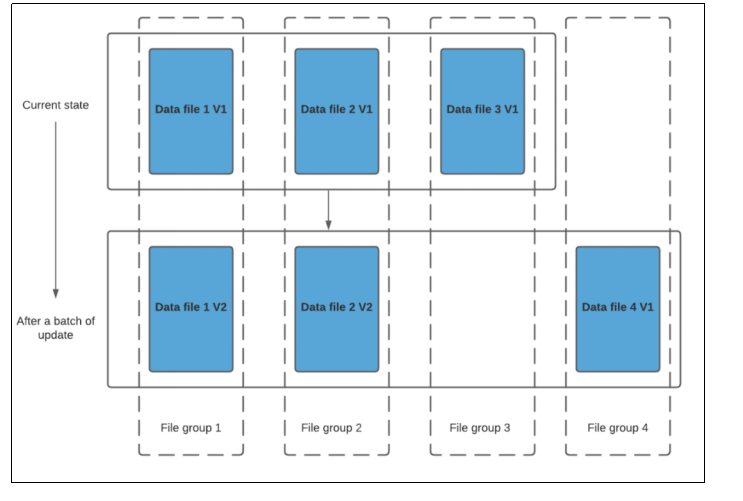
当数据写入写入即写复制表并在其上运行两个查询时
- Merge On Read
- 使用列式存储(如parquet) +基于行(如avro)的文件格式组合存储数据,更新被记录到增量文件,然后压缩以同步或异步生成新版本的列式文件。
- 可能包含列存的基本文件(.parquet)和行存的增量日志文件(基于行的avro格式,.log文件)。
- 所以对于初始的文件也是追加的avro文件,后续修改追加的文件是avro文件,而且只有在读的时候或者compaction才会合并成列文件。
- compaction可以选择内联或者异步方式,比如可以将压缩的大增量日志配置为 4。这意味着在进行 4 次增量写入后,将对数据文件进行压缩并创建更新版本的数据文件。
- 不同索引写文件会有差异,布隆索引插入还是写入parquet文件,只有更新才会写入avro文件,因为当parquet文件记录了要更新消息的FileGroupID;而对于Flink索引可以直接写入avro文件。
在读表上合并的目的是支持直接在DFS上进行接近实时的处理,而不是将数据复制到可能无法处理数据量的专门系统。这个表还有一些次要的好处,比如通过避免数据的同步合并减少了写量的增加,即在批处理中每1个字节的数据写入的数据量。下面为两种类型的查询—快照查询和读取优化查询的图说明
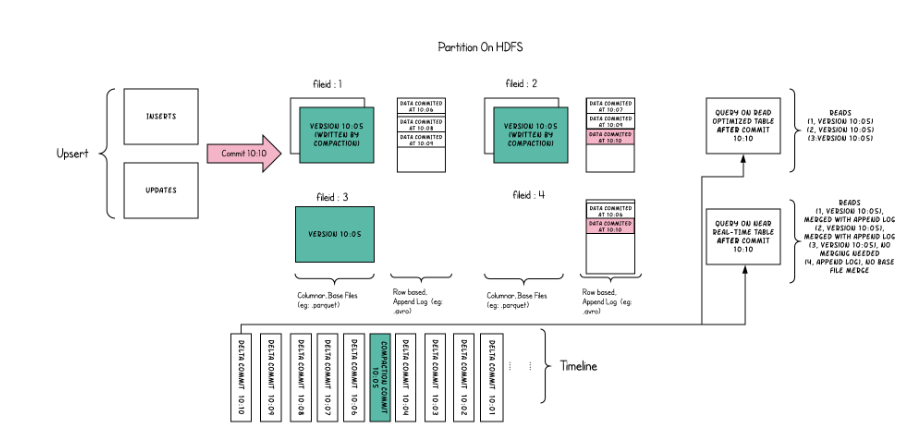
- COW适合批次处理,MOR适合批流一体但更适合流式计算,COW与MOR的对比如下
| CopyOnWrite | MergeOnRead | |
|---|---|---|
| 数据延迟 | 高 | 低 |
| 查询延迟 | 低 | 高 |
| 更新 (I/O)成本 | 高(重写整个 parquet文件) | 低 (追加到增量日志) |
| Parquet 文件大小 | 小 | 较大 |
| 写扩大 | 高 | 低(依赖合并或压缩策略) |
查询类型
查询类型:支持快照查询、增量查询、读优化查询三种查询类型。
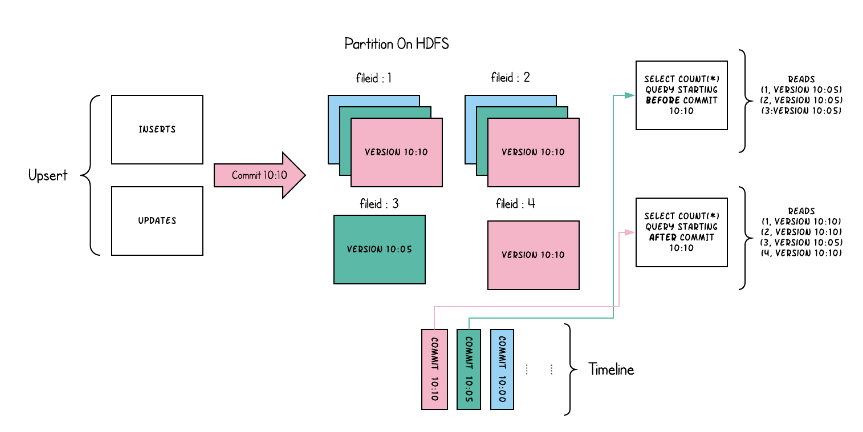
快照查询:提供对实时数据的快照查询,使用基于列和基于行的存储的组合(例如Parquet + Avro)。针对全量新数据COW表直接查新的parquet文件,而MOR表需要做一个合并(新全量数据)。
增量查询:提供一个更改流,其中包含在某个时间点之后插入或更新的记录。可以查询给定commit/delta commit即时操作以来新写入的数据。有效的提供变更流来启用增量数据管道(新增量数据)。
读优化查询:通过纯列存储(例如Parquet)提供出色的快照查询性能。可查看给定的commit/compact即时操作的表的新快照。仅将新文件片的基本/列文件暴露给查询,并保证与非Hudi表相同的列查询性能(并不是全量新),只是合并时文件。
不同表支持查询类型
| Table Type | Supported Query * |
|---|---|
| Copy On Write | Snapshot Queries + Incremental Queries |
| Merge On Read | Snapshot Queries + Incremental Queries + Read Optimized Queries |
不同查询类型之间的权衡
| 快照 | 读优化 | |
|---|---|---|
| 数据延迟 | 低 | 高 |
| 查询延迟 | 高 (合并基本文件/列式文件 + 基于行的 delta 日志文件) | 低(行原始 / 列式文件性能) |
