дёҖпјҡиғҢжҷҜ
1. и®Іж•…дәӢ
д»ҠеӨ©е’ҢеӨ§е®¶иҒҠдёҖеҘ—йқўиҜ•дёӯз»Ҹеёёиў«й—®еҲ°зҡ„й«ҳйў‘йўҳпјҢеҜ№пјҢе°ұжҳҜ дёҙж—¶иЎЁ е’Ң иЎЁеҸҳйҮҸ иҝҷдҝ©зҺ©ж„ҸпјҢеҰӮжһңжңүжңӢеҸӢеңЁйқўиҜ•дёӯеӣһзӯ”зҡ„дёҚеҘҪпјҢеҸҜд»Ҙе°қиҜ•зңӢдёӢиҝҷзҜҮиғҪдёҚиғҪеё®дҪ жҲҗеҠҹиҝҲиҝҮгҖӮ
дәҢпјҡеҲ°еә•жңүд»Җд№ҲеҢәеҲ«
1. еүҚзҪ®жҖқиҖғ
дёҚз®ЎжҳҜ дёҙж—¶иЎЁ иҝҳжҳҜ иЎЁеҸҳйҮҸ йғҪеёҰдәҶ иЎЁ иҝҷдёӘиҜҚпјҢ既然жҸҗеҲ°дәҶ иЎЁ пјҢжҢүжҺЁзҗҶиҮӘ然дјҡиҗҪеҲ°жҹҗдёҖдёӘ ж•°жҚ®еә“ дёӯпјҢеҰӮжһңзңҹеңЁдёҖдёӘ ж•°жҚ®еә“ дёӯпјҢйӮЈиҮӘ然е°ұжңүе®ғзҡ„еӯҳеӮЁж–Ү件 .mdf е’Ң .ldfпјҢйӮЈжҳҜдёҚжҳҜеҰӮжҲ‘жҺЁзҗҶзҡ„йӮЈж ·е‘ўпјҹ жҹҘйҳ… MSDN зҡ„е®ҳж–№ж–ҮжЎЈеҸҜд»ҘеҸ‘зҺ°пјҢдёҙж—¶иЎЁ е’Ң иЎЁеҸҳйҮҸ зЎ®е®һйғҪдјҡдҪҝз”Ё tempdb иҝҷдёӘдёҙж—¶еӯҳеӮЁж•°жҚ®еә“пјҢиҖҢдё” tempdb д№ҹжңүиҮӘе·ұзҡ„ mdfпјҢndfпјҢldf ж–Ү件пјҢжҲӘеӣҫеҰӮдёӢпјҡ
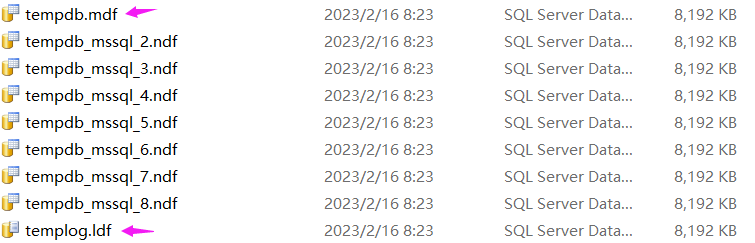
жңүдәҶиҝҷдёӘеӨ§жҖқжғід№ӢеҗҺпјҢжҺҘдёӢжқҘе°ұеҸҜд»ҘиҝӣиЎҢйӘҢиҜҒдәҶгҖӮ
2. еҰӮдҪ•йӘҢиҜҒйғҪеӯҳеӮЁеңЁ tempdb дёӯ ?
иҰҒжғійӘҢиҜҒе…¶е®һеҫҲз®ҖеҚ•пјҢsqlserver жҸҗдҫӣдәҶеӨҡз§Қж–№ејҸи§ӮеҜҹгҖӮ
жҹҘиҜўзҡ„иҝҮзЁӢдёӯи§ӮеҜҹ tempdb дёӢжҳҜеҗҰеӯҳеңЁ
xxxиЎЁгҖӮдҪҝз”ЁеҠЁжҖҒз®ЎзҗҶи§Ҷеӣҫ
sys.dm_db_session_space_usageжҹҘиҜўеҪ“еүҚsqlеҚ з”ЁtempdbдёӢзҡ„ж•°жҚ®йЎөдёӘж•°гҖӮ
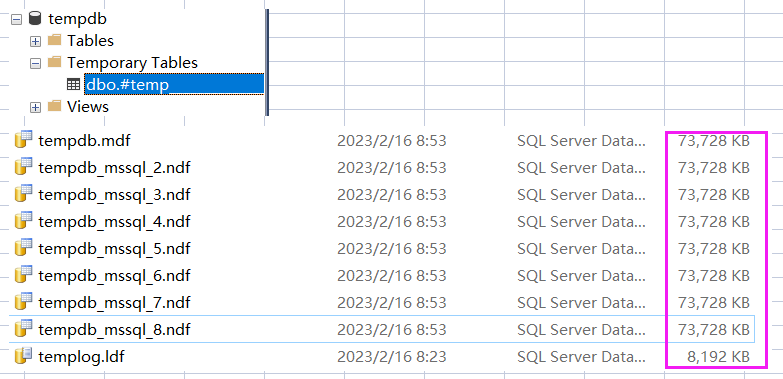
дёәдәҶи®©жөӢиҜ•ж•ҲжһңжҳҺжҳҫпјҢжҲ‘еҲҶеҲ«жҸ’е…Ҙ 10w жқЎи®°еҪ•и§ӮеҜҹ ж•°жҚ®йЎө еҚ з”Ёжғ…еҶөгҖӮ
- дёҙж—¶иЎЁжҸ’е…Ҙ 10w жқЎи®°еҪ•
CREATE TABLE #temp
(
id INT,
content CHAR(4000) DEFAULT 'aaaaaaaaaa'
);
GO
INSERT INTO #temp(id)
SELECT TOP 100000
ROW_NUMBER() OVER (ORDER BY o1.object_id) AS id
FROM sys.objects AS o1,sys.objects AS o2;
GO
SELECT * FROM sys.dm_db_session_space_usage
WHERE session_id=@@SPID;

д»Һеӣҫдёӯзҡ„ user_objects_alloc_page_count=50456 зңӢпјҢеҪ“еүҚзҡ„ insert ж“ҚдҪңеҚ з”ЁдәҶ 50456 дёӘж•°жҚ®йЎөгҖӮ
жҺҘдёӢжқҘеұ•ејҖ tempdb ж•°жҚ®еә“д»ҘеҸҠи§ӮеҜҹеҲ°зҡ„ mdf ж–Ү件еӨ§е°ҸпјҢйғҪйӘҢиҜҒдәҶеӯҳеӮЁеҲ° tempdb иҝҷдёӘз»“и®әгҖӮ
- иЎЁеҸҳйҮҸжҸ’е…Ҙ 10w жқЎи®°еҪ•
еӣ дёәиЎЁеҸҳйҮҸзҡ„зү№ж®ҠжҖ§пјҢиҝҷйҮҢжҲ‘ж•…ж„ҸжҡӮеҒң 1min и®©жҹҘиҜўиҝҹиҝҹеҫ—дёҚеҲ°з»“жқҹпјҢеңЁиҝҷжңҹй—ҙж–№дҫҝеұ•ејҖ tempdbпјҢйҮҚеҗҜ sqlserver жҒўеӨҚеҲқе§ӢзҠ¶жҖҒеҗҺпјҢжү§иЎҢеҰӮдёӢ sqlпјҡ
DECLARE @temp TABLE
(
id INT,
content CHAR(4000) DEFAULT 'aaaaaaaaaa'
);
INSERT INTO @temp(id)
SELECT TOP 100000
ROW_NUMBER() OVER (ORDER BY o1.object_id) AS id
FROM sys.objects AS o1,sys.objects AS o2;
SELECT * FROM sys.dm_db_session_space_usage
WHERE session_id=@@SPID;
WAITFOR DELAY '00:01:00'
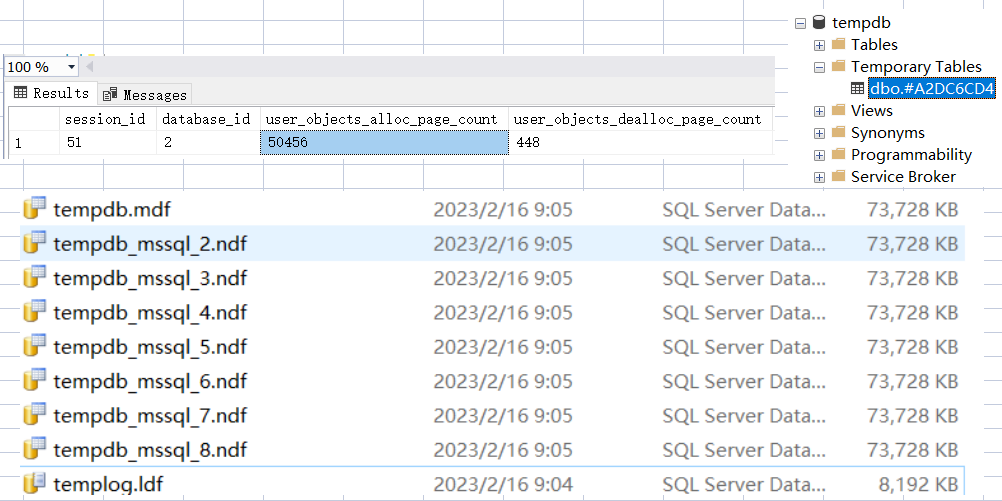
д»ҺеӣҫдёӯеҸҜд»ҘзңӢеҲ° иЎЁеҸҳйҮҸ д№ҹдјҡеҚ з”Ё 5w+ зҡ„ж•°жҚ®йЎө并且数жҚ®ж–Ү件дјҡиҶЁиғҖгҖӮ
3. дёҚеҗҢзӮ№еңЁе“ӘйҮҢ
еҜ№еә•еұӮеӯҳеӮЁжңүдәҶдәҶи§Јд№ӢеҗҺпјҢжҺҘдёӢжқҘжҢүз…§йҮҚиҰҒеәҰд»Һй«ҳеҲ°дҪҺжқҘдәҶи§ЈдёҖдёӢеҢәеҲ«еҗ§гҖӮ
- дёҙж—¶иЎЁжңүз»ҹи®ЎдҝЎжҒҜпјҢиҖҢиЎЁеҸҳйҮҸжІЎжңү
жүҖи°“зҡ„ з»ҹи®ЎдҝЎжҒҜпјҢе°ұжҳҜеҜ№иЎЁж•°жҚ®з»ҳеҲ¶дёҖдёӘ зӣҙж–№еӣҫ жқҘжҺҢжҸЎж•°жҚ®зҡ„еҲҶеёғжғ…еҶөпјҢsqlserver еңЁжӢ©еҸ–иҫғдјҳзҡ„жү§иЎҢи®ЎеҲ’ж—¶дјҡдёҘйҮҚдҫқиө–дәҺиҝҷдёӘ зӣҙж–№еӣҫпјҢз”ұдәҺеұ•ејҖдёҚдәҶ Statistics еҲ—пјҢиҝҷйҮҢе°ұд»Һжү§иЎҢи®ЎеҲ’дёҠи§ӮеҜҹпјҢеҰӮдёӢеӣҫжүҖзӨәпјҡ
- дёҙж—¶иЎЁдёӢзҡ„жү§иЎҢи®ЎеҲ’
йҖүдёӯ SELECT * FROM #temp WHERE id > 10 AND id<20; д№ӢеҗҺзӮ№еҮ» SSMS зҡ„иҜ„дј°жү§иЎҢи®ЎеҲ’жҢүй’®жқҘи§ӮеҜҹдёӢиҜ„дј°жү§иЎҢи®ЎеҲ’пјҢеҸҜд»Ҙжё…жҷ°зҡ„зңӢеҲ° sqlserver зҹҘйҒ“иЎЁдёӯжңүеӨҡе°‘жқЎи®°еҪ•пјҢжҲӘеӣҫеҰӮдёӢпјҡ
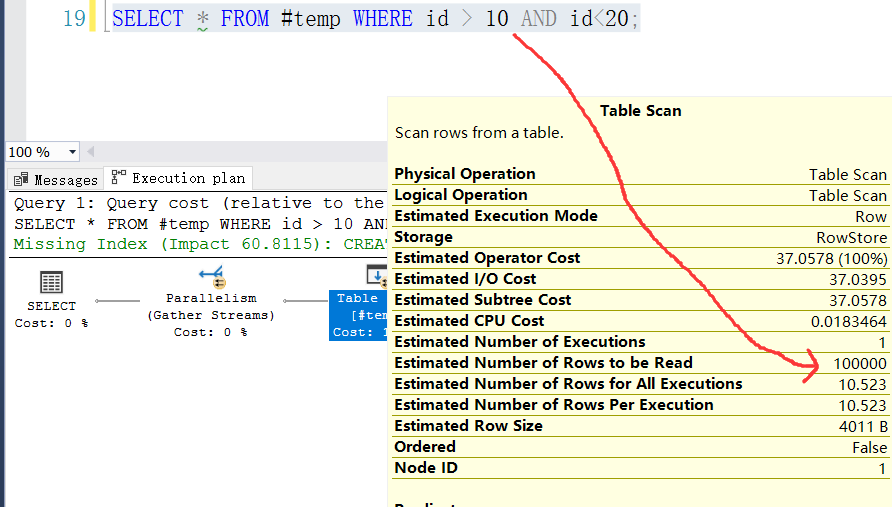
- иЎЁеҸҳйҮҸдёӢзҡ„жү§иЎҢи®ЎеҲ’
з”ұдәҺиЎЁеҸҳйҮҸзҡ„жү№еӨ„зҗҶжҖ§пјҢжҲ‘们用 SET STATISTICS XML ON жҠҠ xml жҹҘиҜўеҮәжқҘпјҢ然еҗҺзӮ№еҮ»и§ӮеҜҹеҸҜи§ҶеҢ–и§ҶеӣҫпјҢеҸӮиҖғsql еҰӮдёӢпјҡ
DECLARE @temp TABLE
(
id INT,
content CHAR(4000) DEFAULT 'aaaaaaaaaa'
);
INSERT INTO @temp(id)
SELECT TOP 100000
ROW_NUMBER() OVER (ORDER BY o1.object_id) AS id
FROM sys.objects AS o1,sys.objects AS o2;
SET STATISTICS XML ON
SELECT * FROM @temp WHERE id > 10 AND id<20;
SET STATISTICS XML OFF
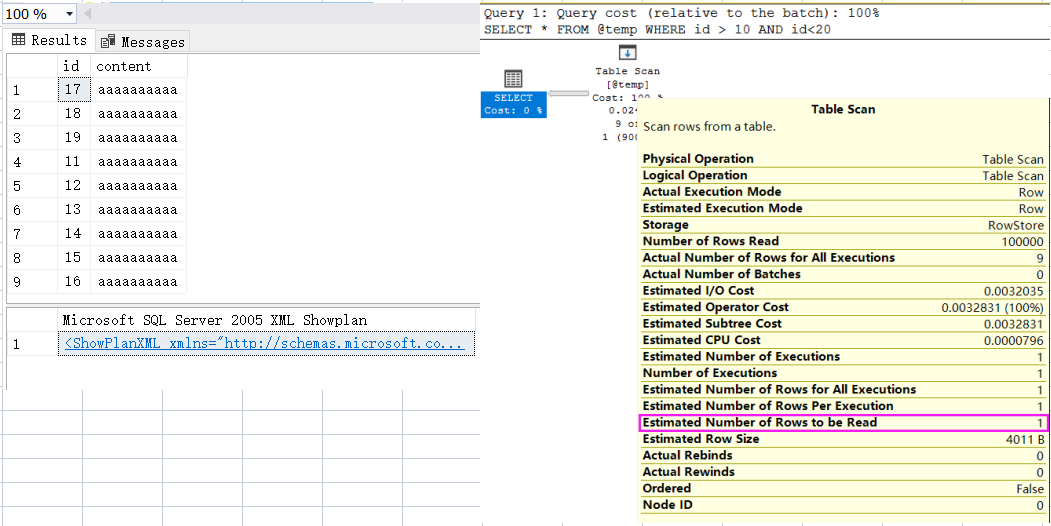
д»ҺеӣҫдёӯеҸҜд»Ҙжё…жҷ°зҡ„зңӢеҲ°пјҢиҷҪ然表еҸҳйҮҸжңү 10w жқЎи®°еҪ•пјҢдҪҶз”ұдәҺжІЎжңүз»ҹи®ЎдҝЎжҒҜпјҢsqlserver д№ҹе°ұж— жі•зҹҘйҒ“иҝҷеј иЎЁзҡ„ж•°жҚ®еҲҶеёғпјҢжүҖд»Ҙе°ұжҢүз…§й»ҳи®ӨеҖј 1 жқЎжқҘи®Ўз®—гҖӮ
д»ҺиҝҷйҮҢеӨ§е®¶д№ҹиғҪзңӢеҫ—еҮәжқҘпјҢеҰӮжһң иЎЁи®°еҪ• зҡ„зңҹе®һжқЎж•° е’Ң й»ҳи®Өзҡ„ 1 дёҘйҮҚеҒҸ移зҡ„иҜқпјҢдјҡз»ҷз”ҹжҲҗжү§иЎҢи®ЎеҲ’ йҖ жҲҗйҮҚеӨ§еӨұиҜҜпјҢиҝҷдёӘеӨ§е®¶дёҖе®ҡиҰҒеҪ“еҝғдәҶгҖӮ
- е…¶е®ғдҪҝз”ЁдёҠзҡ„еҢәеҲ«
йҷӨдәҶдёҠдёҖдёӘжң¬иҙЁдёҠзҡ„дёҚеҗҢпјҢжҺҘдёӢжқҘе°ұжҳҜдёҖдәӣдҪҝз”ЁдёҠзҡ„дёҚеҗҢдәҶпјҢжҜ”еҰӮпјҡ
- дёҙж—¶иЎЁжҳҜ session зә§зҡ„пјҢиЎЁеҸҳйҮҸжҳҜ жү№еӨ„зҗҶ зә§
жүҖи°“зҡ„жү№еӨ„зҗҶпјҢе°ұжҳҜд»Ҙ go дёәз•Ңе®ҡпјҢдёӨиҖ…е°ұжҳҜдҪңз”ЁеҹҹдёҠзҡ„дёҚеҗҢгҖӮ
- дёҙж—¶иЎЁеҸҜд»ҘеҗҺз»ӯдҝ®ж”№пјҢиЎЁеҸҳйҮҸдёҚиғҪеҗҺз»ӯдҝ®ж”№гҖӮ
иҝҷйҮҢзҡ„дҝ®ж”№ж¶үеҸҠеҲ° еӯ—ж®өпјҢзҙўеј•пјҢж•ҙдҪ“дёҠжқҘиҜҙдёҙж—¶иЎЁеңЁдҪҝз”ЁдёҠе’Ңжҷ®йҖҡиЎЁи¶ӢеҗҢпјҢиЎЁеҸҳйҮҸдёҚиғҪиҝӣиЎҢеҗҺз»ӯдҝ®ж”№гҖӮ
дёүпјҡжҖ»з»“
жҖ»зҡ„жқҘиҜҙпјҢиЎЁеҸҳйҮҸ жІЎжңүз»ҹи®ЎдҝЎжҒҜпјҢд№ҹдёҚеҸҜд»ҘеҗҺз»ӯеҒҡ DDL ж“ҚдҪңпјҢиҝҷз§Қжғ…еҶөдёӢ иЎЁеҸҳйҮҸ жҜ” дёҙж—¶иЎЁ жӣҙиҪ»йҮҸзә§пјҢдёҚдјҡжңүеҰӮдёӢеүҜдҪңз”Ёпјҡ
- DDL дҝ®ж”№еҜјиҮҙжү§иЎҢи®ЎеҲ’иҝҮжңҹйҮҚе»ә
- sqlserver еҜ№ з»ҹи®ЎдҝЎжҒҜ зҡ„з»ҙжҠӨеҺӢеҠӣ
е…¶е®һеңЁиҝҷз§ҚдҪңз”ЁеҹҹдёӢй«ҳйў‘зҡ„еҲӣе»әе’ҢеҲ йҷӨиЎЁзҡ„ж“ҚдҪңдёӯпјҢиЎЁеҸҳйҮҸдјҡи®©зі»з»ҹеҺӢеҠӣеҮҸиҪ»еҫҲеӨҡгҖӮ
дҪҶйҳідәӢжҖ»дјҡжңүйҳҙдәӢжқҘеқҮиЎЎе®ғпјҢдёҖж—Ұ иЎЁеҸҳйҮҸ зҡ„и®°еҪ•жқЎж•°дёҘйҮҚеҒҸ移й»ҳи®Өзҡ„ 1жқЎпјҢдјҡжұЎжҹ“sqlserverзҡ„жү§иЎҢи®ЎеҲ’жӢ©еҸ–пјҢеҸҜиғҪдјҡи®©дҪ зҡ„ sql йҒӯеҸ—зҒӯйЎ¶д№ӢзҒҫпјҢжүҖд»ҘдёҖе®ҡиҰҒжҺ§еҲ¶ иЎЁеҸҳйҮҸ зҡ„и®°еҪ•жқЎж•°пјҢеҘҪеңЁзҷҫжқЎеҶ… гҖӮ
еҗҺзҡ„е»әи®®жҳҜпјҡеҰӮжһңдҪ жҳҜдёӘе°ҸзҷҪеҸҜд»Ҙж— и„‘дҪҝз”Ё дёҙж—¶иЎЁ пјҢ90%зҡ„жғ…еҶөдёӢйғҪеҸҜд»ҘеҒҡеҲ°йҖҡжқҖпјҢеҰӮжһңдҪ жҳҜдёӘй«ҳжүӢеҸҜд»ҘиҖғиҷ‘дёҖдёӢ иЎЁеҸҳйҮҸгҖӮ
