部分:Spark优化
1. 并行度
Hudi对输入进行分区默认并发度为1500,以确保每个Spark分区都在2GB的限制内(在Spark2.4.0版本之后去除了该限制),如果有更大的输入,则相应地进行调整。建议设置shuffle的并发度,配置项为 hoodie.[insert|upsert|bulkinsert].shuffle.parallelism,以使其至少达到inputdatasize/500MB。


6. GC调优
请确保遵循Spark调优指南中的垃圾收集调优技巧,以避免OutOfMemory错误。[必须]使用G1 / CMS收集器,其中添加到spark.executor.extraJavaOptions的示例如下:
-XX:NewSize=1g -XX:SurvivorRatio=2 -XX:+UseCompressedOops -XX:+UseConcMarkSweepGC -XX:+UseParNewGC -XX:CMSInitiatingOccupancyFraction=70 -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintGCDateStamps -XX:+PrintGCApplicationStoppedTime -XX:+PrintGCApplicationConcurrentTime -XX:+PrintTenuringDistribution -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/tmp/hoodie-heapdump.hprof
-XX:NewSize=1g
-XX:SurvivorRatio=2
-XX:+UseCompressedOops
-XX:+UseConcMarkSweepGC
-XX:+UseParNewGC
-XX:CMSInitiatingOccupancyFraction=70
-XX:+PrintGCDetails
-XX:+PrintGCTimeStamps
-XX:+PrintGCDateStamps
-XX:+PrintGCApplicationStoppedTime
-XX:+PrintGCApplicationConcurrentTime
-XX:+PrintTenuringDistribution
-XX:+HeapDumpOnOutOfMemoryError
-XX:HeapDumpPath=/tmp/hoodie-heapdump.hprof
上述2个示例一样,一个换行,一个没换行。
7. OutOfMemory错误
如果出现OOM错误,则可尝试通过如下配置处理:spark.memory.fraction=0.2,spark.memory.storageFraction=0.2允许其溢出而不是OOM(速度变慢与间歇性崩溃相比)。
8. 完整的生产配置
spark.driver.extraClassPath /etc/hive/conf
spark.driver.extraJavaOptions -XX:+PrintTenuringDistribution -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:+PrintGCApplicationStoppedTime -XX:+PrintGCApplicationConcurrentTime -XX:+PrintGCTimeStamps -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/tmp/hoodie-heapdump.hprof
spark.driver.maxResultSize 2g
spark.driver.memory 4g
spark.executor.cores 1
spark.executor.extraJavaOptions -XX:+PrintFlagsFinal -XX:+PrintReferenceGC -verbose:gc -XX:+PrintGCDetails -XX:+PrintGCTimeStamps -XX:+PrintAdaptiveSizePolicy -XX:+UnlockDiagnosticVMOptions -XX:+HeapDumpOnOutOfMemoryError -XX:HeapDumpPath=/tmp/hoodie-heapdump.hprof
spark.executor.id driver
spark.executor.instances 300
spark.executor.memory 6g
spark.rdd.compress true
spark.kryoserializer.buffer.max 512m
spark.serializer org.apache.spark.serializer.KryoSerializer
spark.shuffle.service.enabled true
spark.sql.hive.convertMetastoreParquet false
spark.submit.deployMode cluster
spark.task.cpus 1
spark.task.maxFailures 4
spark.yarn.driver.memoryOverhead 1024
spark.yarn.executor.memoryOverhead 3072
spark.yarn.max.executor.failures 100
第二部分,Flink优化
1、Flink可用优化参数
1. 表参数
Memory

Parallelism

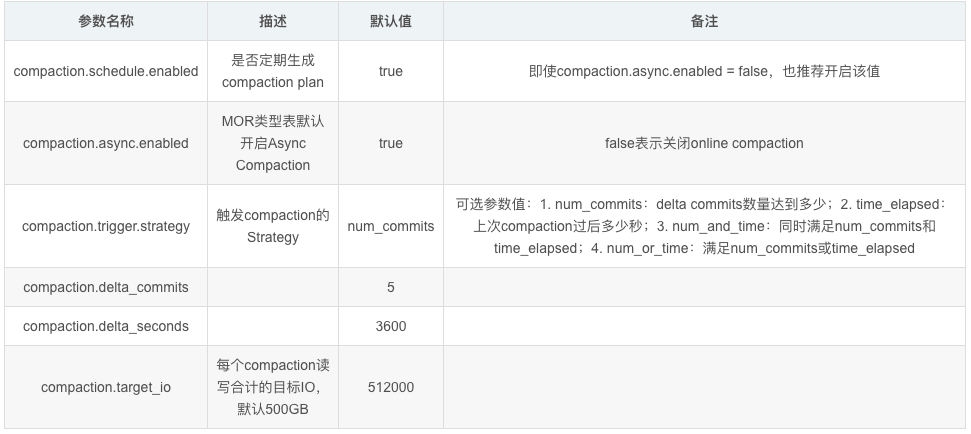
Compaction
只适用于online compaction
2、Flink内存优化
1. 内存参数

2. MOR
state backend 换成 rocksdb (默认的 in-memory state-backend 非常吃内存) 内存够的话,compaction.max_memory 调大些 (默认是 100MB 可以调到 1GB) 关注 TM 分配给每个 write task 的内存,保证每个 write task 能够分配到 write.task.max.size 所配置的大小,比如 TM 的内存是 4GB 跑了 2 个 StreamWriteFunction 那每个 write function 能分到 2GB,尽量预留一些 buffer,因为网络 buffer,TM 上其他类型 task (比如 BucketAssignFunction 也会吃些内存) 需要关注 compaction 的内存变化,compaction.max_memory 控制了每个 compaction task 读 log 时可以利用的内存大小,compaction.tasks 控制了 compaction task 的并发
注意: write.task.max.size - compaction.max_memory 是预留给每个 write task 的内存 buffer
3. COW
state backend 换成 rocksdb(默认的 in-memory state-backend 非常吃内存)。 write.task.max.size 和 write.merge.max_memory 同时调大(默认是 1GB 和 100MB 可以调到 2GB 和 1GB)。 关注 TM 分配给每个 write task 的内存,保证每个 write task 能够分配到 write.task.max.size 所配置的大小,比如 TM 的内存是 4GB 跑了 2 个 StreamWriteFunction 那每个 write function 能分到 2GB,尽量预留一些 buffer,因为网络 buffer,TM 上其他类型 task(比如 BucketAssignFunction 也会吃些内存)。
注意:write.task.max.size - write.merge.max_memory 是预留给每个 write task 的内存 buffer。
