HBase是一个高可靠性、高性能、面向列、可伸缩的分布式存储系统,适用于结构化的存储,底层依赖于Hadoop的HDFS,利用HBase技术可在廉价PCServer上搭建起大规模结构化存储集群。因此,HBase被广泛使用在大数据存储的解决方案中。
1、HBase的优点:
列可以动态增加,并且列为空就不存储数据,节省存储空间
HBase自动切分数据,使得数据存储自动具有水平scalability
HBase可以提供高并发读写操作的支持
2、HBase的缺点:
不能支持条件查询,只支持按照Row key来查询
HBase并不适合传统的事物处理程序或关联分析,不支持复杂查询,一定程度上限制了它的使用,但是用它做数据存储的优势也同样非常明显
因为HBase存储的是松散的数据,所以如果你的应用程序中,数据表每一行的结构是有差别的,那么可以考虑使用HBase。
因为HBase的列可以动态增加,并且列为空就不存储数据,所以如果你需要经常追加字段,且大部分字段是NULL值的,那可以考虑HBase。
因为HBase可以根据Rowkey提供高效的查询,所以如果你的数据(包括元数据、消息、二进制数据等)都有着同一个主键,或者你需要通过键来访问和修改数据,使用HBase是一个很好地选择。
场景一:卖家操作日志
卖家操作日志,顾名思义是用来记录商家操作的系统,从而可以保证商家可以查询自己的各种操作。京东有几十万的商家时时刻刻的进行着各种操作,因此卖家操作日志的特点是:数据量大、实时性强、增多查少。
 ▲图一
▲图一
▲图二
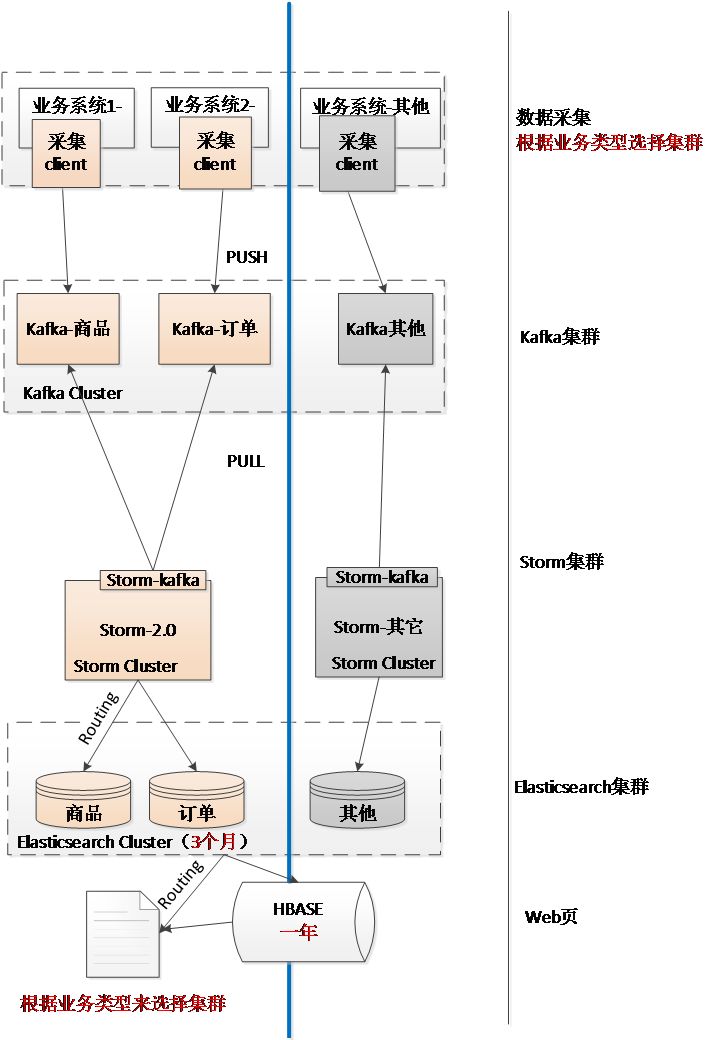
做卖家操作日志初期,将所有的操作日志存放在ES中,操作日志的数据量是非常大的,但当时所能申请到的ES资源有限。当把大量的数据存储到有限的ES集群中时便导致了性能的下降。在这种情况下,选择了只在ES集群中存储近三个月的数据,对其提供灵活的查询,而长期的数据存储使用HBase来进行。这样便可以实现对近期操作灵活展现,对长期数据也有备份。
场景二:京麦消息日志的存储
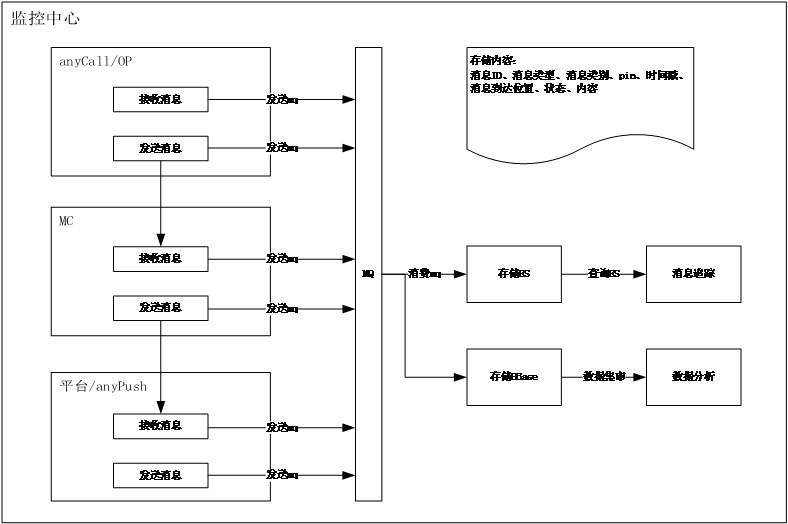
京麦消息日志的存储是属于京麦筋斗云系统(用于打造京麦消息生态系统闭环)不可或缺的一部分,其中包含消息的全链路追踪以及消息的统计分析。京麦消息每天都会有几千万的消息量,如何对消息进行追踪和统计便成为了一个至关重要的问题。
消息追踪要求实时性、多维度查询,因此选择将近一周的消息日志存储在ES。统计分析要求有足够多的数据,因此在将数据存储在ES中的同时也存储在HBase中一份。终再定期将HBase中的数据导入到京东的数据集市中,这样便可以很方便的对京麦消息进行统计分析。
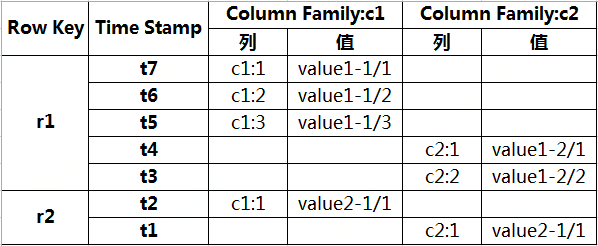
▲HBase数据的概念视图
要使用HBase首先要了解HBase的数据结构:
HBase会存储系列的行记录,行记录有三个基本类型的定义:Row Key、Time Stamp、Column Family。
1、Row Key
与NoSQL数据库一样,Row Key是用来检索记录的主键。访问HBase table中的行,只有三种方式:
通过单个Row Key访问
通过Row Key的range全表扫描
Row Key可以是任意字符串(大长度是64KB,实际应用中长度一般为 10 ~ 100bytes),在HBase内部,Row Key保存为字节数组
在存储时,数据按照Row Key的字典序(byte order)排序存储。设计Key时,要充分排序存储这个特性,将经常一起读取的行存储到一起(位置相关性)。
2、Column Family
HBase表中每个列都必须属于某个列族,列族必须作为表模式定义的一部分预先给出(有点像关系型数据库中的列名,定义完一般情况下就不会再去修改)。
列名以列族作为前缀,每个列族都可以有多个列成员。新的列族成员(也就是列)可以随后按需,动态加入。
Hbase把同一列族里面的数据存储在同一目录下,由几个文件保存。
3、Time Stamp
在HBase每个cell存储单元对同一份数据有多个版本,根据的时间戳来区分每个版本之间的差异,不同版本的数据按照时间倒序排序,新的数据版本排在前面。
1、HBase的模块

1)Master
HBase Master用于协调多个Region Server,侦测各个Region Server之间的状态,并平衡Region Server之间的负载。HBase Master还有一个职责就是负责分配Region给Region Server。HBase允许多个Master 节点共存,但是这需要Zookeeper的帮助。不过当多个Master节点共存时,只有一个Master是提供服务的,其他的Master节点处于待命的状态。当正在工作的Master节点宕机时,其他的Master则会接管 HBase 的集群。
2)Region Server
对于一个Region Server而言,其包括了多个Region。Region Server的作用只是管理表格,以及实现读写操作。Client 直接连接Region Server,并通信获取HBase中的数据。对于Region而言,则是真实存放HBase数据的地方,也就说Region是HBase可用性和分布式的基本单位。如果当一个表格很大,并由多个CF组成时,那么表的数据将存放在多个Region之间,并且在每个Region中会关联多个存储的单元(Store)。
3)Zookeeper
对于HBase而言,Zookeeper的作用是至关重要的。首先Zookeeper是作为HBase Master的HA解决方案。也就是说,是Zookeeper保证了至少有一个HBase Master处于运行状态。并且Zookeeper负责Region和Region Server的注册。其实Zookeeper发展到目前为止,已经成为了分布式大数据框架中容错性的标准框架。不光是HBase,几乎所有的分布式大数据相关的开源框架,都依赖于Zookeeper实现HA。
2、HBase的原理
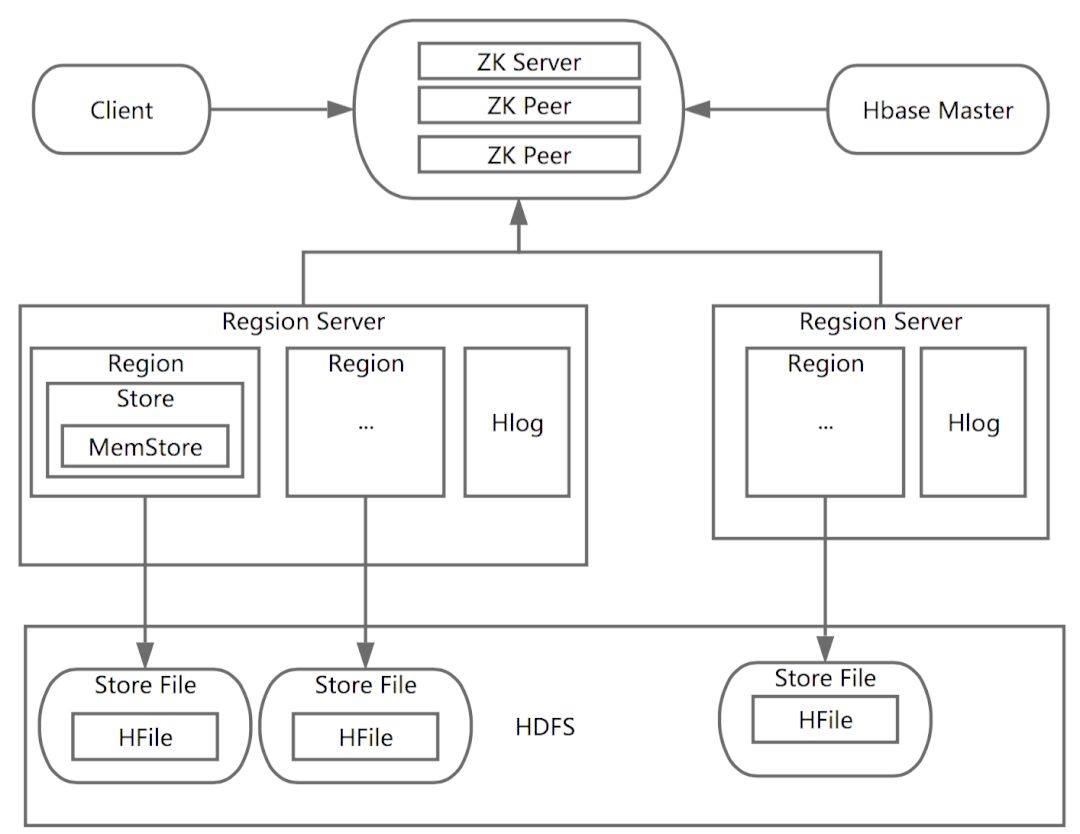
首先需要知道HBase的集群是通过Zookeeper来进行机器之前的协调,也就是说HBase Master与Region Server之间的关系是依赖Zookeeper来维护。当一个Client需要访问HBase集群时,Client需要先和Zookeeper来通信,然后才会找到对应的Region Server。每一个 Region Server管理着很多个Region。对于HBase来说,Region是HBase并行化的基本单元。因此,数据也都存储在Region中。
这里需要特别注意,每一个Region都只存储一个Column Family的数据,并且是该CF中的一段(按Row 的区间分成多个Region)。Region所能存储的数据大小是有上限的,当达到该上限时(Threshold),Region会进行分裂,数据也会分裂到多个Region中,这样便可以提高数据的并行化,以及提高数据的容量。
每个Region包含着多个Store对象。每个Store包含一个MemStore,和一个或多个HFile。MemStore便是数据在内存中的实体,并且一般都是有序的。当数据向Region写入的时候,会先写入MemStore。当MemStore中的数据需要向底层文件系统倾倒(Dump)时(例如MemStore中的数据体积到达MemStore配置的大值),Store便会创建StoreFile,而StoreFile就是对HFile一层封装。所以MemStore中的数据会终写入到HFile中,也就是磁盘IO。由于HBase底层依靠HDFS,因此HFile都存储在HDFS之中。这便是整个HBase工作的原理简述。
基于HBase的系统设计与开发中,需要考虑的因素不同于关系型数据库,HBase模式本身很简单,但赋予你更多调整的空间,有一些模式写性能很好,但读取数据时表现不好,或者正好相反,类似传统数据库基于范式的OR建模,在实际项目中考虑HBase设计模式是,需要从以下几方面内容着手:
这个表应该有多少个列簇
列簇使用什么数据
每个列簇应有多少个列
列名应该是什么,尽管列名不必在建表时定义,但是读写数据时是需要的
单元应该存放什么数据
每个单元存储什么时间版本
行健结构是什么,应该包括什么信息
现如今各种数据存储方案层出不穷,本文结合两个实战场景就基于HBase的大数据存储做了简单的分析,并对HBase的原理做了简单的阐述。如何使用好HBase,甚至于如何选择一个优的数据存储方案,还需要根据场景需要具体分析和设计。
