在boltdb探秘系列的篇里介绍boltdb的基本使用,本文是boltdb探秘系列的第二篇,将对boltdb的存储格式以及索引结构进行分析,预计耗时7~8分钟。
玩DB,心里不能没点B+树
写时复制B+树
boltdb用B+树组织数据和索引,叶子节点存储数据,中间节点存储子节点。索引数据的时间复杂度为O(logN),由于中间节点存储足够多的Key,B+树整体深度不大,可以减少磁盘IO。
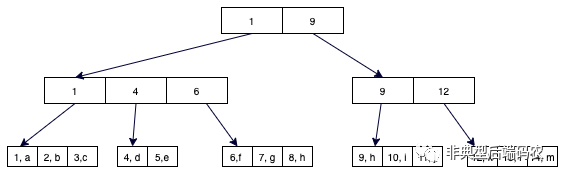
这里与常见B+树略微不同的是
1. 中间节点存储的是叶子节点的个Key。
2. 叶子结点没有形成链表,无法对顺序查找进行优化(boltdb也不支持顺序查找)。
写事务不会修改已有的树,而是对数据进行拷贝,在拷贝上修改。比如下图对叶子节点leaf 7修改,会先复制出leaf 8再进行修改,其父节点也随之复制。读写事务读到的是不同的数据版本。
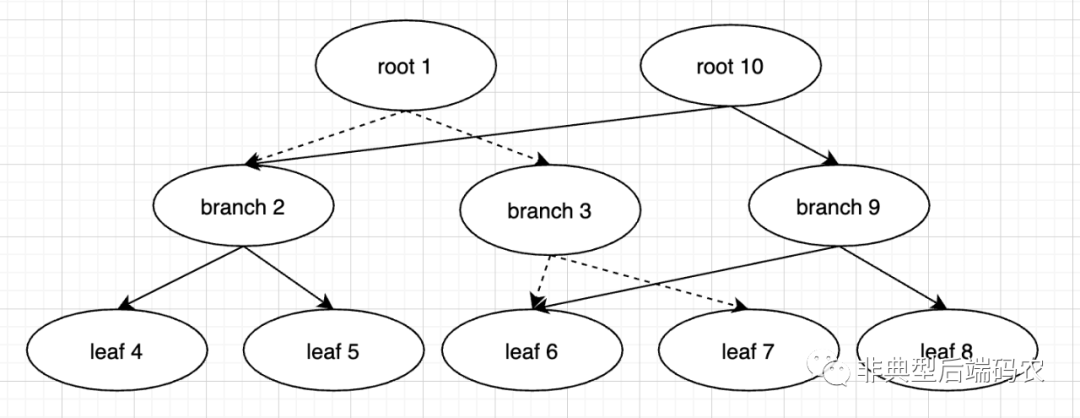
新增加的节点以追加的方式顺序写入db文件。
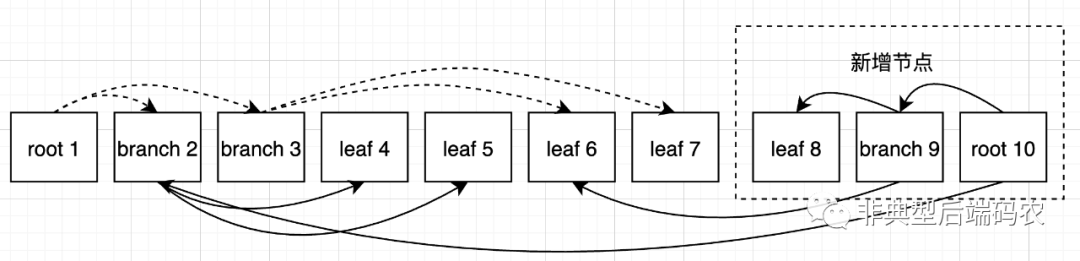
原则上每开启一个新的写事务都可以开启一个新版本。但boltdb规定任意时刻都只有一个写操作,这样可以避免垃圾回收带来的性能下降,且B+树优先使用被标记为空闲的块,而不是无限制的追加新的块。另外boltdb只维护两个版本的数据。
物理布局
数据库以meta页面为起点找到B+树的,从而找到数据。在写事务里从freelist分配页面,实现写时复制。
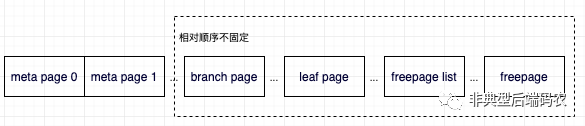
磁盘的page,内存的node
前文提到boltdb使用B+树来组织数据的,本节将介绍如何在数据库文件中存储这么一棵树,节点如何在磁盘文件和内存中表示B+树的节点。
页page
基本存储结构是页,结构体page的内存布局与文件中的存储格式相对应,且每个页面与操作系统的页大小一样,为4k(后面的文章会说明原因)。一个页分为页头(前16字节)和数据区。
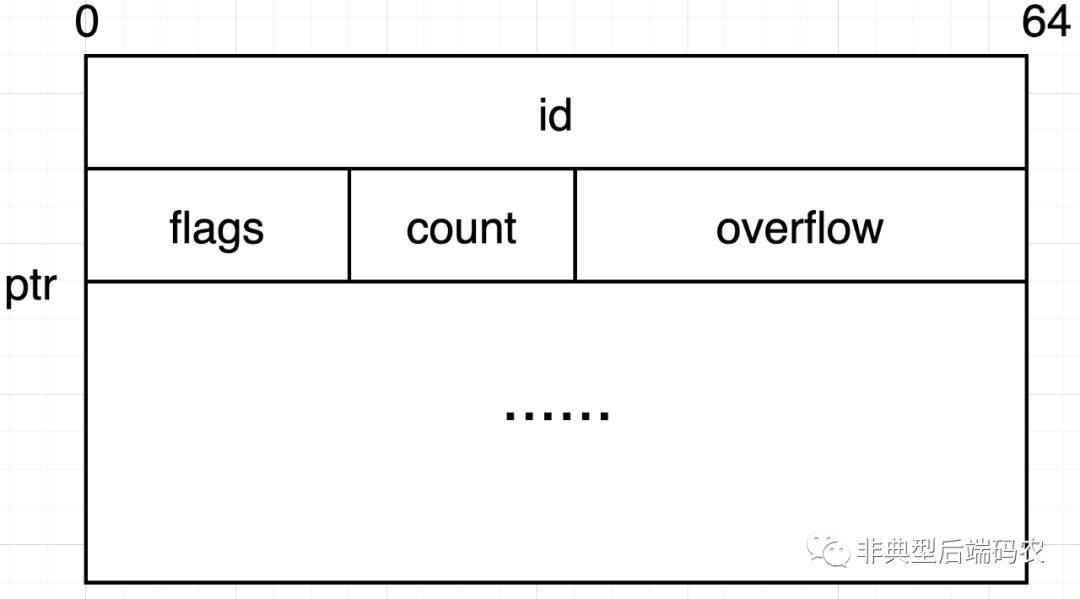
id(uint64): 页id,标识,从0开始递增。
flags(uint16): 标记页的类型,共有四种,分别是
metaPageFlag: db文件的元信息页,共有两份,在db文件的开头。
branchPageFlag: b+树中的中间节点。
leafPageFlag: b+树中的叶子节点。
freelistPageFlag: 空闲页列表,空闲页用于写数据时存储修改或新增的页。
count(uint16): 当数据区是存储具体的KV对数据时,表示该页存储的KV对的数量。
overflow(uint32): 数据溢出了多少页。当一个页面装不完数据(比如存储一个大小超过4k的字节数组时),需要再追加连续的几页来进行存储,这些溢出的页没有页头,全部用来存储数据。
ptr(uintptr): 指向数据区域。
B+树由叶子节点和中间节点组成,两者的区别在flags和数据区的分布上。
叶子节点(leafPage)主要存数据,以存储了(foo, bar)和(Tenz, Ok)两个KV对的叶子节点页面为例。
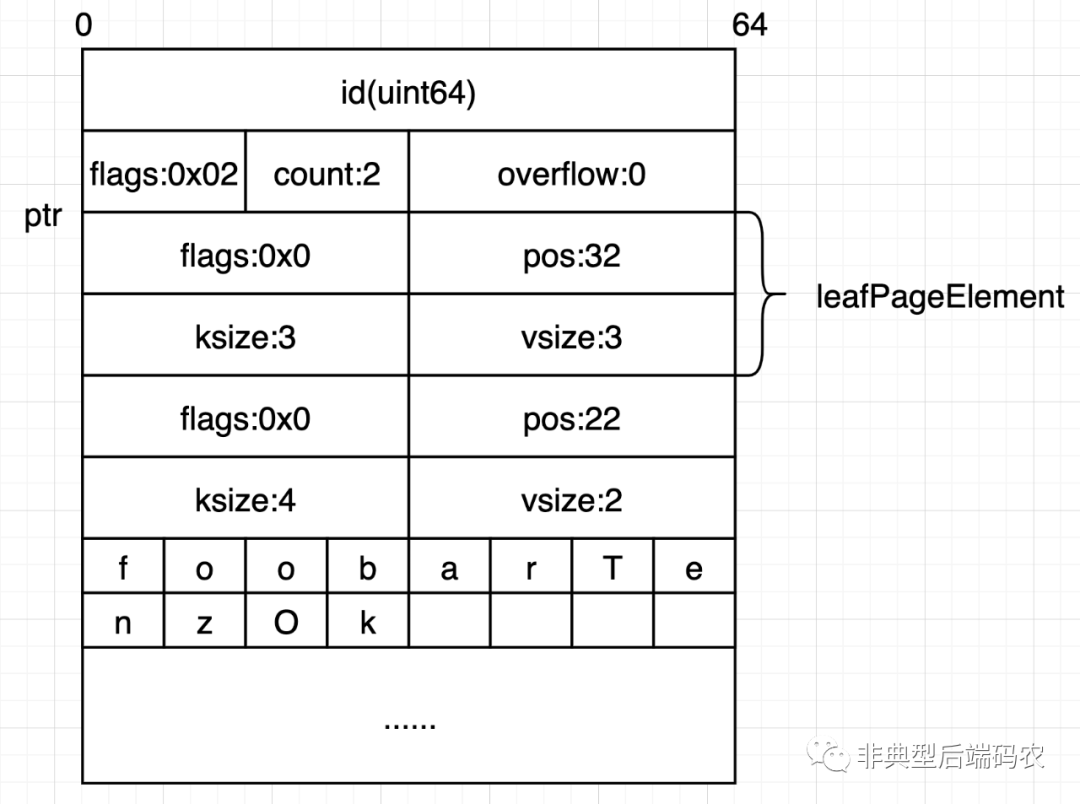
数据区域分为元素元数据列表(leafPageElement)和数据两个区域,数据区域是连续的字节数组。leafPage有几个字段:
flags: 标记位,0x0时为普通数据。
pos: position,表示从这个element的起点开始偏移pos个字节即可找到对应KV在数据区的位置。
ksize: KV对中Key的长度
vsize: KV对中Value的长度
中间节点(branchPage)记录key所在的页面。与叶子节点相似,分为元数据列表和数据区。不同的是,数据区只存Key的值,而元数据(branchPageElement)数据结构变成
type branchPageElement struct {pos uint32 // Key的偏移ksize uint32 // Key的长度pgid pgid // Key所在的页的id}
node与inode
如果直接在页面上进行数据操作,需要引入各种指针运算。为了方便操作,boltdb引入node和inodes两个数据结构,用于表示内存中“反序列化”的page,相当于利用node在内存中构建一棵B+树。
type node struct {bucket *Bucket // node所在的bucketisLeaf bool // 是否是叶子节点unbalanced bool // 子树是否平衡spilled bool // 是否在写事务中修改过数据key []byte // keypgid pgid // 对应页的idparent *node // 父节点children nodes // 子节点inodes inodes // KV对数组}
其中inode的数据结构为叶子节点页面数据区所有KV对反序列化的结果
type inode struct {flags uint32 // 标记位,0x0是数据pgid pgid // 所在页的idkey []byte // Keyvalue []byte // Value}复制
总结
boltdb使用B+树的方式组织数据,且使用写时拷贝B+树的方式实现写操作。B+树的每个节点都对应磁盘中的一个页,且页的大小与操作系统的页大小相等。为了在内存中更方便地读写数据,boltdb将page反序列化成node节点,在内存中构建一棵B+树。在后面的文章中会继续介绍如果利用这棵树进行读写。
