在上一篇小文中,提到了关于R语言导入数据的一些方法,之后的重点就转向了数据的处理上。数据处理其实在整个数据分析项目中所占用的时间是比较多的,所以根据处理的目的不同,也有不同的处理方法。在R语言中,我通常会将数据处理分成三部分:数据质量处理、数据维度处理和特殊文本的处理。由于三个部分的内容也比较多,就先介绍数据质量处理的内容,其余的两部分会在后面的文章介绍。
一、数据清洗
数据清洗简单说就是处理缺失值和异常值的判断,当然要根据实际情况来定义数据清洗的任务。
1.缺失值处理
当我们面对的数据是比较大量的时候,就需要了解数据集中那些变量有缺失值、缺失的数量、属于那种组合方式等有用信息。此时可以使用mice包中的md.pattern()函数,该函数可生成一个以矩阵或者数据框形式展示缺失值模式的表格,且该函数只需要传入需要判断的数据即可。另外还有使用图形方法这种更直观的方法描述数据的缺失,可利用VIM包中的aggr()函数实现,形式如下:
aggr(x,delimiter = NULL,plot = T,...)
x表示一个向量、矩阵或者数据框,delimiter用于区分插值补量,plot则指明是否画图。
识别出数据中的缺失值,接下来对其处理。常用的方法是将包含缺失值的记录删去,使用na.omit()函数,但仅限于出现缺失值的记录数量比较少。但含缺失值的记录很多时,就要考虑替换缺失值,一般可用均值、中位数和平均数替换,更专业一点的做法是使用插值法(将缺失数据的变量作为因变量,其他变量作为自变量,建立预测模型)
2.异常值的判断与处理
异常值处理的重点在于识别,处理的手段和缺失值基本一致,所以下面主要介绍识别异常值的一些方法。3σ原则是使用比较多的方法,而R语言qc包中的qcc()函数是专业绘制质量监控图的。初次之外,还可以利用箱线图和聚类分析识别出异常值。
二、数据去重
数据去重并不是处理数据的必要步骤,所以单独拿出来说。在R语言中去重的方法也很简单,对于向量数据可使用unique()函数,而针对矩阵或者数据框这种多维数据时,可使用duplicated()函数。
三、数据转换
数据转换的内容简单地可分为三部分,产生衍生变量、数据分箱和数据标注化。衍生变量就是原有的变量属性构造新的属性,比如变量A和变量B通过相乘得到变量C,另外比较常见的就是哑变量的构成(可以使用caret包的dummyVars()函数)。
数据分箱实际上就是按照属性值划分子区间,比如将考试成绩0-59分的归为不及格,60-89的归为中等,90-100的归为。R语言中分cut()函数可以实现数据分箱的目的。
数据标准化主要的目的就是消除变量之间的量纲影响,让不同的变量经过标准化后可以有平等分析和比较的基础。常用的标准化有两种,Min-Max标准化和Z-Score标准化,而caret包中的preProcess()函数能非常灵活地实现数据的标注化。
四、数据抽样
在数据分析或者建立数据模型之前,在面对或多或少的数据时,一般不会直接使用数据,而是采用抽样的方法去选取数据,而根据不同的情况,会有不同的抽样方法。下面介绍四种抽样方法及其在R语言中的实现:
- 处理类失衡的抽样方法——SMOTE
类失衡会发生在包含分类变量的数据集,比如在整个数据集中,A类的数据占总体的5%,而B类数据占了95%。具体的理论可参考下面的连接:
SMOTE算法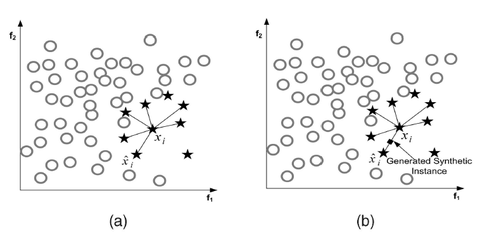
现在我们的关键在于如何使用R语言去解决类失衡的情况,比如A类数据有4000条记录,B类数据只有200条记录,此时可以使用DMwR包中的SMOTE()函数。
2.随机抽样
R语言中实现随机抽样的函数是sample(),基本形式如下:
sample(x,size,replace=F/T,prob=NULL)
x是数值型向量,size是抽样个数,replace表示是否放回,prob是与x长度一致的向量,且每个元素表示与x对应位置上的元素被抽中的概率。

如上面的命令,在1到5中随机抽取3个元素,且每个元素被抽中的概率为0.1、0.2、0.5、0.4和0.3。
3.等比抽样
当面对多分类数据时,我们会采用等比抽样的方法,实现快速得到与原始数据集有比例关系的抽样数据。R语言中实现这一功能的是caret包中的createDataPartition()函数,形式如下:
createDataPartition(x,time,p,list=F/T,groups = min(5,length(x)))
x是包含了多分类信息的向量,time表示需要进行抽样的次数,p表示需要从数据中抽取的样本比例,list表示结果是否是为list形式,默认为T,groups表示如果输出变量是数值型数据,则默认按分位数分组进行取样。以iris数据集为例,使用str()函数查看iris数据集的构成:

可以知道iris数据集中的Species变量是分类变量,且有3类元素。使用createDataPartition()函数进行抽样。

从结果可以看到三类的数据量是一样的。
4.交叉验证的样本抽取
如果我们在建立模型时只采用一次抽样的数据,这样得到的数据模型随机性和误差性是比较大的,因此使用N折交叉验证的方法可以提高模型结果的可靠性。步骤大概是将数据集的每条记录分配下标1,2,...N个数据,换言之就是将数据集分成了N份,然后,每次提取一份作为测试数据集,剩下的N-1份数据作为训练数据集,然后记录下拟合的N个模型结果和误差,后计算平均误差来衡量模型的准确性。对K折交叉验证法原理不熟悉的伙伴,可以看以下的连接:
K折交叉验证R语言中实现K折交叉验证法,主要是使用caret包中的createFolds()和createMultiFolds()两个函数。两者的形式别如下:
createFolds(x,k=10,list = T,returnTrain = F)
x是要依据分类的变量,k指指定的折数,默认是10,list表示返回的结果索引值是否为列表形式,默认为True,returnTrain表示是否返回抽样的真实值,默认Flase。
createMultiFolds(x,k = 10,times = 5)
x和k的参数意义与createFolds()一样,times为指定抽样组数。
两个函数都可是实现K折交叉验证的抽样,具体的使用方法可参照下面的连接:
k折交叉验证(R语言)
