来源:cnblogs.com/spareyaya/p/15878771.html
# 背景
产品上线后,出于运营的需要,我们要对用户进行跟踪,分析用户数据。本文要介绍的是如何统计用户新增数、活跃数和留存率,时间跨度是天,即统计每日新增(DNU),日活(DAU)和某日新增的一批用户在接下来的一段时间内每天活跃的百分比。
# 使用范围
本方案适用于用户量不太大(日活在百万以内,日活百万以上不是不能用,只是在统计数据时耗时太长不太合适),尤其适合小团队或个人开发者(比如你公司服务端接口开发是你,运维也是你,现在老板又来叫你做数据报表)。如果你的产品的日活有几百万甚至几千万或过亿,这样的产品当然是完全可以养一个大数据部门的,本方案并不适用这种情况。
# 涉及到的工具和技术点
shell脚本
本方案需要你懂一点儿shell,起码能看懂,也要求你知道怎么写crontab定时任务。
MySQL
本方案需要你熟练使用sql,知道怎么定义存储过程,知道分区表的概念和用法。
# 实现过程
1.目标
由于数据量是不断增加的,所以我们的目标是要把原始数据聚合成一张可以直接用一条select语句就可以查看每日新增、日活和留存率的表,并且只能做单表查询,否则当数据量增大时,联表查询的速度会大大下降。而且为了防止出错,我们的数据还需要可以重跑但是不会影响到已存在的数据。
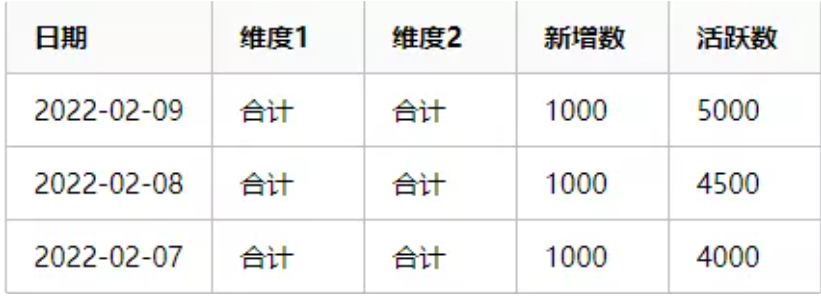
终呈现给运营人员看到的数据是这样的:
新增-活跃表
用户留存表
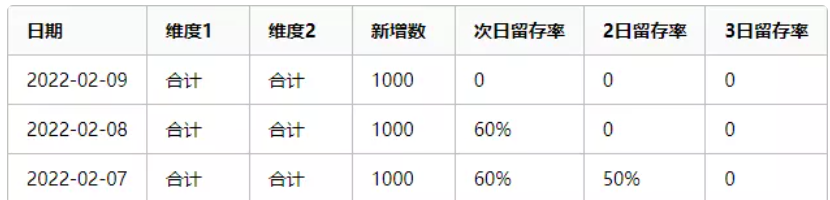
简单解释一下上面两个表的结构:因为我们是按天统计的,所以日期都是以天为单位,用户可能有不同的国家或地区,不同版本,不同手机型号等等,所以就有了各个维度。用户留存表的数据要注意,比如今天是2022年2月9日,那么就只能统计到9号的新增,9号新增用户的日次留存是10号才能统计到的,但是8号新增用户的次日留存在今天(也就是9号)就统计出来了,所以留存的数据是一个阶梯形状的。
2.收集数据
为了方便介绍本方案,这里假设只有日期、国家、版本号三个维度。
收集数据的下一步是数据入库,为了方便,需要把数据格式进行转换。因为服务端接口现在一般都是使用json格式的数据进行通信,如果直接把json格式的数据输出到日志文件,处理起来会非常麻烦,所以需要在服务端接收到统计日志时,把数据输出到单独的日志文件中,还要按照MySQL的load命令可以识别的数据格式。
在输出日志之前,先确定好都需要哪些数据,这里需要的数据如下:
ts:timestamp,时间戳。服务端接收到日志的时间,格式是yyyy-MM-DD HH:mm:ss。
device_id:设备id,这里是用来标识用户的一个字符串,比如在android设备上可以用android id,总之这个字段是用来确定一台设备的,要保证不同的设备设备id不同。
country:用户所在的国家。如果你是只做一个国家的,比如只做国内市场,也可以把这个字段换成省份或者城市,总之根据运营需求去改变。
version:应用版本号,一般是一个整数。
于是就可以确定日志的格式如下:
2022-02-09 13:14:15||aaaaaa||CN||1002022-02-09 13:14:16||bbbbbb||US||1002022-02-09 13:14:17||cccccc||NL||100也就是一条数据占一行,字段之间使用双竖线分隔,当然这里不一定是双竖线分隔,也可以换成其它的,原则是字符数少而且不能被字段的值包含,不然在数据入库时会出现字段不对应的问题。
再考虑两个方面:
如果数据量较大要怎么处理?
可能有的字段的长度没法一下子确定怎么处理?
保留数据的策略应该怎样设置?
第1个问题,当数据量大时,可以考虑把日志文件切割成更小的时间段,比如每小时一个日志文件,然后下一小时就把上一个小时的数据入库。
第2个问题,原始数据表的字段长度定义得大一些,做到即使以后字段有变化,也可以适应。
第3个问题,因为我们的目标是跑出后的报表,所以不可能一直保存着所有的原始日志数据,为了防止出错,可能只是保留近几天的,一个简单的策略是在每次日志数据入库前用delete语句把前几天的数据删除了,但是直接使用delete有两个问题:一是MySQL要扫描全表删除数据,比较耗时;二是MySQL的delete + where删除可能只是假删除,磁盘不会立即释放。
所以这里使用分区表来实现,每天的数据作为一个分区,删除数据时直接删除分区,数据入库时先创建分区。
于是得到原始数据表的DDL如下:
CREATE TABLE `st_base` ( `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'ID', `dd` int(11) NOT NULL DEFAULT '0' COMMENT '天数,格式是yyyyMMddHH', `ts` varchar(64) COLLATE utf8_bin NOT NULL DEFAULT '' COMMENT '时间戳', `device_id` varchar(64) COLLATE utf8_bin NOT NULL DEFAULT '' COMMENT '设备id', `country` varchar(64) COLLATE utf8_bin NOT NULL DEFAULT '' COMMENT '国家', `version` varchar(64) COLLATE utf8_bin NOT NULL DEFAULT '' COMMENT '版本号', PRIMARY KEY (`id`,`dd`)) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin COMMENT='原始数据表'/*!50100 PARTITION BY LIST (dd)(PARTITION p20220209 VALUES IN (20220209) ENGINE = InnoDB) */3.数据入库
有了格式化的日志文件和数据表,就可以通过shell脚本把数据入库了。步骤如下:
删除历史日志的分区
删除执行日期的分区(这一步在重跑数据很有用)
创建执行日期的分区
使用MySQL的load命令把数据从日志文件加载到数据库中
这里只说一下重要的命令:
1,删除和创建分区可以分别使用下面两个命令:
drop_sql="alter table st_base drop partition pxxxxxxxx" # 这里的xxxxxxxx要根据执行日期转换一下add_sql="alter table st_base add partition (partition pxxxxxxxx values in (xxxxxxxx) engine=innodb)"
mysql -u${username} -p${password} -D${database} -e "${drop_sql}"
mysql -u${username} -p${password} -D${database} -e "${add_sql}"上面使用mysql命令指定了用户名、密码、数据库名和sql语句(-e参数)
2.从文件加载数据入库
log_file=xxxx #日志文件名dd=xxxxxxxx #执行日期load_sql="load data local infile '${log_file}' ignore into table st_base fields terminated by '||' lines terminated by '\n' (ts,device_id,country,version) set dd='${dd}'"mysql -u${username} -p${password} -D${database} -e "${load_sql}"3.定时任务
因为我们是每天入库一次,所以可以在每天的0时10分去跑上面的脚本任务。假设上面的脚本文件保存为st_base.sh
可以通过crontab -e编辑定时任务:
10 * * * /path/to/job/st_base.sh当然好的做法是把执行日期当做脚本的参数传入,这样可以实现重跑某天的数据了。
4.清洗数据
在上一步得到了原始数据之后,接下来的工作都可以在MySQL中完成,首先要清洗数据。
这一步的目的有两个:
确定好数据类型
数据去重
先创建一个临时表tmp_base,这个表用来转换数据类型,如果有一些字段的值需要转换的也可以在这里做(举个例子:假如客户端获取到的国家有几种途径,分别是获取了sim卡国家,网络国家,手机国家,到了服务端后服务器根据客户端的ip也解析出了一个国家,但是运营的时候可能只需要一个接近用户的真实国家,那么就可以按照优先级来确定,当然本文没有多个国家的问题),DDL如下:
CREATE TABLE `tmp_base` ( `id` int(11) NOT NULL AUTO_INCREMENT COMMENT 'ID', `dt` date NOT NULL COMMENT '日期', `device_id` varchar(32) COLLATE utf8_bin NOT NULL DEFAULT '' COMMENT '设备id', `country` varchar(8) COLLATE utf8_bin DEFAULT NULL, `version` int(11) NOT NULL DEFAULT '0' COMMENT '版本号', PRIMARY KEY (`id`)) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin COMMENT='用户基础临时表'再创建一个用户总表total_base,这个表用来存放所有用户的数据,每个用户只有一条数据,DDL如下:
CREATE TABLE `total_base` ( `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'ID', `dt` date NOT NULL COMMENT '新增日期', `device_id` varchar(32) COLLATE utf8_bin NOT NULL DEFAULT '' COMMENT '设备id', `country` varchar(8) COLLATE utf8_bin DEFAULT NULL, `version` int(11) NOT NULL DEFAULT '0' COMMENT '版本号', PRIMARY KEY (`id`), UNIQUE KEY `device` (`device_id`)) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin COMMENT='用户总表';创建一个流水表flow_base,同样以日期作为分区字段,DDL如下:
CREATE TABLE `flow_base` ( `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'ID', `dt` date NOT NULL DEFAULT '2022-01-01' COMMENT '日期', `device_id` varchar(32) COLLATE utf8_bin NOT NULL DEFAULT '' COMMENT '设备id', `country` varchar(8) COLLATE utf8_bin DEFAULT NULL, `version` int(11) NOT NULL DEFAULT '0' COMMENT '版本号', `rdt` date NOT NULL DEFAULT '2022-01-01' COMMENT '用户注册日期', `dd` int(11) NOT NULL DEFAULT '0' COMMENT '日期(yyyyMMdd),用来做分区', PRIMARY KEY (`id`,`dd`), UNIQUE KEY `unique` (`dt`,`device_id`,`dd`)) ENGINE=InnoDB CHARSET=utf8 COLLATE=utf8_bin COMMENT='用户基础流水表'/*!50100 PARTITION BY LIST (dd)(PARTITION p20220209 VALUES IN (20220209) ENGINE = InnoDB) */注意到流水表flow_base中有一个rdt的字段,这字段是用来存放这个用户的注册日期,方便后面统计留存使用的。
准备好表结构之后,开始清洗数据。清洗数据使用MySQL的存储过程功能,创建一个存储过程sp_data_cleaning,在这个存储过程中,需要做以下几件事:
把原始数据表st_base中的数据清洗到临时表tmp_base,如果有字段的值需要转换也在这一步做。
把临时表tmp_base中的用户添加到用户总表total_base中。
把临时表tmp_base中的数据添加到流水表中,并且联合用户总表,把用户的注册日期也填充好。
于是可以得到存储过程sp_data_cleaning的DDL如下:
CREATE PROCEDURE `sp_data_cleaning`(IN v_dt VARCHAR(10))BEGIN # 变量 declare pname varchar(10); declare v_is_pname_exists int; # 清除tmp_base表数据 truncate table tmp_base;
# 清洗数据 insert into tmp_base( `dt`, `device_id`, `country`, `version` ) select v_dt, `device_id`, `country`, `version` from `st_base` where `dd` = replace(v_dt,'-',''); # 数据加入用户总表 insert ignore into total_base( `dt`, `device_id`, `country`, `version` ) select `dt`, `device_id`, `country`, `version` from tmp_base; # 给流水表创建分区 select concat('p', replace(v_dt, '-', '')) into pname; # 查找是否已经存在执行日期的分区 select max(a) into v_is_pname_exists from ( select 1 as a from information_schema.PARTITIONS where `TABLE_SCHEMA` = 'your_database_name' and `TABLE_NAME` = 'flow_base' and `PARTITION_NAME`=pname union all select ) t; # 如果已经存在先删除 if v_is_pname_exists=1 then set @drop_sql=concat('alter table flow_base drop partition ', pname); prepare stmt from @drop_sql; execute stmt; deallocate prepare stmt; end if;
# 创建分区 set @add_sql=concat('alter table flow_base add partition (partition ', pname, ' values in (', v_date, ') ENGINE = InnoDB)'); prepare stmt from @add_sql; execute stmt; deallocate prepare stmt;
# 数据加入流水表 insert ignore into flow_base( `dt`, `device_id`, `country`, `version`, `rdt`, `dd` ) select v_dt, t1.`device_id`, t1.`country`, t1.`version`, t2.`dt`, replace(v_dt, '-', '') from tmp_base t1 left outer join total_base t2 on (t1.`device_id`=t2.`device_id`);END五、数据聚合
经过上面几个步骤的处理,现在已经得到了半成品的数据,可以进行聚合了。根据步的目标报表,可以确定两个表的结构:一个是用户的新增-活跃表,另一个是用户的留存表,DDL如下:
新增-活跃表:
CREATE TABLE `rpt_base_active` ( `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'ID', `dt` date NOT NULL DEFAULT '2022-01-01' COMMENT '日期', `country` varchar(8) COLLATE utf8_bin DEFAULT NULL, `version` int(11) NOT NULL DEFAULT '0' COMMENT '版本号', `new_users` smallint(4) NOT NULL DEFAULT '0' COMMENT '新增数', `active_users` smallint(4) NOT NULL DEFAULT '0' COMMENT '活跃数', PRIMARY KEY (`id`), KEY `index1` (`dt`), KEY `index3` (`country`,`version`)) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin COMMENT='用户新增活跃表'用户留存表(这里假设只看7天的留存情况,如果需要看更多留存天数,可以自行修改):
CREATE TABLE `rpt_base` ( `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'ID', `dt` date NOT NULL DEFAULT '2022-01-01' COMMENT '日期', `country` varchar(8) COLLATE utf8_bin DEFAULT NULL, `version` int(11) NOT NULL DEFAULT '0' COMMENT '版本号', `d0` smallint(4) NOT NULL DEFAULT '0' COMMENT '新增数', `d1` smallint(4) NOT NULL DEFAULT '0' COMMENT '次日留存数', `d2` smallint(4) NOT NULL DEFAULT '0' COMMENT '2日留存数', `d3` smallint(4) NOT NULL DEFAULT '0' COMMENT '3日留存数', `d4` smallint(4) NOT NULL DEFAULT '0' COMMENT '4日留存数', `d5` smallint(4) NOT NULL DEFAULT '0' COMMENT '5日留存数', `d6` smallint(4) NOT NULL DEFAULT '0' COMMENT '6日留存数', `d7` smallint(4) NOT NULL DEFAULT '0' COMMENT '7日留存数', PRIMARY KEY (`id`), KEY `index1` (`dt`), KEY `index3` (`country`,`version`)) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin COMMENT='用户留存表'注意,以上两个表的索引创建并不是固定的,需要根据运营的实际情况去创建相关的索引。
在跑数据之前,先聚合一下执行日期的数据,创建一个临时表a_flow_base,这个表用来初步聚合数据,DDL如下:
CREATE TABLE `a_flow_base` ( `id` bigint(20) NOT NULL AUTO_INCREMENT COMMENT 'ID', `dt` date NOT NULL DEFAULT '2022-01-01' COMMENT '日期', `country` varchar(8) COLLATE utf8_bin DEFAULT NULL, `version` int(11) NOT NULL DEFAULT '0' COMMENT '应用版本号', `rdt` date NOT NULL DEFAULT '2022-01-01' COMMENT '用户注册日期', `rdays` smallint(4) NOT NULL DEFAULT '0' COMMENT '留存天数', `users` smallint(4) NOT NULL DEFAULT '0' COMMENT '用户数', PRIMARY KEY (`id`)) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin COMMENT='用户基础数据聚合表'首先初步聚合用户数据,创建一个存储过程sp_a_flow_base,DDL如下:
CREATE PROCEDURE `sp_a_flow_base`(in v_dt char(10))BEGIN declare d0 date; declare d1 date; declare d2 date; declare d3 date; declare d4 date; declare d5 date; declare d6 date; declare d7 date; select date_sub(v_dt, interval day) into d0; select date_sub(v_dt, interval 1 day) into d1; select date_sub(v_dt, interval 2 day) into d2; select date_sub(v_dt, interval 3 day) into d3; select date_sub(v_dt, interval 4 day) into d4; select date_sub(v_dt, interval 5 day) into d5; select date_sub(v_dt, interval 6 day) into d6; select date_sub(v_dt, interval 7 day) into d7; # 清除a_flow_base表数据 truncate table a_flow_base; insert into a_flow_base( `dt`, `country`, `version_code`, `rdt`, `rdays`, `users` ) select t1.`dt`, t1.`country`, t1.`version`, t1.`rdt`, datediff(t1.`dt`, t1.`rdt`) as rdays, count(*) as users from flow_base t1 where t1.`dt` in (d0,d1,d2,d3,d4,d5,d6,d7) group by t1.`dt`, t1.`country`, t1.`version`, t1.`rdt`;END初步聚合了数据后,开始正式聚合数据,创建一个存储过程sp_rpt_base,DDL如下:
CREATE PROCEDURE `sp_rpt_base`(in v_dt char(10))BEGIN declare d0 date; declare d1 date; declare d2 date; declare d3 date; declare d4 date; declare d5 date; declare d6 date; declare d7 date; select date_sub(v_dt, interval day) into d0; select date_sub(v_dt, interval 1 day) into d1; select date_sub(v_dt, interval 2 day) into d2; select date_sub(v_dt, interval 3 day) into d3; select date_sub(v_dt, interval 4 day) into d4; select date_sub(v_dt, interval 5 day) into d5; select date_sub(v_dt, interval 6 day) into d6; select date_sub(v_dt, interval 7 day) into d7; # 删除数据 delete from rpt_base_active where `dt` = v_dt; insert into rpt_base_active ( `dt`, `country`, `version`, `new_users`, `active_users` ) select `dt`, `country`, `version`, sum(if(`dt`=`rdt`, 1, )) as `new_users`, sum(1) as `active_users` from flow_base where dt=v_dt group by `dt`, `country`, `version` ;
# 删除数据 delete from rpt_base where `dt` in (d0,d1,d2,d3,d4,d5,d6,d7); insert into rpt_base( `dt`, `country`, `version`, `d0`, `d1`, `d2`, `d3`, `d4`, `d5`, `d6`, `d7` ) select t1.`rdt`, t1.`country`, t1.`version`, sum(case when t1.`rdays`= then t1.`users` else end) as d, sum(case when t1.`rdays`=1 then t1.`users` else end) as d1, sum(case when t1.`rdays`=2 then t1.`users` else end) as d2, sum(case when t1.`rdays`=3 then t1.`users` else end) as d3, sum(case when t1.`rdays`=4 then t1.`users` else end) as d4, sum(case when t1.`rdays`=5 then t1.`users` else end) as d5, sum(case when t1.`rdays`=6 then t1.`users` else end) as d6, sum(case when t1.`rdays`=7 then t1.`users` else end) as d7 from a_flow_base t1 group by t1.`rdt`, t1.`country`, t1.`version` ; END为了方便调用整个过程,可以再创建一个存储过程,把全过程写在一起,一次执行。创建一个存储过程sp_user,DDL如下:
CREATE PROCEDURE `sp_user`(in v_dt char(10))BEGIN
call sp_tmp_base(v_dt); call sp_data_cleaning(v_dt); call sp_a_flow_base(v_dt); call sp_rpt_base(v_dt); END这样,就可以添加定时任务每天定时跑前一天的数据了。
# 写在后
流水表flow_base应该保留几天的数据?
这个看你的用户留存表需要看多少天留存数据,如果你要看7日留存,那么保留近8天的数据,如果是想看30天留存,就保留近31天的数据,依次类推。
如果运营人员或老板9点半上班,每天凌晨的0点开始跑前一天的数据,你将有9个半小时来跑前一天的数据。当然如果一天的数据要跑2个小时以上,还是考虑用Hadoop来做吧。
