导读
背景
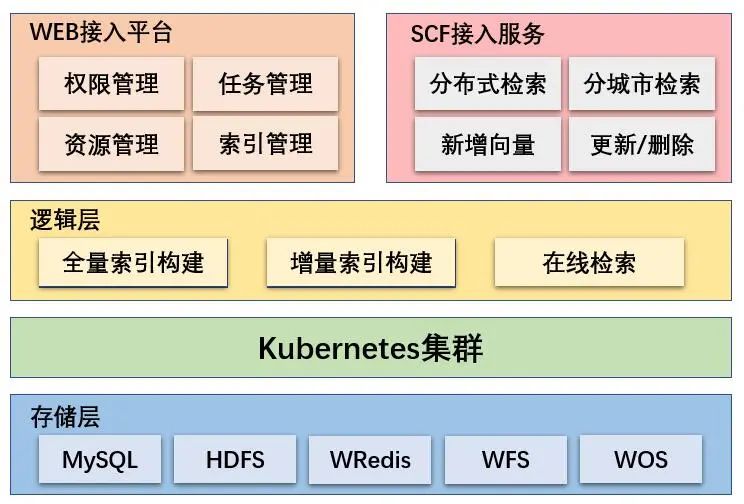
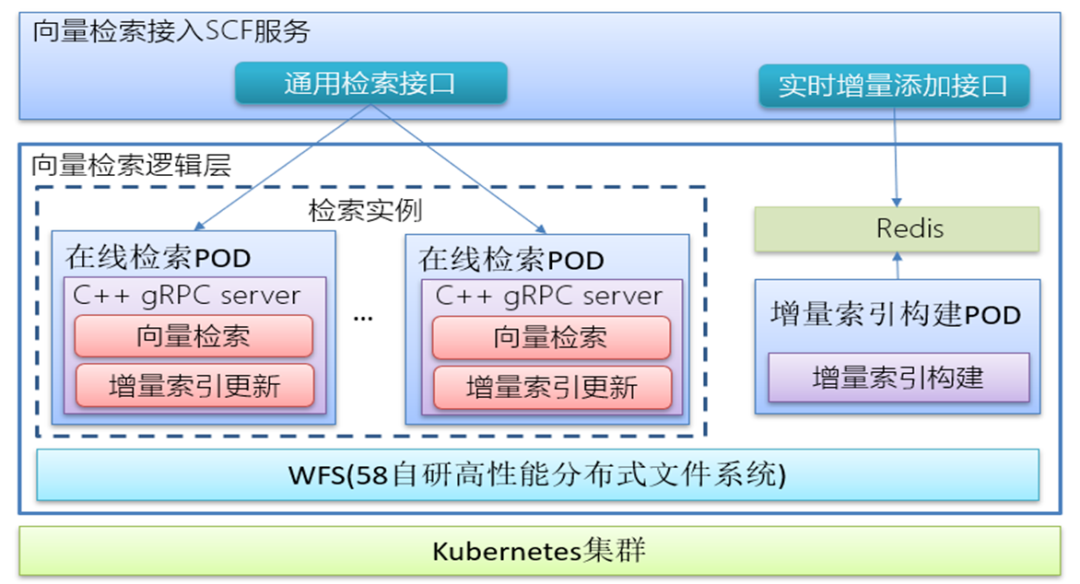
整体架构
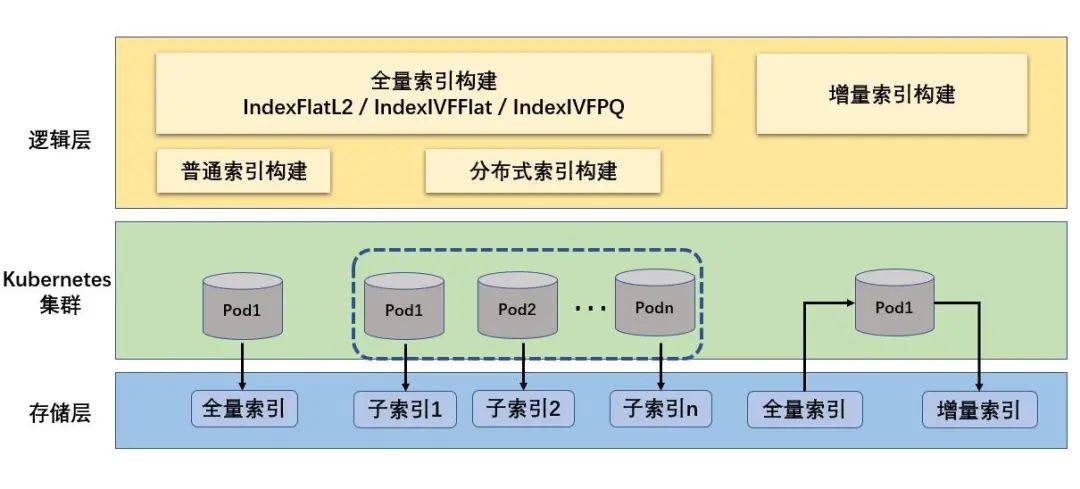
索引构建
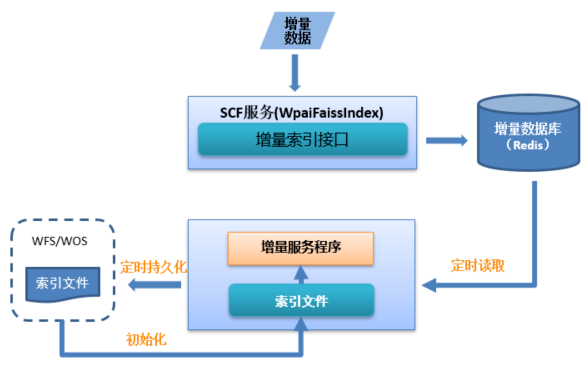
增量索引构建
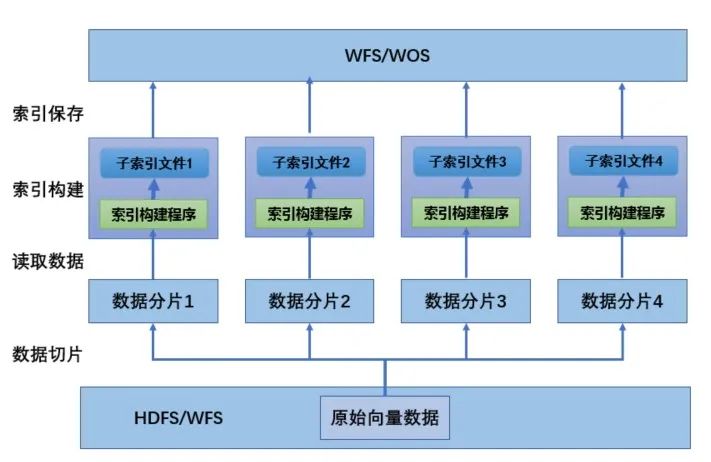
分布式索引构建
在线检索
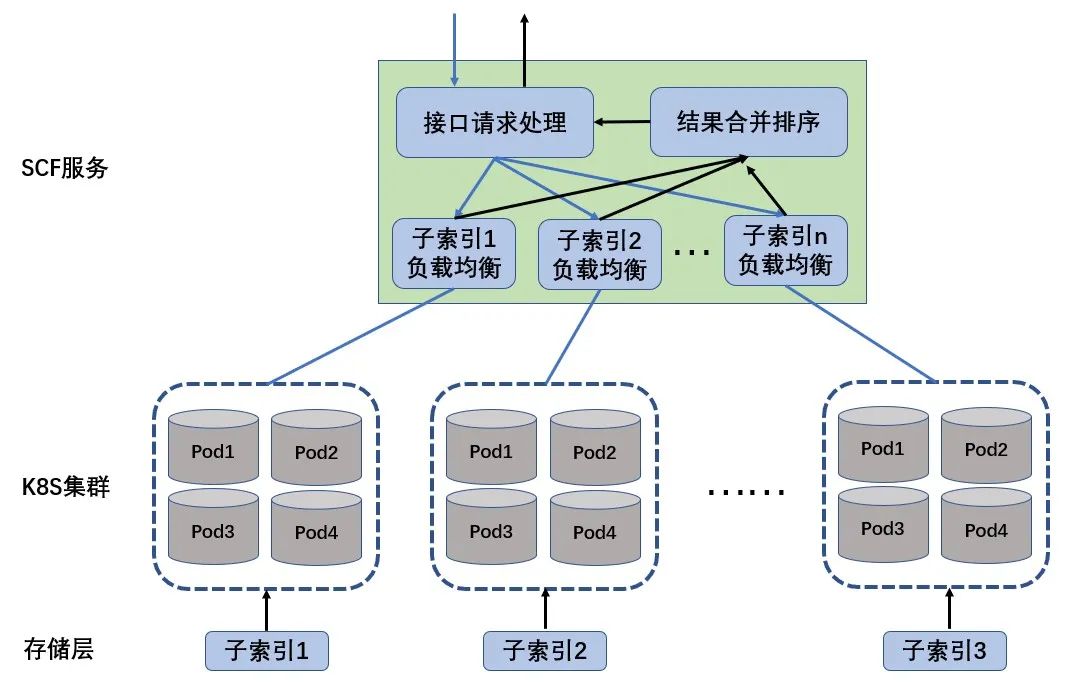
分布式检索
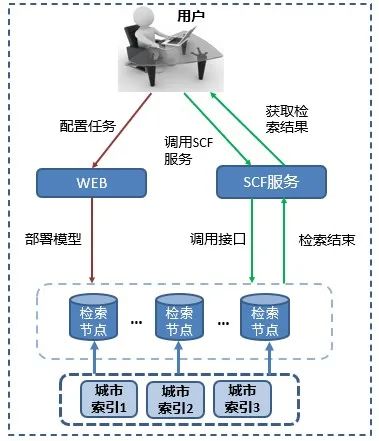
分城市检索
向量更新和删除
总结
继续集成更丰富的检索模型,进一步提高召回率及检索效率 提供更加便捷的调试排查功能 提供更多的算法库支持
导读
背景
整体架构
索引构建
在线检索
总结
分享这个小栈给你的朋友们,一起进步吧。
• 所有用户可根据关注领域订阅专区或所有专区
• 付费订阅:虚拟交易,一经交易不退款;若特殊情况,可3日内客服咨询
• 专区发布评论属默认订阅所评论专区(除付费小栈外)
