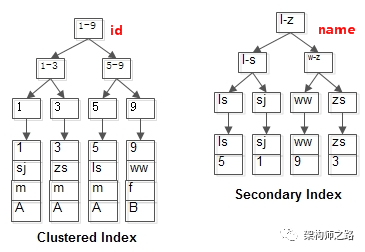
1, shenjian, m, A
3, zhangsan, m, A
5, lisi, m, A
9, wangwu, f, B
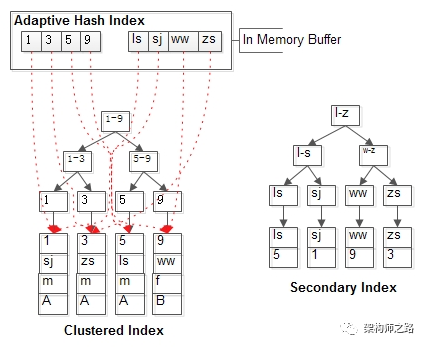
(1)很多单行记录查询(例如passport,用户中心等业务);
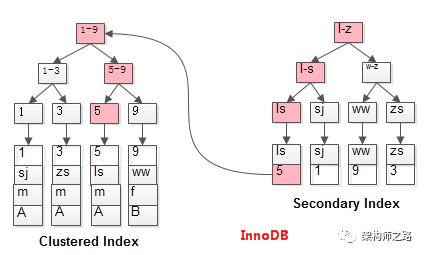
(2)索引范围查询(此时AHI可以快速定位首行记录);
(3)所有记录内存能放得下;
一个小知识点,希望对大家有帮助。
知其然,知其所以然。
原文链接:https://mp.weixin.qq.com/s/C0KZ46TYylnIbDuv3FsaeQ
1, shenjian, m, A
3, zhangsan, m, A
5, lisi, m, A
9, wangwu, f, B
(1)很多单行记录查询(例如passport,用户中心等业务);
(2)索引范围查询(此时AHI可以快速定位首行记录);
(3)所有记录内存能放得下;
原文链接:https://mp.weixin.qq.com/s/C0KZ46TYylnIbDuv3FsaeQ
分享这个小栈给你的朋友们,一起进步吧。
• 所有用户可根据关注领域订阅专区或所有专区
• 付费订阅:虚拟交易,一经交易不退款;若特殊情况,可3日内客服咨询
• 专区发布评论属默认订阅所评论专区(除付费小栈外)
